人文情報学月報第104号
ISSN 2189-1621 / 2011年8月27日創刊
目次
- 《巻頭言》「授業運営とシステム開発を通じて得た人文情報学的知見」
:同志社大学文化情報学部 - 《連載》「Digital Japanese Studies 寸見」第60回
「DH Awards 2019受賞決定」
:国文学研究資料館古典籍共同研究事業センター - 特別寄稿「Arethusa による古典語の言語学的アノテーション:構文構造の可視化と広範なデータ利活用の実現」
:東京大学大学院人文社会系研究科 - 人文情報学イベント関連カレンダー
- 編集後記
《巻頭言》「授業運営とシステム開発を通じて得た人文情報学的知見」
このたび巻頭言の執筆というたいへん光栄な機会を頂きました。執筆時点においては新型コロナウィルス感染症 COVID-19騒動が世界を覆っています。この文章がメーリングリストに掲載される近い将来であっても状況がどうなっているか、見当がつきません。直接・間接問わず多くの方の生活に深刻な影響を与える未曾有の事態が今よりは終息に近づいていることを願いながら、拙文に興味をお持ちいただいた方が少しでも有益と感じていただける情報をご提供できればと思い、拙文を認めます。
自分が面白いと思っていることを書くようにとのご依頼でした。筆者が担当している授業のことを中心に、拙作のデジタル翻刻データベース作成支援システムの技術回りについて、折角ですのであまり他では書かれていないようなことを書きたいと思います。
筆者の所属する同志社大学文化情報学部[1]はいわゆる文理融合学部です。文理融合といえば当節の流行という感もありますが、本学部は設立から16年目を迎えます。筆者は途中参加で、約10年前から古典文学をご専門とされる先生と一緒に PBL 型の必修授業の1クラスを担当することになりました。筆者は情報科学の人間で、その方面の協力を期待されていたわけですが、和歌や古典文学を対象として何ができそうか検討した結果、当初は文字列解析を中心に授業を組み立てました。文学部ではありませんので学生は皆がくずし字を読めるわけでもなく、そもそも影印や翻刻といった言葉も知りませんでしたが、それは筆者も同様です。学生と一緒に学びつつ、Ruby、Excel 等で文字列データを処理する方法を教授しながら頻度分析を行い SplitsTree によって本文の系統分類を行いました。
そのような背景のもと、2013年度は大学図書館に所蔵されている伊勢物語御歌かるた[2]を教材として採用しました。かるたを採用するメリットは何といっても絵を利用できることです。かるたには和歌が描かれるとともに人物、道具、風景も描かれています。描かれているモノと物語本文や和歌との関連について考察するという定性的な分析演習は、文字列情報だけを扱う場合と比較してずっと実施し易くなります。
画像を扱うにあたって授業運営の裏方として技術的な困難がいくつかありました。画像の矩形領域に対して注釈を付ける作業を学生が各自で行い、その結果を全員で相互に確認するという作業を実現する必要があり、そのために Ruby on Rails[3]ベースのシステムを学内 Web サーバに設置しました。タブレットでも操作できるようにあれこれ工夫しました。当時は画像の取り扱いにかなり苦労しました。低解像度版やサムネイルを自前でやり繰りする泥臭い実装に限界を感じて何か良い方法はないかと調査したところ IIIF[4]を知り、その次の年度から採用することにしました。その結果、Mirador 等の IIIF Viewer と連携して注釈データを作成するといった試みをより少ない労力で実現することができました。やはり新しい技術を知ることは大切ですね。
その後、同授業ではいくつかのシステムを作成しましたが、いずれもIIIF にはお世話になっています。それらのシステムのうちいくつかは、オープンキャンパス用に作成した Web サイト[5]にまとめています。もしお時間があればご笑覧ください。2019年度秋学期には KuroNet[6]や GitLab[7]を用いて百人一首かるたのデジタル翻刻を試みました。その成果は整理でき次第、公開する予定です。
IIIF を利用したシステムを開発・運用するためのノウハウは、多くの方がさまざまな媒体で紹介されていますのでそちらに譲るとして、あまり紹介されていないと思われる情報(おそらく紹介するに値しない細かい情報)をご紹介したいと思います。主に開発者向けの情報です。
まず IIIF 画像サーバについて。広く使われており高速と言われている IIPImage Server[8]は、インストールが大変だという話も見聞きします。ソースコードからのコンパイルに慣れていない方でも最近は CentOS 等 RedHat 系 OS のパッケージマネージャからインストールすることもできます。ただしリリースの頻度はそれほど高くなく、最新の機能を取り込みたい挑戦的な方は、やはり工夫が必要となります。幸いソースコードは GitHub にて公開されておりますのでいくつかのコマンドを実行すれば手元のシステムを最新に保つための手順は単純です。手元のシステムが公式のものでなく改良を加えたものである場合はforkを作成するとよいでしょう。IIPImage Server に限らず、いくつかのソフトウェアの開発を行う際には要求される開発環境の違いに注意する必要があります。複数の開発環境を並行して用意するためにはコンテナ仮想化技術 Docker[9]が便利です。既に Docker に馴染みのある方で、新たに IIPImage Server を利用されたい場合は、拙作のコンテナイメージ[10]をお試しください。コマンド1つで IIIF 画像サーバを起動できます。コンテナイメージは約30MB と、他のイメージと比べてかなりコンパクトです。
やや話が逸れますが、上に挙げた Git と Docker はソフトウェアとして直接の関係を持つわけではないものの、共通点として、デジタルデータの差分や履歴を効率的に管理するためのシステムを中核部分に備えている、という性質を挙げることができます。人文情報学において画像データや注釈データなどのデジタルデータを作成・管理することの重要性は広く認知されております。モノのデジタル化は常に不完全であって必ず何らかの取りこぼしが生じるという前提で考えれば、デジタル化を実現するための技術は今後も改良を求められ続けます。「写本」のデジタル版といっても良いかもしれません。現存するアナログ写本については作成された経緯にアクセスすることはできませんが、今後生み出されるデジタル写本については保存するための工夫ができます。この点については情報技術が貢献できるはずで、情報科学に携わる者の一人として微力を尽くしたいと考えています。
執筆者プロフィール
《連載》「Digital Japanese Studies 寸見」第60回
「DH Awards 2019受賞決定」
DH Awards 2019の投票が終了し、結果が発表された[1]。DH Awards については、以前も紹介したが[2]、「副題を Highlighting resources in Digital Humanities とし、前年に始められたり、おおきなリニューアルを迎えたりした DH にまつわるリソースのなかから、いいものをみんなで選ぼうという試みである」。今回も、2019年のあれやこれやから自薦他薦によって選ばれた7部門76件の応募のなかから、それぞれ全世界からの人気投票によって受賞作が選ばれた(したがって、順位に一貫した質的判断があるわけではない)。今回からは「データセット部門」が追加されている。増えたことに関するアナウンスはとくだんなされていないようである。前回は、投票中に執筆したため全応募の概要に留まったが、今回は受賞作を中心に必要に応じて受賞を逃した作品にも触れていきたい。なお、全応募作の URL は[1]からたどっていただきたい。
まず、「不首尾の検討」部門は、今回は2点の応募があり、デジタル歴史研究者の S.グラハムによる Failing Gloriously and Other Essays(華々しき失墜およびその他の論攷)[3]に与えられた。この書籍は PDF 版がオープンアクセスで公開されている。文体こそ軽いもののすぐに読める長さではないが、失敗を英雄視せずに検討することによって環境を変える試みでもあり、また自分史でもあるようだ。次点の作は、どこで失敗したか見失っているように見える点で、失敗を物語ることの難しさを物語っており、まさに本賞がまっさきに掲げられる意義を逆説的に照射するがごとくである。
「楽しい事例」部門では、"The Data-Sitters Club”[4]と “The Digital Ghost Hunt”[5]が同時受賞した。前者は、性格をつかみ切れていないが、アメリカの DH 文化を色濃く映したブログのようである。「ブログ」部門にも推薦されていたがこちらは3位であった。後者は、プログラミング教育と拡張現実と演劇とを掛け合わせた試みとのことである。小学5年生の子供達にデジタル機器を持たせ、施設内にひそむ幽霊を捕まえるツールを作るという試みがなされたようである。投票にあたって大々的な投票呼びかけも認められているため(いちおう投票時にほかの作品にも目を向けてほしいという)、得票数の意味づけは当然難しいものの、この二者に投票されたことは大がかりさだけで決まるわけではないことを伝えており興味深い。そのほか、受賞に至らなかった作では、人文知的なデータを変形させる試みや市民協働翻刻(リニューアル後のみんなで翻刻)などもあった。
「データ可視化」部門では、“Witches”[6]が受賞した。エディンバラ大学でのスコットランドの魔女狩りについて可視化したものであり、3000以上の魔女狩り事例をまとめた研究を背景にしているために雄弁である。また、ある「魔女」の事例について背景説明や地図とともに事例が検討されており、理解を深めることにも意がこらされている。受賞に至らなかった作品も、さまざまに工夫をこらしているが、“Fontanes Handbibliothek visualisiert”[7]は個人蔵書の可視化として出色の出来(稿者が知らないだけかもしれないが)。使いやすさには改善がほしい。
「データセット」部門では、“Romans1by1”[8]が受賞した。これは、古代ローマおよびギリシア人の墓碑に刻まれた人名に関するデータベースで、現在は北マケドニアからルーマニアにかけてのものが収録された2万件ていどのレコードがある。データセット全体のダウンロードは許可されていないが、よく整理されたグラフデータという印象である。1件1件しっかりと出典も記されている。第2位のスコットランド国立図書館による圧巻の『エンサイクロペディア・ブリタニ』初版公開プロジェクト[9]をはじめ、XML によるテキストデータ公開が多く、“Open Editions Texts”[10]や “The Travelogue Corpus”[11]のように、GitHub を公開場所として選ぶところが多いのもいまどきである。Word Dependencies の古典語データがあるというのもいままでと毛色が違うかもしれない。
「DH ツールおよびツール群」部門では、“Online Coptic Dictionary”[12]が受賞した。エジプト・コプト語の辞書を作る試みで、他のコプト語関係リソースへのリンクが多く便利ではあるが、プログラムから情報のやり取りをする API のたぐいはとくになさそうなのが残念である。HTML はパースしやすいように作ってあるらしい。この部門は、企業の提供するツールが多いのも印象的で、企業提供のツールということは簡便に試せなかったりするわけである。かれらの主要顧客である欧米では知名度もあろうが、東洋には進出していないものがほとんどであり、DH Awards のオープンさとマッチするのか考えて応募したのかと余計なことを気にしてしまう。ほかにも、自分が工具として使うことを想像しにくいものも多く、そもそもデータセット部門に応募したほうがよさそうな作品もあり、この点は新設部門の知名度の問題なのかもしれない。
「ブログ」部門は、日本では低調の一方だが、欧米ではそうでもないようだ。プロジェクトからの発信として SNS よりすぐれたメディアだろうとは思うし、論文の代わりともなりきらないが、自戒にならないわけではないものの、発信とかいうことを気にせず、もっと気楽な書き物が書かれてもよい。英語圏のブログは、“Digital Humanities Now”[13]でしばしば取り上げられるというような環境の差もあるし、そもそも長文を書くのが好きという差もあろうが。よいブログというのが、放置とまでいかないほどには間を置かずに一定の質の議論を提出するものであるとすれば、今回の応募作はどれもその栄誉を受けるにふさわしいといえ、それが3位が3点もあったということなのだろう。この部門では“The Shiloh Project”が受賞者となった[14]。これは宗教と性暴力を些細なこととする文化(レイプ・カルチャー)との関係について考察するプロジェクトの活動報告をするもののようで、ブログというよりフォーラムといった印象を受ける。
「一般参加」部門は、“Representations of Cyprus” が獲得した[15]。キプロスの歴史的な地図や風景画などをデジタル化し、場所や人工物などの特定をしたもので、ギリシアのハロコピオ大学地理学科における一年のプロジェクトの成果であるとのことだが、これはいささか問題の多いプロジェクトである。第一に、ギリシアのキプロスに対する考え方があきらかに押し付けられている。第二に、一般参加をする余地があまり見えない点が挙げられる。第一は政治的なものなのでここでは措くにせよ、第二のものは、一年計画でどのように一般参加を得たのかいっさい記述がない点からも疑わしく思われる。フィードバックは各ページに設けられているが、それだけで一般参加と言ってよいのであればたいがいのものはそれで一般参加になってしまうだろう。 次点の “American Religious Sounds Project” は[16]、アメリカにおける宗教的行事の音に焦点を当てるプロジェクトであるが、市民が我が事として見られるのが市民参加だとして、むしろクラウドソーシングに距離を置く。クラウドソーシングプロジェクトは、白人男性が集まりがちとするが、とくに出典は示されていないのは残念である[17]。それに対して、同列第3位のひとつである “Italian Paleography” は、古書体学への解説がくわしく、ツールも独自開発であるようであるが、よくあるクラウドソーシング型翻刻プロジェクトである[18]。[16]における市民参加が素材の提供でありうるのとくらべて、素材はすでにプロジェクトの手もとにあるという点で参加者の属性が問題として顕在化しにくいという差はあるのだろう。おなじく第3位の “Open a GLAM Lab” は、GLAM(美術館・図書館・文書館・博物館)でのプロジェクトをどのようにすればよいのかということをまとめた本であった。
この賞は、祝祭的なものとして作られたことを受けて、立候補も厳密ではないし、自薦他薦の別もとくに重視されているわけではない。さりながら、どうしてこんな部門にと思うものや(そこをがんばったの?と尋ねたくなるという意味で)、DH Awards を獲得したとトップページにわざわざバナーまで掲げるものが出てきており、長くやっているといろいろ変わってくるものだと思わされる。とはいえ、順位に深い意味はないというのが本来のこの賞だろうと思うし、DH の今をいちばん実感できる企画であることに変わりはなく、非受賞作を含めて楽しんでもらいたい企画である。
特別寄稿「Arethusa による古典語の言語学的アノテーション:構文構造の可視化と広範なデータ利活用の実現」
ギリシア語およびラテン語のツリーバンク作成[1]、そのための言語学的アノテーション付与を補助するデジタルツールとして、Arethusa がある。現在、Arethusa は The Perseids Project を介して利用可能であるが[2]、このツールは最終的には、ライプツィヒ大学のプロジェクトである Ancient Greek and Latin Dependency Treebank 2.0に資するものである[3]。このプロジェクトは二つの目標を掲げている。一つ目は、新たな仕様に基づくツリーバンク・データを生成すること[4]、二つ目は、可能な限りのアノテーション自動化、およびデータ形式変換の簡略化を可能にするツールを整備することである。Arethusa は、この二つ目の目標に沿って開発されたと言うことができよう。
さて、言語学的アノテーションといった場合、付与すべき情報の種類は主に、形態情報と統語情報の二つである。他に、意味情報を付与する場合もあるが、Arethusa において、この機能は限定的である。それゆえ以下では、まず Arethusa の基本的な操作を説明し、どのように形態・統語情報をテクストに付与するかを示す。その後、作成されたデータがどのような形式で保持され、利用されうるかを明らかにする。
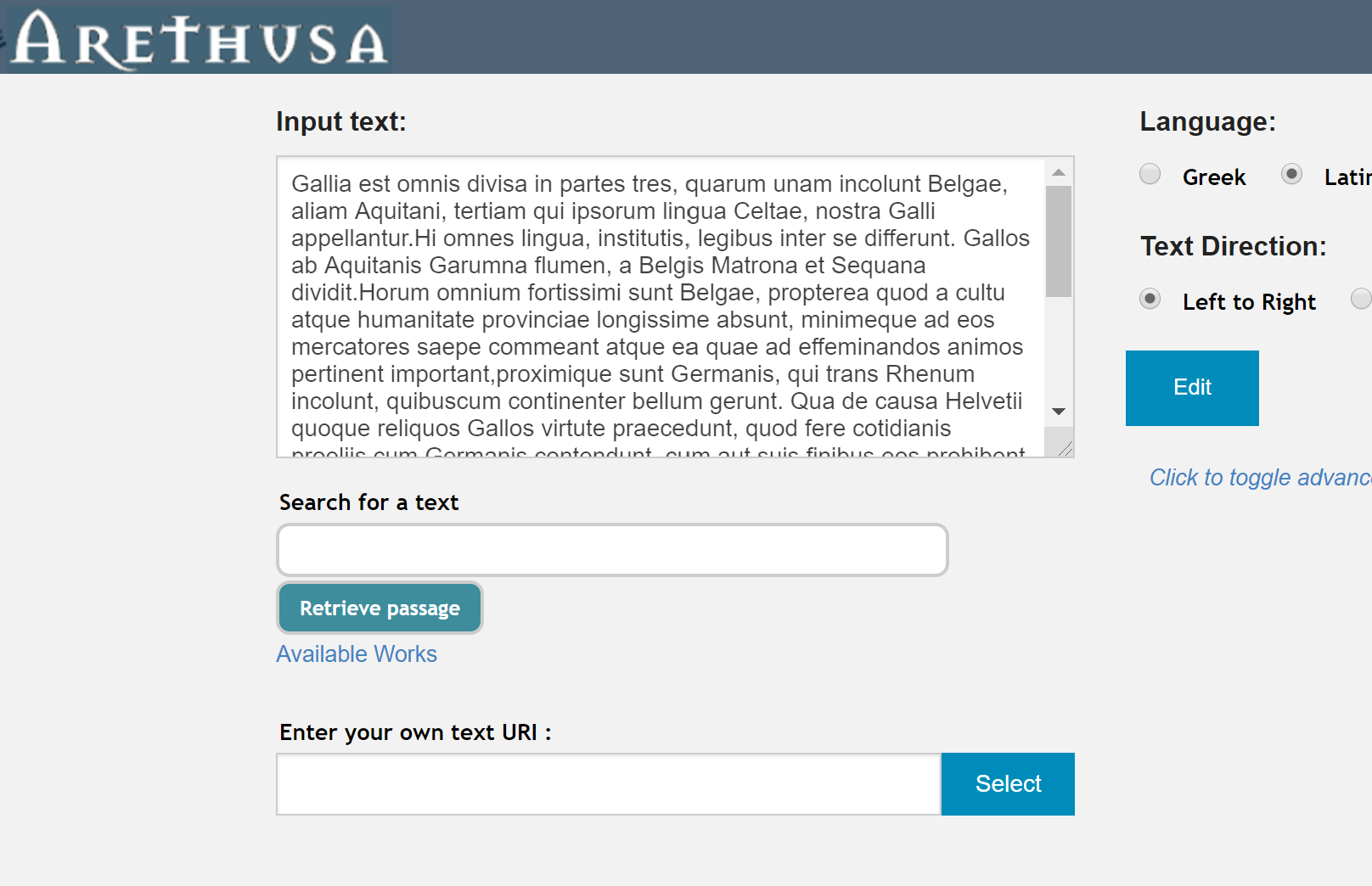
Arethusa を用いてテクストにアノテーションを付与するためには、The Perseids Project のホームページから、Perseids Platformにログインする必要がある。ログインすると、上部にいくつかの項目バーが現れ、その中から “NEW TREEBANK ANNOTATION” を選択すると、アノテーションを付与したいテクストを入力する画面が表示される。“Input text:” という欄に手動で直接テクストを入力してもよいが、より便利な方法として、Perseus Digital Library からテクストを自動的にインポートすることができる。“Available Works” というリンクをクリックすると、Perseusのページに遷移するので、左側のバーの中から言語を選び、アノテーションを付与したいテクストを表示する。Perseus のテクスト表示ページでは、テクストの下に “Annotate in Perseids” や “Create Treebank,” “urn:cts” といったいくつかのエクスポート方式が表示されており、Arethusa へエクスポートする場合には “Create Treebank” を選択する。すると、先ほどのテクスト入力画面の “Input text:” の欄に自動的にテクストが挿入されるので、右側の “Edit” をクリックし、アノテーション付与画面に移行する(図1)。この画面からの操作を通して、実際にアノテーション付与を行っていくこととなる。
アノテーション付与画面上部には、テクストが語ごとに分割された状態で、一文ずつ表示される[5]。ここでは、表示された各語をクリックすると、その語が選択された状態となり、右の “morph” や “relation” といったタブからアノテーションを付与することができる。このうち、“morph” タブから形態情報を、 “relation” タブから統語情報を付与する。試しに、カエサル『ガリア戦記』の有名な冒頭、「ガリアは全体で三つの部分に分かたれている Gallia est omnis divisa in partes tres」という文言にアノテーションを付与し、ツリーバンクを可視化したのが以下の図2である。
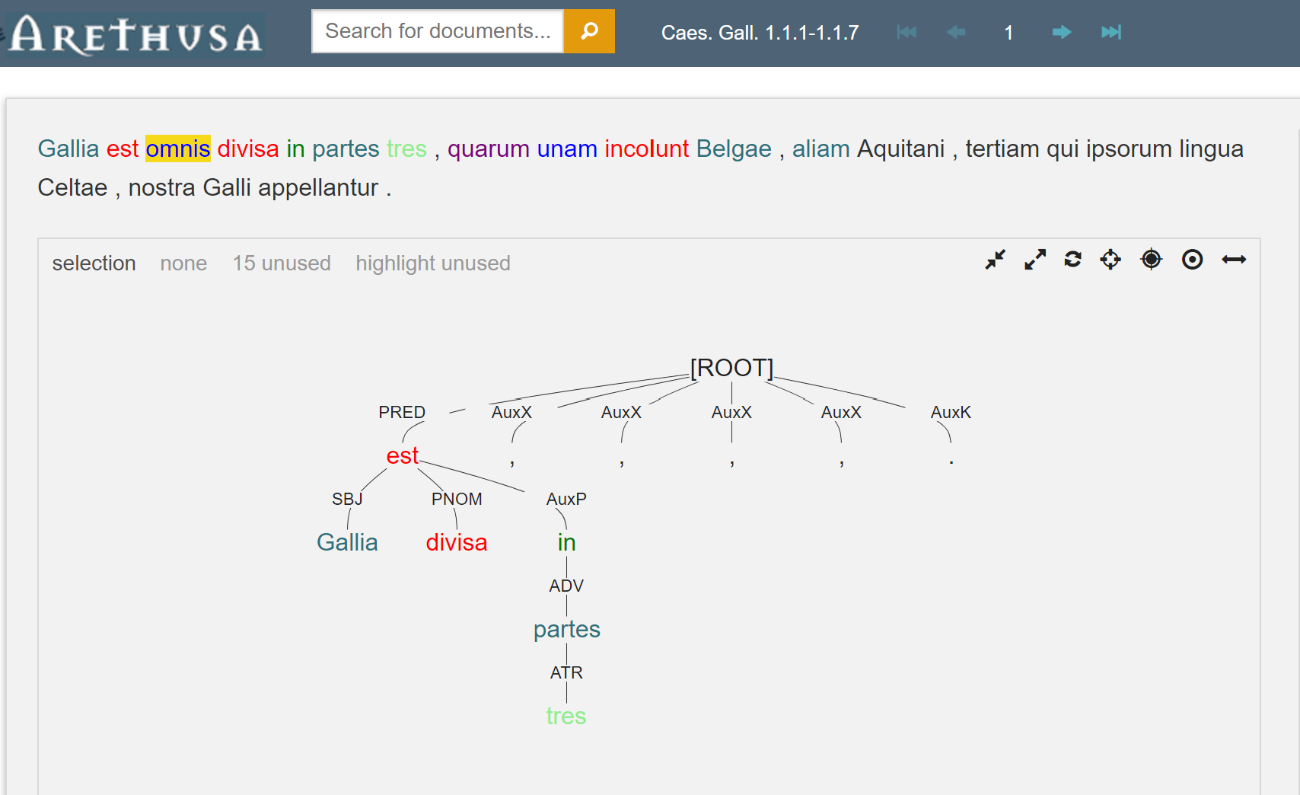
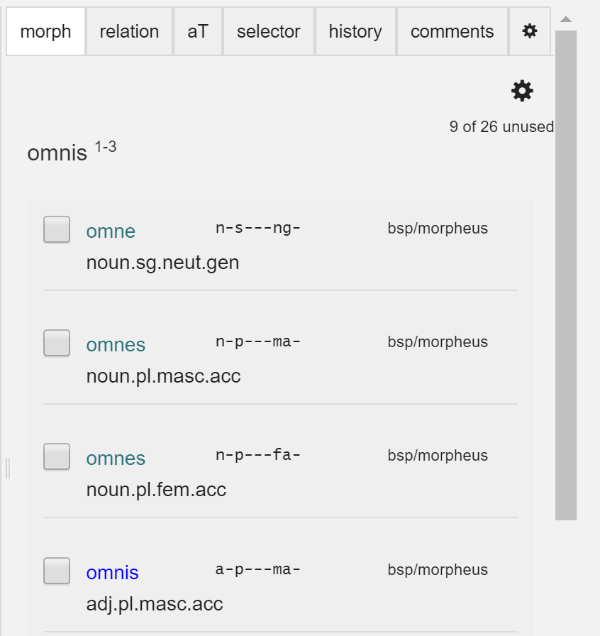
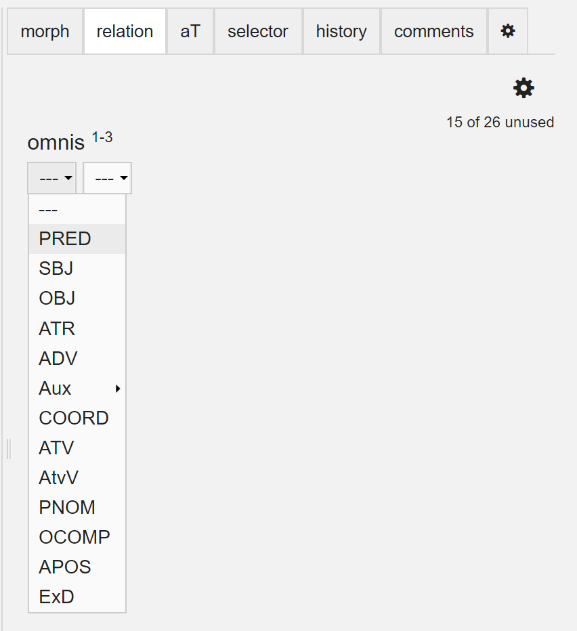
図2では、omnis という語が黄色でハイライトされているが、これは、この語が現在選択されていることを示している。この状態で、画面右の “morph” タブをクリックすると、omnis の形態情報を付与できるが、図3からわかるように、Arethusa では予めいくつかの選択肢が表示されるので、その中から選択することができる。もし、選択肢の中に該当する形態情報が存在しない場合には、新たに手動で設定することも当然ながら可能である。続いて、omnis を選択した状態のままで “relation” タブをクリックすると、図4のような画面が表示されるので、語の文法的機能を選択肢から設定する。次に、図2の画面から、語同士の繋がりを定義する。すなわち、選択された語が、どの語に対して文法的機能を果たしているのかを設定するということである。操作方法は非常に簡単で、まず特定の語(ここでは omnis)を選択したうえで、その語が文法的機能を果たす対象の語を、表示されたテクスト上、あるいは表示されるツリーバンク上でクリックするだけである。これらの作業を各語に対して行うことで、一文全体に形態・統語情報を付与し、ツリーバンクとして可視化することができる。
さて、このように作成されたデータは、自動的に XML で記述され、保持されることになる。この XML データはツール上で確認でき、UI を用いずに、直接編集することもできる。また、XML ファイルをダウンロードすることも可能である。実際の XML データは、図5のような形式で作成される。

この XML ファイルを見ると、 “word” 要素の中に、“postag” 属性が付与されていることがわかる。ここでいう postag とは、Part-of-Speech Tags(POS Tags)のことを指している。POS Tags とはその名の通り、各語の品詞情報(法や時制といった文法情報を含む場合もある)を記述するために用いられるタグセットであり、言語ごと、あるいは言語横断的に設定される[6]。Arethusa を用いたアノテーションも、ギリシア・ラテン語のためのPOS Tagsに基づいて行われており、“postag” 属性はこのタグ情報を記述する項目である[7]。“relation” 属性と “head” 属性は語の係り受けを記述するためのもので、“head” 属性値が係り先の語の ID、“relation” 属性値が語の機能を記述している。
このように、規格化されたタグセットを用いてデータを作成しておけば、データ形式や使用タグの自動変換を容易に行うことができる。それによって、例えば、Arethusa で作成したデータを変換して、Universal Dependencies(UD)のデータの一部として公開するといったことが可能になる。UD は、複数言語間で統一規格に則ったツリーバンク作成を目指すプロジェクトであり、すでに70言語以上のデータが蓄積されている[8]。UD に蓄積されたデータは、複数言語間の構文解析・比較に利用でき、言語学研究に大きく資することになるだろう。Arethusa を用いてアノテーションを行い、構文構造をデータ化することで、ギリシア・ラテン語の言語学的分析に貢献しうるのみならず[9]、UD という国際的なプロジェクトに貢献し、比較言語研究への幅広い利用可能性を持つデータを作成することができるのである。
最後に、少し話は変わるが、Arethusa を用いた言語学的アノテーションのギリシア・ラテン語教育への利用可能性について簡潔に触れておきたい。言語学的アノテーションが自らの文法解釈について、形態・統語両面からの厳密な検討を促しうるという点を踏まえれば、これを学習者、とくに初級文法を終えてテクスト講読を始めた段階の初学者向け学習ツールとして活用することは大いに有効であろう。Arethusa という共通のツールを用いて、テクストへのアノテーション付与の過程を議論すれば、厳密な文法・構文知識を身に付けるための大きな助けとなりうる。同時に、将来、デジタル環境での言語学的アノテーションに関わりうる人材を育成することにもなり、学習で用いたデータを蓄積・保存しておけば、そのデータを用いて言語分析、テクスト分析を行い、いずれ自らの研究に役立てることも十分に可能である。
人文情報学イベント関連カレンダー(今後、中止になる可能性がありますのでくれぐれもご注意ください)
【2020年4月】
-
【延期】2020-04-25 (Sat)〜2020-04-26 (Sun)
デジタルアーカイブ学会第4回研究大会於・東京都/学術総合センター一橋講堂
【2020年6月】
-
【延期】2020-06-01 (Mon)〜2020-06-05 (Fri)
DHSI2020於・カナダ/ヴィクトリア大学 -
【延期】2020-06-01 (Mon)〜2020-06-04 (Thu)
IIIF2020於・アメリカ合衆国/ハーヴァード大学 -
2020-06-20 (Sat)〜2020-06-21 (Sun)
Code4Lib JAPAN カンファレンス2020於・愛知県/愛知大学豊橋キャンパス
Digital Humanities Events カレンダー共同編集人
◆編集後記
新型コロナウイルス感染症への対応で、研究・教育の根幹が揺るがされつつあります。師のそばにいって教えを請う、皆で集って議論する、といった、人類史の中でも長く続いてきた基本的な所作を自粛しなければならない状況になってしまいましたが、一方で、時間が止まってくれるわけではなく、そのような状況でいかにしてよりよい研究・教育を展開していくかということが大きな課題になり、特にオンライン授業やオンライン会議が注目されつつあります。デジタル媒体を介することが多い人文情報学でさえも、やはり様々な課題に直面しているところですが、そこでの取り組みは、人文学全体、あるいは研究・教育全体に対してフィードバックできることが出てくる可能性があり、その点には期待するところです。少し前に開始された、東京大学人文情報学部門の大向一輝先生を中心としたUTDH動画チャンネルなども、将来を切り拓いていく上でのヒントを提供してくれるかもしれません。先を見通しにくい状況ではありますが、そんなときこそ、できるところから着実に進めていくことが未来を形作っていくことになると思います。(永崎研宣)
- コメントを投稿するにはログインしてください