人文情報学月報第135号【前編】
ISSN 2189-1621 / 2011年08月27日創刊
目次
【前編】
- 《巻頭言》「和歌を対象とした古典文学研究と作品データの集積:古典和歌の研究者は何を求めてどのような検討を行っているのか?」
:国文学研究資料館 - 《連載》「Digital Japanese Studies 寸見」第91回
「明治期官僚・官職データベース(國岡 DB)、Web UI 版を公開」
:北海学園大学人文学部 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第52回
「Hugging Face AutoTrain における最新鋭 AI モデルによるノーコード機械学習」
:人間文化研究機構国立国語研究所研究系
【中編】
- 《連載》「デジタル・ヒストリーの小部屋」第10回
「デジタル・ヒストリーと可視化(1)」
:千葉大学人文社会科学系教育研究機構 - 《特別寄稿》「TEI ガイドラインにおける性別とジェンダーの改訂」
:ペンシルヴァニア州立大学 - 《特別寄稿》「Extended Matrix と考古学・歴史研究:3D モデル構築のプロセスを記録し可視化するためのデータモデル」
:ROIS-DS 人文学オープンデータ共同利用センター(CODH)
【後編】
- 人文情報学イベント関連カレンダー
- イベントレポート「「3D Imaging and Modelling for Classics and Cultural Heritage」参加記(後編)」
:ROIS-DS 人文学オープンデータ共同利用センター(CODH) - イベントレポート「TEI2022@Newcastle (UK)」
:ROIS-DS 人文学オープンデータ共同利用センター(CODH) - 編集後記
《巻頭言》「和歌を対象とした古典文学研究と作品データの集積:古典和歌の研究者は何を求めてどのような検討を行っているのか?」
和歌は日本文学の研究領域の中でも、もっとも早くそして大規模にデータ化が進んだ分野である。中学、高校の古典の教科書で目にする、雅やかな気もするけれども堅苦しいようにも思われる詩歌のイメージからすれば、意外に思われる方も少なくないかもしれない。
今からおよそ40年前に紙媒体で刊行されはじめた『新編国歌大観』(角川書店、1983~1992年)には、奈良時代から江戸時代のおよそ1000年の間に詠まれた和歌45万首と和歌の詠まれた状況を説明した詞書とよばれる散文部分が収められ、時代の変遷とともに CD-ROM、DVD-ROM、オンラインと媒体を変えて継承されて来た。日本古典文学の領域でこれほどの規模のデータベースを有するジャンルは外にはない。
データの整備が他ジャンルに先行して進められたのは、和歌そのものの性格と密接に関係している。実は同一テーマを主題とした和歌を諸書から抜き出してインデックス化したり、詠まれた言葉を抜き出して辞書化したりすることは平安時代後期頃(12世紀後半頃)から行われていて、検索システムとしての索引のようなものも鎌倉時代頃(13世紀頃)から作成されている。和歌を創作するためには秀逸な先行作品を学び、それらに用いられた語彙やフレーズを有効的に再利用して自作に取り込む必要があった。そうした作業の利便性確保のために資料の整理が進められたのである。
先行する作品との関わりの中で新たな表現の獲得が模索されてきた和歌の歴史を辿り、その表現の推移を理解するためには、詠み込まれた言葉がどのような先行作品あるいは同時代作品の影響下にあるのか、その言葉を用いることにはどのような表現効果が期待されているのか、といった語彙やフレーズの由来の詮索とその表現の史的展開についての分析は必須であり、そうした作業を通した作品理解は、現在の和歌研究においても中心的課題であり続けている。和歌は類型的性格の強い文学であり、ある作品と先行する作品との相互関係を理解するための語彙のマッチングは、何より先に行われなければならない作業なのである。きわめて単純化して述べるのならば、こうした言葉それ自体の分析に、和歌を詠んだ作者の生きた時代、身分の差異、男女の別、作品に詠まれる主体の男女の別、所属する流派などの諸要素に関わる情報を掛け合わせて、その表現や作品が和歌の歴史の中にどのように位置付けられるのか、どのような意義を有しているのか、といったことの検討がまずは問われるべき課題として研究者に共有されているのである。
和歌の表現の問題に目を転じてみると、和歌はたった31文字で構成される極めて短い文学作品ではあるけれども、その1首が伝えようとする内容は31文字の範囲に収まらない。目の前にある語彙やフレーズが担ってきた表現の層を読み取ることで、その外へと連想が広がってゆくことが、作者にも読者にも期待されているのである。例えば、「宇治」と「橋」の組み合わせには、「我を待つらむ」(私をまっているのだろう)と『古今集』(905年成立)に詠まれた恋人を待つ「橋姫」の恋慕のイメージを重ねて読み取ること常套であった。地名としての「宇治」も物質名としての「橋」にも恋愛の要素はまったく含まれてはいないのにである。語彙やフレーズを起点として先行作品を介在させて広がる連想のネットワークは、連歌や俳諧といった和歌に後発した文芸においては、作品を成立させる知的基盤となっていて、言葉相互の関係性を学ぶためのマニュアルとして、『連珠合壁集』(室町時代成立。連歌に詠まれる言葉の連想体系を説明した書物)、『俳諧類舩集』(1676刊。同様の事柄を俳諧に対応した書物)といった先行する作品の語彙を収集して解説を付した書物も作成されている。
文字列のマッチングを越えて、次々と繋がってゆく連想のネットワークの広がりをどのように捉え、どのように理解するのか。また、その全体像と歴史的変化をどのように説明するのかは、和歌をはじめとする韻文文芸の研究に共通の大きな課題でもある。そして何よりも、ある固有の表現に人はなぜ美を認識するのか、また、そうした表現はなぜ時空間を越えて人々の記憶に定着し再利用され続けるのかといった、人と文学との関係性のあり方についての一見素朴な疑問に対する検討は、古くから問われてきたものでもあり、また人間の認知を対象とした検証という現在的な新しさをも内在する本質的なテーマでもある。
和歌に限らず、漢詩、連歌、俳諧、狂歌、川柳といった韻文文芸を対象とした研究には、研究手法や目的にも類似するものがあり、テキスト分析の手法との相性がよい。実際に近年、情報学分野からも和歌に詠まれた語彙を素材とした研究報告が行われており、データ処理の方法や結論の示し方など学ぶところも多い。しかしながら、研究者相互の交流が殆ど行われていないこともあり、和歌研究者の側にはそうした成果や情報がなかなか届きにくい(おそらくそれと同様に、テキスト分析を直接の研究対象としている研究者の側も、和歌を専門とする研究者と目的意識や方法を共有することは難しい状態にあるのではないだろうか)。それに加えて、日本古典文学を対象とした研究は、概して個別の事例の精緻な分析に基づき演繹的に総体を説明する傾向にあり、データ総体の分析から帰納的にその性格や特質が説明されることは案外多くはない。古典和歌研究においては、n-gram による処理を通して平安時代の和歌表現に固有の男性性/女性性が検討された重要な先駆的研究(近藤みゆき『王朝和歌研究の方法』笠間書院、2015年)はあるものの、やや孤立した存在でもある。志向の違いに由来する両者の間の溝は依然として存在している。
稿者の現在の所属における職務が日本古典籍に関するデータ集積とそれを基盤とした研究領域の開拓に関わることもあって、古典和歌を含む日本文学研究者に対しては、人文情報学、情報学の研究者の助力を得て、その協働の切り開く未来像について機会を得て説明を行ない、意見交換を行ってきた。あらゆる分野でデジタル化とデータ蓄積が進む現在、文学研究においても大規模データは研究の前提とならざるを得ない。むしろ、データの大規模化と分析手法の革新こそが、新たな研究手法の獲得やテーマの創出といった研究の次世代を生み出してゆく可能性を秘めている。こうした従来のあり方とは相反する方向性についても、人文学の研究者側の理解も以前よりは格段に進展しており、また自覚的になってきている印象がある。この人文情報学月報を読まれている人文情報学、情報学の研究者・専門家の方々にも、外部からはおそらく閉鎖的に見えるであろう文学研究、とりわけ古典和歌研究の目的意識や手法が幾分でも伝わり、両者の間に横たわる溝を埋めつつ今後の具体的な展開へと繋がることを期待し、またそのための取り組みも継続してゆきたく思っている。
執筆者プロフィール
《連載》「Digital Japanese Studies 寸見」第91回
「明治期官僚・官職データベース(國岡 DB)、Web UI 版を公開」
2022年10月11日、鹿児島大学司法政策教育研究センター(以下、同センター)は、明治期官僚・官職データベース、通称國岡 DB のウェブ版を公開した[1][2]。これは、同センターの特任講師を務める國岡啓子氏(以下、同氏)の作成してきた同データベースをウェブで利用できるようにしたもので、これまでは Excel 版が提供されてきたものである[3][4]。
Excel 版は、2020年に ver. 1.1が公開されたのがもっともふるい記録である[5]。大幅に増補された ver. 2.0の出た[6]翌年に取材した南日本新聞によれば、このデータベースは、同氏が明治期の国や県の職員録を入力し、名寄せを行ったものであり、同氏と旧知の同センター長である米田憲市氏が公開を引き受け、同センターウェブサイトが公開事務を受け持ち公開されたものだったという[7]。
Excel 版 ver. 2.1によってデータの特徴を述べたい。國岡 DBは、慶応4年から明治44年5月までの国政府職員・府県政府職員の職員録を集成し、文官・武官(明治18年まで)・地方官の表を作ったものである。帝国大学(前身組織を含む、つまり東北大とあるのは札幌農学校と東北帝大農科大学との卒業者のみである)、文官高等試験などに及第したかどうかをまとめ、集約した情報を示している。各種人名辞典も駆使して出典が事細かに記され、名寄せしきれなかったものは、参考として示されている。
今回のウェブ版は、この Excel 版の情報の一部をウェブで検索できるようにしたもので、Excel 版と異なり、利用者登録が不要となっている[8]。Excel 版は引き続き利用者登録を行ってから利用できる(費用は徴していない)。ウェブ版の特徴としては、Excel のデータをもとにした在籍年表が視覚化されているところで、出典情報も見やすくなっている。人名や職位は、それをキーとした検索へのリンクとなっており、検索を進めていくことができる。
個々の人物に固有のアドレスは固定されておらず、リンクを貼ることができないため、ウェブ上の典拠情報として参照できないのは残念である。これができれば、たとえば、同趣のデータベース、たとえば名古屋大学大学院法学研究科で提供されている『人事興信録』データベース[9]との連携などを図ることができる。この『人事興信録』データベースは、民間の発行する紳士録で[10]、親族や経歴を記述している点で補い合うものであることは疑いない。たんに人物の所属の移動というだけでなく、地理情報という観点からの検討も有益だろうと思うので、そうすると、ROIS-DS-CODH の歴史的行政区域データセットとの連環なども発展的には考えられるのだろう[11]。
このような発展は、個々のデータベースに機能を追加していくことでも不可能ではないが、むしろ、文献の情報のデータベースを集約して作られるデータベースがあることが望ましい。どこに集約するかは大きな問題ではなく、いっそ Wikidata[12]でもよいが、どのように集約していくか(リンクをどう安定させていくか)などはすぐれてデジタル人文学的な課題でありうる。
國岡DB は歴史系の学会でもまだあまり報告がされていないようであるが、情報処理学会人文科学とコンピュータ研究会などの場で報告がされれば、その方面からの発展をさらに期待することができるものと思われる。ぜひ伺いたいものと思う。
News | 鹿児島大学司法政策教育研究センター https://lawcenter.ls.kagoshima-u.ac.jp/news.html。
組織 | 鹿児島大学司法政策教育研究センター https://lawcenter.ls.kagoshima-u.ac.jp/staff.html。
明治期官僚・官職データベース ver.1.1の提供のお知らせ| 鹿児島大学司法政策教育研究センター https://lawcenter.ls.kagoshima-u.ac.jp/report/2020/2020meijikannryoudatabase.html。
明治期官僚・官職データベース ver. 1.1の提供のお知らせ| 鹿児島大学司法政策教育研究センター https://lawcenter.ls.kagoshima-u.ac.jp/report/2021/2021meijikannryoudatabase2.0.html (2021.07.05 明治期官僚・官職データベース ver. 2.0の提供開始のお知らせ)。
明治期官僚・官職データベース ver. 2.1の提供のお知らせ| 鹿児島大学司法政策教育研究センター https://lawcenter.ls.kagoshima-u.ac.jp/report/2021/2021meijikannryoudatabase2.1.html (2021.07.27 明治期官僚・官職データベース ver. 2.1の提供開始のお知らせ)。
「「國岡 DB Web 版」が検索・表示するデータは、Microsoft Excel上で作成されている國岡啓子編「明治期官僚・官職データベースver. 2.22 慶応4年~明治44年5月までの官員録・職員録及び帝大卒業者・資格試験及第者収録版」(略称:國岡 DB2.22)のうち、「官員録・職員録」の部分です。」
「明治期官僚・官職データベース WEB 版」について | 明治官僚データベース https://shokuinroku.ls.kagoshima-u.ac.jp/usage。
『人事興信録』データベースでは、『人事興信録』データベースが個々人のアドレスを設定せず、『人事興信録』各版の項目ごとの ID があるのみ(名寄せできていれば相互リンクはある)状態なので、ウェブ上の情報源として考えたとき、リンクの安定性に欠ける点があるのは惜しまれる。
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第52回
「Hugging Face AutoTrain における最新鋭 AI モデルによるノーコード機械学習」
2022年10月17日、早稲田大学の大隈記念タワーにおいて、Among Digitized Manuscripts: Working with Oriental Manuscripts in the Digital Age というワークショップが開催され、早稲田大学で DHの教育を行っている Emily Ohman 氏の司会のもと、Digital Orientalist 誌[1]の創設者 L.W.C. van Lit 氏(ユトレヒト大学)と編集の中心メンバーの一人である James Harry Morris 氏(早稲田大学)、そして筆者が講演した[2]。van Lit 氏は、2019年に出版された氏のデジタル写本学の著書[3]を紹介した後、写本・手稿本をデジタルに研究するとは何か、その制限と可能性について述べ、Morris 氏は、キリシタン資料のデジタル化の研究について OCR やウェブデータベース化の実例などを見せながら紹介した。そして、最後に筆者は、近年目覚ましい発達を遂げている、深層学習(Deep Learning)および転移学習(transfer learning)による機械学習を人文学にどれほど適用できるかについて、実例を挙げながら述べた。
筆者の発表では、機械学習・深層学習・転移学習の歴史を説明した後、畳み込みニューラルネットワーク(Convolutional Neural Network: CNN)と長短期記憶(Long Short-Term Memory: LSTM)モデルを用いた Transkribus[4]による、沖縄語聖書写本の手書きテキスト認識、回帰的(再帰的)ニューラルネットワーク(Recurrent Neural Network: RNN)と LSTM を用いた係り受け解析、そして、Tranformer や GPT-3による自動応答、XLM-RoBERTa に基づいた Universal Dependencies[5]の枠組みによる係り受け解析のモデルの実演などを行い、最後に Hugging Face社[6]が現在、無償でベータ版を提供している AutoTrain[7]について紹介した。
この AutoTrain では、コードを書くことをせずに、機械翻訳、自動タグ付、画像認識など、様々な機械学習のタスクを、既存の最先端(SoTA: State of The Art)のモデルに学習させることができる。これらのモデルのほとんどが転移学習の仕組みを用いている。転移学習とは、まず大規模な言語データで穴埋め解答のタスクをさせ、言語モデルを得た事前学習済みモデルに、個別タスクを学習させる。事前学習後の個別タスクのための学習のことをファインチューニングと呼ぶ。大雑把に言えば、事前学習とファインチューニングを組み合わせる機械学習方法が、転移学習と呼ばれるものである。AutoTrain では、Hugging Face ハブ上にある様々な事前学習済みモデルを、コードを書くことなしに、ユーザが求める個別タスクでユーザ自らがファインチューニングさせて、ユーザのタスクを自動化することができる。
AutoTrain 上で機械学習を行うには、Hugging Face のアカウントを作成する必要がある。有料のプロアカウントもあるが、無料版でも AutoTrain を使用することが可能である。New Project を選択すると、Vision(画像)、Text(テキスト)、Tabular(表)の3つのカテゴリーから、どんなタスクを学習させるかを選べる。Vision では、Image Classification(画像分類)のみ学習させることができる。Text では、Text Classification (Binary)「テキスト分類(2択)」、Text Classificaion (Multi-class)「テキスト分類(複数)」、Token Classification「トークン分類」、Question Answering (Extractive)「質問応答(Extractive)」、Translation「翻訳」、Summarization「要約」、Text Regression 「テキスト回帰」が選べる。Tabularでは、Tabular Data Classification (Binary)「表データ分類(2択)」、Tabular Data Classification (Multi-class)「表データ分類(複数択)」、Tabular Data Classification (Multi-label)「表データ分類(複数ラベル)」、 Tabular Data Regression「表データ回帰」がある。
学習済みモデルで AutoTrain で使用可能なものは、多言語を学習したものが多い。機械翻訳では T5-large、トークン分類では XLM-RoBERTa、自動応答では GPT2のような人気のモデルを用いることができる。T5やXLM-RoBERTa など BERT から派生してきたモデルは、Transformer のエンコーダ側を用いるエンコーダモデルであり言語データの解析が得意である。Transformer のデコーダ側を用いる GPT のようなデコーダモデルが自動応答や機械作文が得意なのと対比的である。エンコーダモデルでは Masked Language Modelling という手法で学習を行う。ここでは教師データのテキストの一部の単語を隠し(マスクをかけ)、その単語をモデルに答えさせる。そして、答えと正解を照合し、正解を導き出すよう、重みづけをしていく。AutoTrain では、モデル選択において Automatic を選ぶと、日本語、英語、アラビア語などいくつかの主要言語を選択でき、選択した言語に最も適切な事前学習済みモデルが自動で選ばれる。それに対して、Manual を選択すると、ユーザが自分でモデルを検索し、選ぶことになる。
ここでは、Text の Token Classification と Translation について取り上げる。前者では、テキストの各トークン(多くの場合は単語)に品詞などのラベル付けを行う。このファインチューニングに必要なデータは、トークン毎に区切った1列目とそのラベルの2列目の対がある JSONL もしくは CSV ファイルである(図1)。

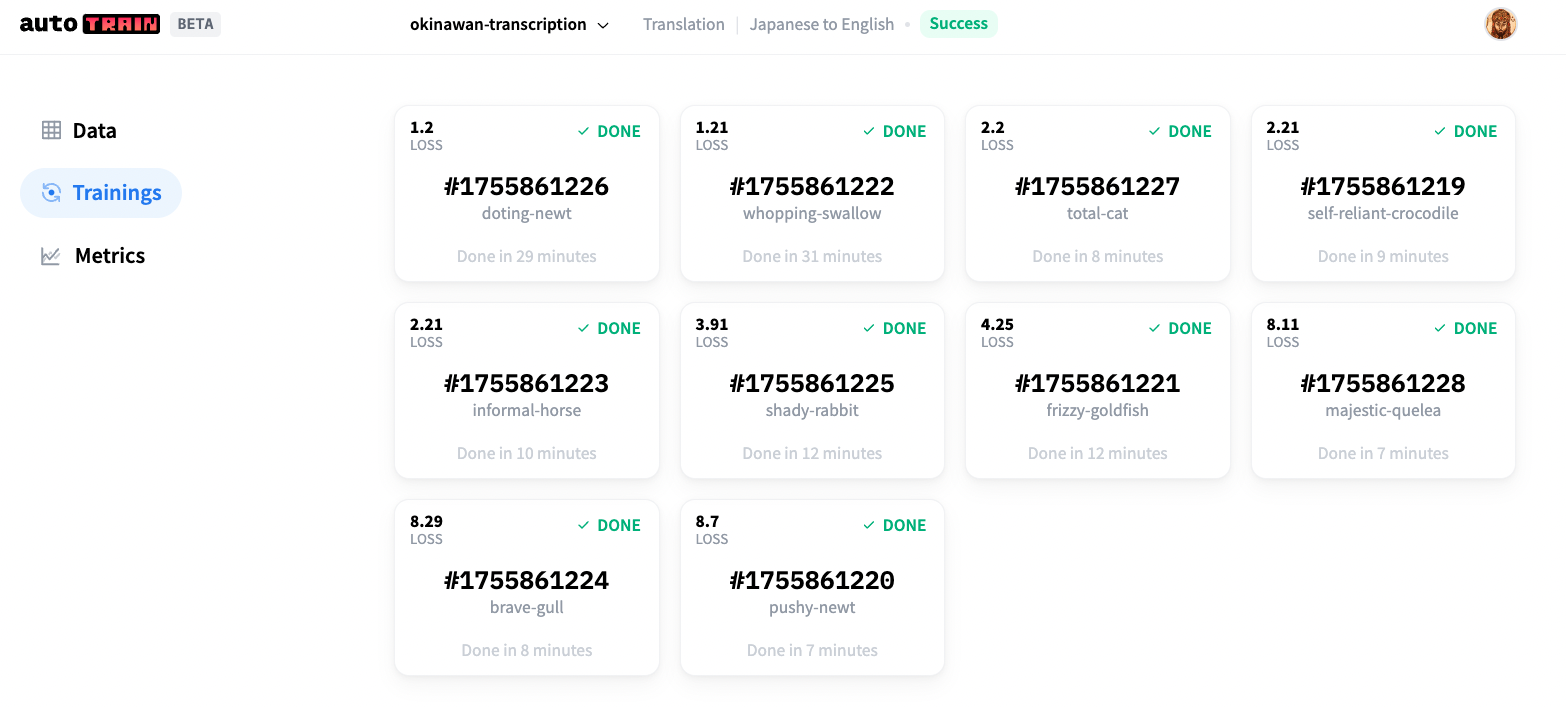
Translation も同形式の教師データが必要となる。1列目に翻訳元のテキスト、2列目の翻訳後のテキストを入力する (図2)。

教師データをアップロードする際に Auto を選択すると一部はモデルの精度を測る検証データに回される。教師データと検証データを別々に選ぶこともできる。この工程が終了すると、生成するモデルの数を選ぶ。5モデルは無料で、10モデルはプロアカウントで無料である。15以上のモデルはどのアカウントでも有償となる。モデル数選択後、学習が始まり、学習中のモデルのうちエラー率が最も低いモデルが、左上に来る(図3)。作成したモデルは、Hugging Face Hub 上に公開され、DOI を付与することができる。
既に事前学習済みモデルがある言語では AutoTrain を十分に活用させることができる。しかし、事前学習済みモデルがない言語ではファインチューニングを行う AutoTrain を用いるのは適していない。良い事前学習済みのモデルを作るには、何千万文、何億文のテキストを学習する必要がある[8]。これには複数の高価な GPU・TPU など、高額な設備と電気代がかかるため一般ユーザには難しく、企業や研究機関などが通常は行う。少数言語のように少ないデータしか持たない言語でどのように学習させるかが、筆者のように危機言語で自然言語処理を行おうとする者にとって課題となっている。同じ書記体系で文法が似ている言語を学習済みのモデルの場合、別の言語に適用してもファインチューニングでどうにかなる可能性があり、筆者は現在この手法を試している。
- コメントを投稿するにはログインしてください