人文情報学月報第97号
ISSN 2189-1621 / 2011年8月27日創刊
目次
- 《巻頭言》「もっと記述のことばを、あるいは『ネット文化資源の読み方・作り方』の長い後書き」
:国文学研究資料館古典籍共同研究事業センター - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第15回
「コプト語テクストの光学文字認識の開発」
:ゲッティンゲン大学 - 《連載》「Digital Japanese Studies 寸見」第53回
「「みんなで翻刻」、新バージョンの試験運用開始」
:国文学研究資料館古典籍共同研究事業センター - 人文情報学イベント関連カレンダー
- イベントレポート「18世紀研究における DH の広がり:第15回国際十八世紀学会(ISECS 2019)に参加して 第1回:個別発表にみるデータ可視化」
:お茶の水女子大学大学院人間文化創成科学研究科 - イベントレポート「DH2019体験記」
:東京大学大学院人文社会系研究科 - 編集後記
《巻頭言》「もっと記述のことばを、あるいは『ネット文化資源の読み方・作り方』の長い後書き」
2019年8月10日に拙著『ネット文化資源の読み方・作り方:図書館・自治体・研究者必携ガイド』が文学通信より刊行された[1]。この『人文情報学月報』で連載の機会をいただいている「Digital Japanese Studies 寸見」のなかから、2018年までに書いたものをまとめたものである。紹介したウェブサイトなどの編集時点のスクリーンショットの掲載、状況の変化に応じた付記や差し替え、用語解説などを行い、はじめて本書でこのようなものに触れる方はもちろん、本連載をメールマガジンでお読みいただいている方々にとっても価値のあるものにすべく編集者の岡田圭介氏のご協力のもと努力してみたが、いかがだろうか。
本書は、連載をまとめたものなので、特定の主題を追い求めるものではなく、またそのときどきの考えで言っていることがころころ変わっていたりもするが、基本的に心がけてきたのは、リソースの紹介・記述と批評である。デジタルサービスの単なる紹介であれば、当事者がやればよいが、記述と批評の場というものは、日本では海外事例の紹介でしかあまりお目にかかれない。そこで、その任に値するかはさておいて、取り組んでみたのがこの数年間ということになる。本としてまとめられることで、どのように受け止められるか、緊張しつつ楽しみでもある。
本書では、上記の付記類にくわえ、各回にブログ風のタグをつけ、同時に索引も備えた。索引もタグも似たようなものであるが、索引は詳細なものほど俯瞰性が落ちてしまう。とはいえ、検索ができないのが紙の書籍の弱みだから、索引そのものは必要である。そこで、手間はかかるけれども、両方つけることとした。タグをどのようにつけるかは、難しいところがあるが、最終的には、くわしい検索は索引があるわけなので、分野や注目点、担い手などを一覧できるのがよいだろうと考えた。そこで、一記事につきタグ5点を目安としてつけていくこととした。こうしてタグを付けておくことで、「はじめに」で見るべきタグのお勧めをしやすくなるというのも狙いであったが、編集者の岡田氏がタグマップというかたちに整理してくださり、各回の相関が一望できるようになった。結果的に、書籍のジャケットにも用いられ、どんな本か読者にも分かりやすくなってよかったのではないかと思う。索引についてはごく一般的な体裁をとったが、連載を進めるなかでどうしても統一しきれない名称の揺れなどの吸収に使えるという発見もあった。ぎゃくにいえば、揺れ具合に閉口したということでもあるが……。
連載の題名には「Digital Japanese Studies」を冠してきたが、実際の連載では、研究に関するものよりもデジタル化された資料を取り上げたものが結果的に多くなり、書籍では「ネット文化資源」という造語によって括ることとなった。もともとの題するところの「Japanese Studies」は、「日本学」とも「日本研究」とも取れ、とくに後者と考えれば、それは横断領域であって、日本に関することが主題であればそれに含まれると言うことができる。さらに、「Digital」となれば、デジタル的方法論に関するものも広く取り上げられることとなり、その結果として現在のような連載のありようになったわけである。とはいえ、学界時評ではないけれども、資料を見つめることは、研究にもっとも顕著に現れるわけで、それをどのように取り上げていくかは課題であろう。「あとがき」では鵺的のひとことで済ませてしまったものの、それによって「デジタル日本研究」の輪郭が立ち現れるのであれば、意味のあることであるように思われる(筆者より適任の方々も大勢いらっしゃると思うが)。
さて、さきほど本書で心がけてきたのが「記述」であると述べたが、記述を単なる紹介から区別する最大のものは、幅広い文脈のもとにその対象(デジタルリソースが多い)を置き、それに照らしてその対象の現状がどうあるか、巨細に書き留めていくことにある(本連載でそれが実現できているとはとても言えたものではないが)。他者の先行事例や検討例との関係を検討するのはもちろん、提供者のこれまでの活動における位置づけも可能なかぎり跡を辿るよう努めてきた。それによって、その対象が実現を目指したものの実現度や、目的の適正さを考える批評へと歩を進められるからである。デジタルリソースの利便性に触れることもあるが、それもまたデジタル人文学での長い歴史があって、適宜文脈として置かれるべきものであり、通販サイトの口コミのように、無根拠に書いてよいものではないはずである。つまり、これは決して本連載に独特なものではなく、学術的なレビューとして一般的なことであろう。それはすなわち、だれかひとりがやってお終いになることではなくて、もっと日常の公論として記述と批評がなされなければならないということだろう。記述と批評が公論となるためには、直接的であれ、間接的であれ、それに答える声が響くことが大事で、それにはまず、答えるに足る記述や批評を目指さねばならないということでもある。
公論としての健全さだけではない。いわゆる帯文には、「私たちが残すものは、私たちそのものだ」との文が載った。これは、「はじめに」に書いたことを踏まえたものではあるが、このことばを取り出してあらためて考えるに、時評を書くことは「残す私たち」について書くことであると言うことができるかもしれない。この文句そのものは、その後に意図せずして残されたものについて述べるように、記録を燃やしてしまえば私たちの不都合なことはなくなるといった意味では、もちろんない。なにをどのように残すかといったものも、残るものには含まれるからである[2]。そのようなものの扱いようを含めて、私たちが残すものは私たちそのものなのである。
また、私たちが残すものは、未来のひとびとがそこから作り、さらに伝えていく、かけがえのない取り分でもある。そもそも、天体としての地球が一秒一秒変化していくし、現代文明も崩れいく環境バランスのなか、いつ尽きるとも知れない埋蔵資源に依存しており、依存を抜け出すどころか、止まるところを知らない。このままゆけば、明日世界が破綻することはないにしても、50年後に自由にものを残すことは叶わないかもしれない。もっと卑近なところでは、今回確認した範囲内で、すでに閉鎖されていたサービスはなかったが(しかし、印刷所に入れて以降、本稿執筆時ですでにいくつかのリソースのリニューアルが発表されている)、1年後にはなんとも言えないわけである。そのとき、わずかでも記述が残ってゆけば、私たちのありようを後世に伝えることが可能になるわけである。そういう意味でも、いろいろなひとびとが、おのおのの大事にする視野から、デジタルなものを書き留めていくきっかけに本書がなれば、これに勝る幸いはないように思われるのである。
執筆者プロフィール
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第15回
「コプト語テクストの光学文字認識の開発」
ヨーロッパやイスラエルでは、現在様々なプロジェクトが、コプト文字のように市販の OCR ソフトウェアでは対応できないような文字、もしくは、古い時代の歴史的書体を機械に認識させ、デジタルに自動的に書き起す OCR の開発に携わっている。
OCR とは Optical Character Recognition(光学文字認識)の略であり、文献の文字を読み取り、コンピュータ上で書き起こす技術である。これに対して、近年ヨーロッパでは Transkribus を中心に HTR の開発が盛んである。 HTR とは Handwritten Text Recognition(手書きテクスト認識)の略である。OCR も後述するように手書き文字認識にも対応できるものの、HTR はレイアウトやリガチャーの認識など、OCR よりも手書きテクストに特化したものとなっている。今月号では OCR を中心に、来月号では HTR を中心に述べる。
筆者が参加しているプロジェクトの一つである KELLIA プロジェクトでは、18–20世紀に植字され印刷されたコプト語のテクストの OCR を開発している。最初に開発したのはニューラル・ネットワーク・モデルを用いた OCRopy(オクロパイ)[1]を用いたもので、これは、最新の研究では、スキャンの精度が良ければ、ほぼ90–100%の認識正答率を記録している。OCRopy は Thomas Breuel が開発した OCRopus(オクロパス)の Python 版である。コプト語に OCRopy を適用したのは、筆者、マックス・プランク生物物理化学研究所に勤めていたコンピュータ科学者である Kirill Bulert、そして、ゲッティンゲン大学コンピュータ科学研究所 eTRAP プロジェクトのリーダーである Marco Büchler である。この成果はデジタル・ヒューマニティーズの代表的な論文誌である Digital Scholarship in the Humanities の DH2017 Special Issue に掲載されることが確定している。 DOI は既に付与されており、DSH のウェブ版で既に閲覧することができる。紙版のページや号数はまだ確定されていない。
Miyagawa, So, Kirill Bulert, Marco Büchler, and Heike Behlmer. Forthcoming 2019. “Optical Character Recognition of Typeset Coptic Text with Neural Networks.” Digital Scholarship in the Humanities, DH2017 Special Issue. https://doi.org/10.1093/llc/fqz023.
ただし、この論文が提出されたのは2017年で編集者の諸事情もあり出版が2年越しになった。そのため、本論文は2015年からの研究の初期段階の成果であり、ニューラル・ネットワークを導入して正答率が格段に上がった Tesseract 4.0以降や OCRopus に TensorFlow を導入した Calamari など、新しい動きには触れられていない。
OCRopy を特定の言語の文字や書体に適応させるには、トレーニングが必要であり、そのトレーニングには、機械学習する OCR の「教科書」となるべきグラウンド・トゥルス(Ground Truth)が必要である。グラウンド・トゥルスとは、対象となる書籍の特定の数のページの画像とデジタル翻刻である。ユーザはまず、このグラウンド・トゥルスを用意しなければならない。
まず、コプト語のテクストをスキャンした画像は ScanTailor というフリーのソフトウェアで調整した。OCRopy では、画像を1行毎に切り出し行毎に入力できる HTML ファイルを生成できる。トレーニングでは、OCRopy がグラウンド・トゥルスの画像とテクストを見比べて、パターンマッチで、どの文字が画像のどの部分に対応するかを機械が自動で学習する。 筆者らは、OCRopy をゲッティンゲン大学コンピュータ科学研究所のハイパフォーマンス・コンピュータである ROEDEL において、全てのプロセスを行った。トレーニングの回数は30000回以上行った。図1はトレーニングを視覚化した画面である。
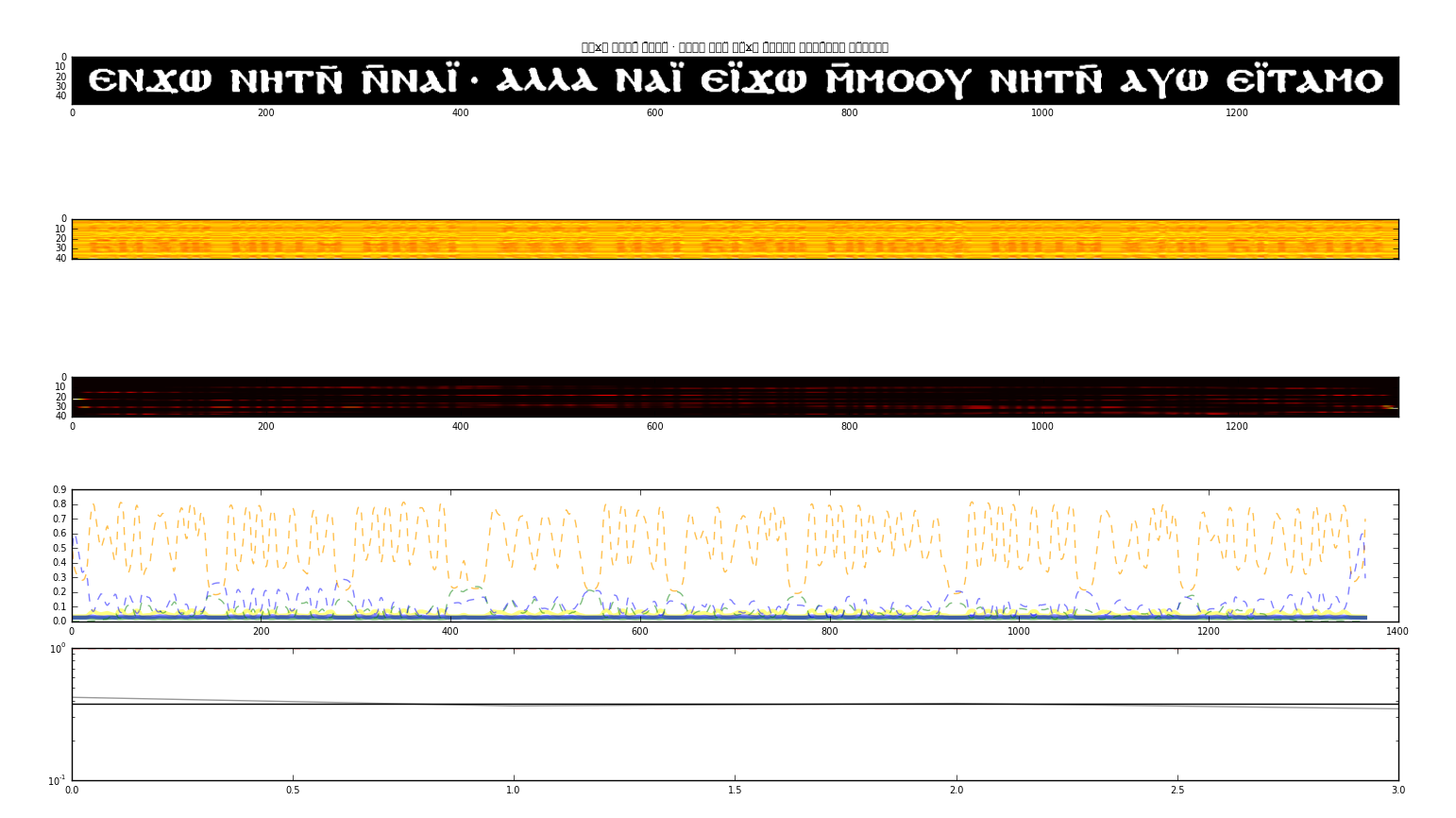
YouTube で、英語文献でのトレーニングを視覚化した映像も見ることができる(https://www.youtube.com/watch?v=czG5Jk9iC7c)。
あるコプト語文献のエディション[2]画像とテクストでトレーニングをして、同じ本でグラウンド・トゥルスには無いページで OCRopy の文字認識をかけた結果、毎回ほぼ90%以上の正答率で推移した。ページによっては98%を超えることもあった。結果は、紛らわしいが、グラウンド・トゥルスと同じ表示方法で表示する方法がもっとも見やすい。以下は、グラウンド・トゥルスには用いていない『シェヌーテ伝』というコプト語聖人伝のエディション[3]の p. 12を OCRopy で文字認識した一部であるが、誤りは一箇所のみである。

黒文字が元の本のページを行毎に切り抜いた画像で、青文字が OCR の認識した文字である。
このプロジェクトは、eTRAP チームの Marco Büchler が、インキュナブラなどラテン語歴史文書の OCR の専門家である Uwe Springmann のルートヴィヒ・マクシミリアン大学ミュンヘン(通称ミュンヘン大学)での OCR ワークショップを受け、この企画を思いついたことに始まる[4]。Büchler は筆者と Kirill Bulert に声をかけ3人で2016年の1月にミュンヘン大学の Uwe Springmann を訪れ、一日かけてコプト語 OCR のプロトタイプを完成させた。 その後、歴史文書の OCR および HTR を中心とする文献のデジタル化に関する学会である DATeCH、および、モントリオールで開催された DH2017での発表に向けてコプト語 OCR を一定の水準で完成させた。この間、ゲッティンゲン学術アカデミーのコプト語旧約聖書デジタル・エディション・プロジェクトとコプト語の言語学的コーパスを作っている全米人文学基金の Coptic SCRIPTORIUM に、開発した OCR を用いてコプト語文献のテクストを抽出し提供した。
ベルリン・フンボルト大学の Eliese-Sophia Lincke もこのワークショップを受け独自にコプト語 OCR を開発していたが、2018年、半年間ゲッティンゲンに滞在し、チームに加わった。現在 Lincke は OCRopy に TensorFlow を導入した Calamari をコプト語に試している。また、Tesseract もニューラル・ネットワークを導入し、正答率が格段に上がった。Kirill Bulert はまた、Tesseract の最新版(ヴァージョン4以降)を使って実験をしている。8世紀のコプト語手書き写本でも OCRopy を用いてトレーニングを行ったが、タイプセットのものよりは精度が落ちるものの、手書きにも対応できた。
以下は本稿に関連する OCR プログラムが入手できるページへのリンクである。
- OCRopy: https://github.com/tmbdev/ocropy
- Ocrocis:[5] http://cistern.cis.lmu.de/ocrocis/
- Calamari: https://github.com/Calamari-OCR/calamari
- Tesseract: https://github.com/tesseract-ocr/
次回は Transkribus を中心とした HTR について OCR と比較しながら述べる。
《連載》「Digital Japanese Studies 寸見」第53回
「「みんなで翻刻」、新バージョンの試験運用開始」
2019年7月22日、「みんなで翻刻」がリニューアルし、新バージョンの試験運用を開始した[1][2]。今回のリニューアルでは、設計が一から見直され、大幅な機能拡張が行われている。まだ試験運用段階ということで、不具合や未実装の機能もあり、開発者の橋本雄太氏が Twitter で随時報告を受け修正に当たっているさまが見られる[3]。また、旧版も当面アクセス可能であるとのことである[4]。
みんなで翻刻については、かつてリリース時に紹介したことがあるが[5]、2017年に東京大学地震研究所石本文庫所蔵の資料の翻刻を進めるためにはじめられて以来、多くの参加者に恵まれ、2019年3月にその資料の入力をひととおり終えている[6]。その後、2018年8月には「岩手県海岸巡回古文書拾集録」(遠野市立博物館蔵)、2019年4月には「山脇弁治日記」(秋田県公文書館蔵)が追加され、このほかにも追加時期が分らないながらいくつかの史料が追加されるなどしたが、これらも進捗著しく翻刻がほとんど完了している。その間にも、2017年2月に「あっぱれ」機能(Facebook でいうところの「いいね」)とフォーラム機能が追加され、また2018年には英語 UI が追加されるなど、機能改善が行われてきている。みんなで翻刻は、2017年度情報処理学会山下記念研究賞[7]や第12回野上紘子記念アート・ドキュメンテーション学会賞[8]、デジタルアーカイブ学会学会賞[9]を受賞するなど、高い評価を得ている。「みんなで翻刻」はもともと京都大学古地震研究会によって2017年にはじめられたものであるが、リニューアル版では国立歴史民俗博物館と東京大学地震研究所とが運営に加わっている。
今回のリニューアルでは、プロジェクト機能が実装され、これまでの地震史料(石本文庫)翻刻プロジェクトにくわえ、京都学・歴彩館所蔵の東寺百合文書[10]の入力プロジェクトが開始されている。東寺百合文書とみんなで翻刻については、2018年2月の東寺百合文書データミーティングでも議論されている[11]。東寺百合文書は、平安京の古刹・東寺に伝来した荘園文書で、100箱(合)に整理されたことからこの名がついた。中世日本を代表する文書群であり、すでに全点の電子化を終え、翻刻も明治以来進められてはいるが(東京大学史料編纂所編『大日本古文書 家わけ第十 東寺文書』や京都府立総合資料館編『東寺百合文書』など)、まだまだ大量の未翻刻文献が存在している。今回は、おそらくそのような未翻刻のものから二箱が選ばれて翻刻可能となっている。既存の翻刻も随時論考などで見直しがされているが、見直された結果がかならずしも普及しているとは言えないだろうことを考えると、修正とその参照が容易なプラットフォームでこのような重要な史料が翻刻されることは有益であろう。
さて、複数プロジェクトを同時に進められるようになった背景としては、そもそもの設計の見直しはもちろんだが、この連載でも何度か言及している IIIF を採用することで、画像の管理を外部化できたことが挙げられる。これにより、IIIF の形式で配信可能な画像はみんなで翻刻で取り込むことが可能になったわけである。プロジェクトの管理も、現在はみんなで翻刻運営本体が行っているものしかないが、今後の調整次第では、いろいろなプロジェクトが相乗り可能なシステムと変貌したことは喜ばしい。
このほかにも、いくつかの新機能が追加されている[12]。まず、これまでの翻刻の際の構文を捨てて、あらたに大きく外れない形で作成された Koji というマークアップ言語が採用されている[13]。既存の構文は、文法が十分に定義されておらず、少しの変更でも互換性を損なう可能性があるほか、その場その場の処理しかできなかったという問題があった。それに対して、今回の Koji は、解析表現文法ライブラリのひとつである peg.js の基盤のうえに整備されており、構文木を生成するものであるため、生成された木構造をそのまま転用してウェブでの表示に用いる HTML だけでなく、TEI などほかの木構造を持つフォーマットへの出力も容易になるとのことである。
そのほかには、さきにも述べた IIIF の機能を利用したものがふたつあり、まず、外部の「くずし字」認識サービスに画像の任意の一部を渡すことが可能となった。これは、凸版印刷で開発されたものと、CODH で開発されたものとのふたつから選べる。もうひとつは、部分翻刻で、画像の一部に対して翻刻を与えられる機能である。これまで、地図や挿し絵中の名称の記載など、本文をなすわけではない部分の翻刻もほかの部分と同様に翻刻するしかなく、一連のデータとして見たときにあまり望ましくないものを生み出していたことへの対処である。
「みんなで翻刻」は、参加者の自律性や匿名性が適度に担保され([6]の橋本氏博士論文第4章をとくに参照)、また協調的な学習機会も得られるということで、継続的な参加者を多く得られている。また、ドワンゴの「ニコニコ生放送」において、「みんなで翻刻」の番組を2017年に放送したのち、ニコニコ超会議にも2017年以降参加するなど、コミュニティとほどよい距離感を得られているようである。なかなかにわかに真似ができるものでもないが、非常に成功したデジタル人文学プロジェクトコミュニティと言ってよいだろう。
さきに TEI への言及をしたように、デジタル人文学としては、テキストデータをどのように扱うか、データマイニング的な方向からも、人文学的なテキストとしても、というところがいよいよ扱える問題として現れてくることが期待される。部分的なテキストをどのように扱うかは、どんな言語でも問題であるが、日本語圏でこのような議論をする土壌はあまり育っておらず、みんなで翻刻や、近代資料における青空文庫などの事例を中心に議論が進むことが望まれよう。
橋本雄太「学習を動機付けに利用した前近代災害史料のクラウドソーシング翻刻」『じんもんこん2016論文集』2016、153–158 http://id.nii.ac.jp/1001/00176200/
加納靖之「みんなで翻刻―これまでとこれから」『リポート笠間』63、2017、53–56http://kasamashoin.jp/2017/12/63_201630.html
橋本雄太「市民参加型史料研究のためのデジタル人文学基盤の構築」京都大学博士論文、2018 https://doi.org/10.14989/doctor.r13199
【プレスリリース】市民参加型オンラインプロジェクト「みんなで翻刻」東京大学地震研究所蔵の古文書のうち495点をすべて解読! | 東京大学地震研究所 http://www.eri.u-tokyo.ac.jp/wp-content/uploads/2019/03/68e47968df85c48db3c3c50e38611cd4.pdf
京都大学古地震研究会「みんなで翻刻」プロジェクトが第12回野上紘子記念アート・ドキュメンテーション学会賞を受賞 | 京都大学防災研究所 https://www.dpri.kyoto-u.ac.jp/news/10797/
https://honkoku.org/app/#/about/characters キャラクター
かみとすみ(@kami_to_sumi)さん https://twitter.com/kami_to_sumi
橋本雄太・宮川真弥「日本語文献史料の構造化記述のための軽量マークアップ言語の開発」『じんもんこん2018論文集』2018、237–242http://id.nii.ac.jp/1001/00192381/
人文情報学イベント関連カレンダー
【2019年9月】
-
2019-09-02 (Mon)
データ活用社会創成シンポジウム於・東京都/東京大学浅野キャンパス 武田先端知ビル5F 武田ホール -
2019-09-07 (Sat)〜2019-09-08 (Sun)
Code4Lib JAPAN Conference 2019於・大阪府/大阪市立中央図書館 -
2019-09-10 (Tue)〜2019-09-11 (Wed)
考古学・文化財データサイエンス研究集会「考古学ビッグデータの可能性と世界的潮流」於・奈良県/奈良文化財研究所 本庁舎 -
2019-09-14 (Sat)〜2019-09-15 (Sun)
GLAMデータを使い尽くそうハッカソン於・東京都/国立国会図書館東京本館 新館3階 大会議室 -
2019-09-16 (Mon)〜2019-09-20 (Fri)
TEI 2019 “What is text, really? TEI and beyond”於・オーストリア/グラーツ大学 -
2019-09-16 (Mon)〜2019-09-20 (Fri)
iPRES 2019於・オランダ/EYE Filmmuseum -
2019-09-18 (Wed)〜2019-09-21 (Sat)
2019 EAJRS conference in Sofia “Rethinking resources for Japanese studies 日本学資料の再考”於・ブルガリア/ソフィア大学 -
2019-09-26 (Thu)
肖像権ガイドライン円卓会議―デジタルアーカイブの未来をつくる於・東京都/御茶ノ水ワテラスコモンホール
【2019年10月】
-
2019-10-15 (Tue)〜2019-10-18 (Fri)
PNC2019於・シンガポール/Nanyang Technological University (NTU)
【2019年11月】
-
2019-11-04 (Mon)〜2019-11-07 (Thu)
ICADL A-LIEP 2019於・マレーシア/サンウェイ・プトラホテル -
2019-11-12 (Tue)〜2019-11-14 (Thu)
第21回図書館総合展於・神奈川県/パシフィコ横浜
Digital Humanities Events カレンダー共同編集人
イベントレポート「18世紀研究における DH の広がり:第15回国際十八世紀学会(ISECS 2019)に参加して 第1回:個別発表にみるデータ可視化」
はじめに:国際十八世紀学会について
2019年7月14日(日)から19日(金)にかけて、エディンバラ大学にて第15回国際十八世紀学会(International Society of Eighteenth-Century Studies)大会が開催された。筆者はその参加報告を、今月号より数回に分けて寄稿する予定である。国際十八世紀学会はその名の通り18世紀に関する研究に携わる研究者が集まる学会で、思想・歴史・文学など多分野性がその特徴のひとつである。世界中に支部を持ち、支部単位では年次大会が開催されているが、国際大会は四年毎に開かれる祭典であり、発表言語は英語かフランス語を任意で選ぶことができる。今年は491のグループに分けられたセッションと講演が用意された。同学会の日本支部である日本18世紀学会のツイートによれば、1600名以上の参加があったようであり、四年に一度の祝祭にふさわしい盛況ぶりであった[1]。
筆者が第15回大会のプログラムを確認したとき、まず Digital Humanities(以下 DH)関連発表の多さに驚いた。日本における人文系の学会と比べて[2]、本大会では「デジタル」(英:“Digital”、仏:«numérique»)を冠する発表やパネルセッション等が多数準備され、発表者がデジタル技術の関与を前面に押し出していることが読み取れた。タイトルから DH への関連を判断できる発表の件数は、発表単位では77件、セッション単位では全477セッション中23件で、うち1セッションは終日のワークショップとして企画された[3]。全ての発表は追い切れなかったが、筆者が参加したセッションを中心に18世紀研究における DH の広がりを紹介することとしたい。
今大会で行われた DH 関連発表は、(1)デジタル技術を取り入れた個別発表、(2)DH プロジェクトの紹介、(3)DH 教育を含む人文学の未来について、という3種類に大別することができるように思われた。このうち本稿では、デジタル技術を取り入れた個別発表の例を取り上げる。(1)には、マッピングやネットワーク図の可視化を手法として取り入れていたとしても、デジタル技術の関与を前面に押し出さないタイトルをつけたものも多かった。第2回で論じる予定である各種 DH プロジェクトと差別化するために、ここではタイトルに「デジタル」が明示されていない発表における DHの実践について、手法毎に取り上げることとする[4]。
2. マッピング
マッピングによる可視化はこれまでも多くの研究者が用いてきた手法であり、地理的情報を視覚的に捉える意義は人文学者にもすでに理解されていることだろう。情報技術の発達によって変わったのはむしろ、研究に必要な地図を、研究者自身が気軽に作成できるようになったことであると考える。
しかしその弊害として、視認性の悪い地図も見られるようになってきている。例えば19日の Ruggero Sciuto の発表では、1735年から1765年までフィレンツェに駐在していた外交官 Luigi Lorenzi による、イタリア半島やフランスの外交官との書簡のやり取りがマッピングされた[5]。しかし彼はベースマップにカラーの航空写真地図を用いていたため、注意深く観察しなければ黄色や赤で表現したエッジが見えない場合もあった。可視化ツールでは用途に合わせてさまざまなオプションが用意されているが、地図を作成する際には、伝えたい内容を明確に伝えるための工夫が必要ではないか。
一方で、マッピングを多層的に行うことでより深い情報を伝えることも比較的容易になってきている。17日に行われた全体講演のひとつとして Maria-Susana Seguin が行ったプレゼンテーションでは、18世紀前半期フランスにおけるパリ王立科学アカデミーの通信会員[6]の出身地がマッピングされた[7]。彼女がプレゼンテーションに用いた図は、会員の出身地にピンを打つことで地理的な偏りを聴衆に認識させるシンプルなものであった。筆者は同じテーマについての可視化を行ったことがあり、そこでは、通信会員の出身地に、会員区分毎に色を変えた円グラフを人数に応じたサイズで配置することで、より深い情報を一見して把握できるようにした。論文など、著者による可視化を第三者が分析の材料にできる場合には多層的なマッピングが有益になることもあるだろうが、プレゼンテーションのように短時間で画面を遷移しなければならない場合には、主張したい点に情報を集中する方が、伝えたい情報を効果的に伝えることができると思われる。研究者それぞれが自分の目的に応じた地図を作成できるようになったからこそ、重層的な情報提供の可能性を意識しつつも「見せる」ための配慮を忘れないように心がけたいところである。
3. ネットワーク分析
一方でネットワーク分析、なかでもネットワーク図は一見人文学研究に馴染みの薄い可視化モデルに感じられるかもしれない。しかし Chloe Edmondson、Dan Edelstein らが述べるように、近世ヨーロッパ研究において人的結合関係は多くの研究者の関心を集めてきたテーマであり、その意味でネットワーク分析もまた、人文学との繋がりの深い分析手法である[8]。
近世のヨーロッパでは、国際的な書簡のやり取りや、印刷技術の発達による書物・定期刊行物の流通が発達した。「文芸共和国」あるいは「学問の共和国」(Respublica Litteraria)と呼ばれる書簡や印刷物を介した国際的ネットワーキングについては訳書によって日本にも紹介された[9]。さらに近年の欧米圏では、DH 的アプローチによってこの国際的ネットワーキングの研究を深化させようとする研究書が次々に出版されている[10]。
18日のセッションでは、Gemma Tidman がコレージュ教育[11]に言及した個人や雑誌のポジティブ・ネガティブな反応をネットワーク図で表現した[12]。彼女は赤と青のエッジと、ラベルのついたノードを持つネットワーク図のプログラムを独自に作成して生成し、「ルソーと『トレヴー誌』(Journal de Trévoux)にはポジティブな結びつきが見られる」という「気づき」を述べた。
発表には時間的制約があるため、彼女は特定の人物と定期刊行物との関係に言及するに留めたのかもしれないが、筆者は彼女がネットワーク図を分析に用いた意義を十分には理解できなかった。なぜなら、彼女の指摘した「気づき」は限定的であるように思えたので、可視化のためのプログラムに読み込ませずとも、Excel で作成した元のデータから判断できたと考えられるからである。同じ感想を持ったのは筆者だけではなかったのか、質疑応答では、このネットワーク図に質問が集中する結果となった。
質疑の論点は2点あった。1点目は、ノードに人物と定期刊行物が混在しており、何を言おうとしているのかネットワーク図からはわからないという指摘、2点目は、Palladio[13]や Tableau[14]などの可視化ツールを使わないのかという質問であった。1点目は技術的に改善可能であるように思う。エッジに矢印をつけ、有向グラフにしていれば、ソースとターゲットとして人物と定期刊行物を同じネットワーク図上に表現する理由を説明できたのではないだろうか。
2点目の可視化ツールの使用についての質問は、DH 推進派で、今大会でもデータベースの分析について発表した研究者によるものであった。たしかに Palladio や Tableau はデジタル技術への敷居を下げ、技術面の知識がなくとも研究者たちにデジタル技術の実践を可能にする便利なツールである。しかしこれらのツールを利用する際には、その分析モデルがどのような種類の理解に役立つのか、あるいはどのような分析には向かないのかについても検討する必要があるのではないだろうか。
Tidman に限らず、今大会ではいくつかの「過度に単純化されたネットワーク図」が見られた。これは、必ずしもネットワーク図を用いたネットワーク分析の基礎理論や特徴を理解せずとも、ツールを用いれば「容易に」可視化できる現状が孕む問題であるように思われる。分析手法が理解されずに可視化された図は、幾何学的に綺麗に整っていても、プレゼンテーションの中では装飾としての役割しか果たさない場合があるかもしれない。ネットワーク図に組み込める要素について理解した上で、自らの研究に必要な要素を慎重に検討し、求める要件を満たす可視化モデルを選ぶ必要があるのではないか。Palladio も Tableau も提供する可視化モデルは限定的であるので、それで足りない場合にはプログラミング言語を用いた可視化が必要になることもあるだろう。そしてネットワークモデルは、Tableau の基本モデルとしては提供されておらず、Palladio では色や表現できる範囲に制限がある。Tidman が作成したようなモデルは、独自のプログラムを用いて作成するのであれば、より適切な表示の仕方を追求すべくスキルを高める必要があるだろう。しかし、この場合にはあえて独自のプログラミングをせずとも Gephi[15]の利用が有効であるようにも思えた。可視化モデルやツールを選択する場合には、データや分析手法への理解と適切な情報収集がますます重要なものとなっていることを改めて感じた。
4. おわりに
本稿ではマッピングとネットワーク分析について取り上げたが、いずれも分析対象や内容はこれまでの人文学研究から外れるものではなく、あくまで可視化の手段として DH 的アプローチを取っているという印象を受けた。しかし、マッピングやネットワーク分析の背景には、地理学や統計学などの蓄積がある[16]。こうした他分野の蓄積に学ぶことで、デジタル技術をより深く研究に適用する可能性が人文学研究にも開かれるかもしれない。
今や、人文学者の大多数が DH プロジェクトの恩恵を受けるユーザである。Lara Putnam が指摘するように、そのユーザのほとんどがデジタル・リソースの上澄みを利用するにとどまり、デジタル・アーカイブやデジタル・コレクションの閲覧とダウンロードを目的に利用する[17]。情報提供者側がどれほど精巧なデータベースやツールを作り上げようとも、ユーザ側に利用するにあたってのリテラシーがなければ、情報提供者側の意図が十分に伝わらないことも考えられる。
では、これまで DH に関心を持ってこなかった人文学者に、彼らにとって新しいデジタル資源とその利活用にあたって必要なリテラシーを届けるには、どのような行動が求められるのだろうか。ひとつの解決策としては、例えば The Programming Historian[18]やイギリス歴史研究所(Institute of Historical Research)主催の Digital History Seminar[19]のような、ユーザとして批判的実践例を積み重ねる取り組みに活路を見出せるのではないかと考える。このような問題関心に基づき、本稿では利用者の側から批判的に国際十八世紀学会の個別発表を振り返った。次回は DH プロジェクトを紹介したい。より多くのユーザがより深く、より批判的に DH の資源を活用するために、本短期連載がわずかなりとも参考になれば幸甚である。
イベントレポート「DH2019体験記」
本記事は、2019年7月8–12日に渡って、オランダ・ユトレヒトにあるコンサートホール TivoliVredenburg で開催された DH2019の報告である。当学会は、最大10を超える多様なセッションに分かたれており、当然筆者個人がその全体像を把握した訳ではない。あくまでも筆者が見聞した限りにおける、ごく限定され、多分に断片的な報告に過ぎないことをご了承いただきたい。
7月8日と9日午後にかけて Workshop が行われた。報告者はそのうちの一つである “E-Lexicography Between Digital Humanities And Artificial Intelligence: Complexities In Data, Technologies, Communities” に参加した。筆者が参加したこの Workshop は、ELEXIS(European Lexicographic Infrastructure)が Prêt-à-LLOD と共催したものである。ELEXIS は、個別言語の辞書に限定されず、複数の西洋言語間をリンクするかたちの辞書構築のための研究インフラ開発を目指すものであり、近年では、西洋言語を超えて、アジア圏、アフリカ圏の言語を取り扱うことが計画されているようである。同プロジェクトの沿革と展望が報告され、この辞書を用いた、自然言語処理、テキスト分析を行った研究成果が発表された。
この1日半の Workshop ののち9日午後5時から DH2019の開会式が行われた。一昨年の DH2017はカナダのモントリオールで、昨年の DH2018はメキシコシティで開催され、3年ぶりにヨーロッパで開催されることとなった今大会では、「複雑性」(Complexities)をテーマとし、アフリカ文化に関するセッションが数多く催される旨が報告された。キーノート・スピーカーの一人南アフリカ共和国ケープタウン大学教授 Francis B. Nyamnjoh 氏が、情報通信技術をヨルバ語で言うところの juju—狭義の意味の身体を拡張し、人間個人の行動範囲を大ならしめる技術—として描き、これと人間との関係を論じた。
また、オランダ教育・文化・科学大臣の Ingrid van Engelshoven 氏によるビデオレターも放映された。そこでは、兎角、人文情報学というと、どれだけのグラントを獲得したか、どれだけの論文を書いたか、という点ばかりに評価の基準が置かれがちであるが、データセットの作成、整備等の地道で、一見研究者の業績として評価されにくい部分も考慮に入れる必要があるという趣旨のコメントがなされた。このような問題点は、日本の学界内部では議論の俎上に上がっているものの、広く共有されている課題とは言い難いように思える。そのような問題意識が、オランダにおいては学界と政界ともに共有されていると思い知るに、やはり西欧の先進性を痛感せざるを得なかった。
10日からは、複数のセッションに分かれてのパネル発表、ショートペーパー、ロングペーパーによる研究発表と、11日午後からポスター発表が行われた。複数のセクションに分かれていたため、ごく一部に参加したに過ぎないのであるが、そのなかでも筆者個人の専門とするインド古典語文献に近く、印象的な発表であった、“Confronting Complexity of Babel in a Global and Digital Age” という12日の昼食休憩前に開催されたパネルの内容を簡単に報告したい。
同パネルでは、とうてい個人では学習することもできないような無数の言語を扱うことが必要になる現在、いかにして自分が知らない複数の言語を処理しうるのかという点について複数の研究者による発表が設けられた。具体的なツールの紹介、翻訳の限界、必要となる言語学的な知識、アノテーションの必要性などが言及されたのち、学習環境の整備の一例として、ザグレブ大学準教授 Neven Jovanović 氏によるサンスクリット語学習のデジタルツール作成についての発表があった。サンスクリット語で書かれたヒンドゥー教の聖典である『バガヴァッド・ギーター』の August Wilhelm von Schlegel(1767–1845)によるラテン語訳と、サンスクリット原典を対応させたものをベースとした、フラッシュカード等の学習用教材を作成するプロジェクトが紹介された。ここで媒介言語としてラテン語が用いられているのは、同じ印欧語族に属する古典語として構造が類似していることと、学生にとって(もちろん、西洋の学生にとって、という意味である)既知であるラテン語の知識を用い、他の文化伝統と比較することを可能ならしめるためであるとのことであった。
最後に、会場の雰囲気について簡単に触れておきたい。今回の DH2019前述の通り、コンサートホールを借り切って行われたため、セッション会場によっては発表者の演壇の隣にピアノが鎮座していたり、スポットライトの色が赤や青であったり、日本では到底お目にかかることのできないような、なかなかに個性的な様相を呈していた。参加者はおおむね諧謔を解し、大らかで自由な雰囲気のなかで、闊達な議論が繰り広げられていた。
◆編集後記
この月末は、関西大学にて日本デジタル・ヒューマニティーズ学会の年次学術大会 JADH2019が開催されています。イベントレポートで紹介されているユトレヒトでの DH2019や、TEI カンファレンスと合同開催した昨年の JADH2018 に比べると規模は小さいですが、世界中から集まった研究者達によって濃厚な議論が行われています。 今年も運営のお手伝いをしつつ、こういう機会が萌芽となっていずれ広く活かされていくことを願っているところです。
(永崎研宣)
- コメントを投稿するにはログインしてください