人文情報学月報第156号【前編】
ISSN 2189-1621 / 2011年08月27日創刊
目次
【前編】
- 《巻頭言》「ヒューマニテクスト:西洋古典学とAIの交差」
:名古屋大学デジタル人文社会科学研究推進センター - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第72回
「ギリシア神話研究と地理空間リンクトオープンデータ: MANTO プロジェクトによる Nodegoat の活用」
:筑波大学人文社会系 - 《連載》「仏教学のためのデジタルツール」第20回
「Chaṭṭha Saṅgāyana Tipiṭaka」
:駒澤大学仏教学部
【後編】
- 人文情報学イベント関連カレンダー
- イベントレポート「DHNB2024とアイスランドにおける DH 研究動向」
:東京大学大学院人文社会系研究科・文学部附属次世代人文学開発センター人文情報学部門 - イベントレポート「デジタルヒストリー:概念と実践」
:千葉大学人文公共学府 - お詫びと訂正
- 編集後記
《巻頭言》「ヒューマニテクスト:西洋古典学とAIの交差」
一年前の今頃、私が『人文情報学月報』の巻頭言を執筆することになるとは夢にも思っていなかった。
昨年、私は偶然にも人文情報学に関わる機会を得た。きっかけは、2023年6月に開催された「日本西洋古典学会」におけるフォーラム「西洋古典学とデジタル・ヒューマニティーズ」である。当時、私は名古屋大学に赴任したばかりで、所属する研究科長(周藤芳幸先生)がこのフォーラムの提題者であったこともあり、自然と私は発表者の一人となった。その時には、自らの専門分野である西洋古代哲学の研究のために、西洋古典データベースである TLG(Thesaurus Linguae Graecae)や Perseus Digital Library を恒常的に使っていたものの、人文情報学的な側面で何か貢献ができるとは思えなかった。しかし、当時話題になっていた ChatGPT を少しは触っていたので、それを専門研究にどのように役立てるかという話をしたら面白いのではないかと思い立ち、少しずつ実験を始めた。
このような外的要因で始めた試みではあったが、ChatGPT の有料版に登録し、当時の最新大規模言語モデル(LLM)である GPT-4を使用してみて、大きく心境が変わった。論文だけでなく研究書でさえも、それに関する質問に的確に返答してくるのである。さらに、古典ギリシア語やラテン語もかなりの程度正確な日本語に訳すことができるのだ。ChatGPT では読み込ませるテクストの分量に制限があったが、その制約に縛られないシステムを作れば、これまで不可能であった大規模なテクスト分析による領域横断的な研究が実現するかもしれない。こうした趣旨の発表を行ったところ、同様のビジョンをもっていた桜美林大学の田中一孝氏と国立情報学研究所の小川潤氏と意気投合し、西洋古典に特化した対話型 AI システムを開発することになった。
こうして始まった対話型 AI システムは「ヒューマニテクスト」(英名:Humanitext Antiqua)と名付けられた。このプロジェクトの目的は、信頼できる西洋古典の原典テクストに基づいて回答を出力するシステムを開発することである。最初に取り組んだのは、先に挙げた Perseus Digital Library のテクストデータを、LLM に読み込ませるのに適したまとまりに分割し、ベクトルデータ化することだった。テクストの意味をこのように数値化し、その近似値によって文脈の近さを測るという検索の手法は、私にとって非常に衝撃的であった。今まで一つ一つ手作業で確認するしかなかった文脈の相違を自動で処理する未来が開ける。まだ改善の余地は大きく残されているものの、あまりよく知らない原典から自分の知りたい箇所を取得できるという点では、既に研究に実用的なレベルである。それも英語のビジネス文書ではなく、古典ギリシア語やラテン語の抽象度の高い原典で、このような意味に基づく検索ができてしまうのだ。今後、人文学の多くの分野においても、この RAG(Retrieval-Augmented Generation)という手法が急速に普及するに違いない。
システム開発は、約一年の期間を経て、翌年の学会でその成果をデモ公開できるまでに成長した。しかし、その道のりは決して平坦ではなかった。今でこそユーザーが質問を送信してから、ものの2~3秒で回答が出力され始めるが、最初のプロトタイプでは1分以上の時間がかかった。その改善には、外部ベクトルデータベースの活用、インターフェースの刷新、アプリケーション・プラットフォーム上での公開などが大きく寄与している。また、開発当初にはほんの数行しか出力されなかった LLM の回答も、現在ではかなり詳しいテクスト分析までできるようになっている。この点については、メンバーによるプロンプト・エンジニアリングの試行錯誤もさることながら、最新 LLM である GPT-4o の性能の高さが主な要因である。今年の5月に公開されて直ちに導入したところ、出力の質が大幅に向上し、システムの公表に向けて大きな弾みとなった。
完成した AI 対話システム「ヒューマニテクスト」は、ChatGPT などの生成 AI の使用において広く問題になっている偽情報(ハルシネーション)の問題を可能な限り対処していることが特徴である。通常の生成 AI は基盤 LLM の学習データに基づいて回答を生成するが、その学習データはインターネット上から幅広く取得されたものであり、そのソースが誤っている可能性が十分にある。これに対し、ヒューマニテクストは信頼できる原典テクストのみをソースとして回答を出力するようになっている。また、LLM による出力は、前に続く言葉として確率の高いものが選択されているに過ぎず、内容の正誤に基づいて決定されているわけではない。この事実を変えることはできないが、私たちは毎回の出力の際に情報の出処を明確にすることで、ユーザーが直ちに原典と照らし合わせてその正誤を判定できるようにした。これらの機能は研究者にとって非常に重要であり、信頼性の高い研究を実施するために必須のものである。
文献の精読が求められる西洋古典の分野において、AI による解釈が入り込む未来など想像もしていなかったが、今ではそれが現実のものとなってきていることを実感している。現状では、研究者の存在意義を脅かすような、精緻なテクスト分析や複雑な論理の再構成などは実現できていない。しかし、現在の LLM の急速な進化を考えれば、近い将来にそれが可能となることは決して絵空事ではないだろう。これまで指摘されてこなかったテクストの関連性を探る研究や、ある概念が登場するリファレンスを整理するような研究は、今でもかなりの程度 AI に代替されうる。このような状況の中、私たちは文献学的な研究を今後どのように進めるべきなのか、AI の技術的な進展を十分考慮して、真剣に検討しなければならない。
ヒューマニテクストは、西洋古典学においてもいまだ連携すべき数多くの作品を残しており、RAG の精度向上により、より正確で文脈に即した回答を生成することが重要である。これには、各作品の文脈や歴史的背景を深く理解し、それに基づいた回答を提供するためのアルゴリズムの改良が含まれる。また、研究者による論文や研究書を組み込んでいくことは今後の大きな課題である。最終的には、このシステムをさらに進化させ、古今東西の知を集積するプラットフォームを作り上げることが目標である。このプラットフォームを通じて、日本の人文学が世界中で認識され、国際的な理解と交流が一層深まることを期待している。例えば、日本の思想や研究が西洋の学術界においても広く研究されるようになり、異文化間の新たな対話が生まれることを目指している。
今後のヒューマニテクストの普及は、私たちの研究だけでなく、教育現場や一般のユーザーにも大きな影響を与える可能性を秘めている。西洋古典の知識は専門家だけのものではなく、誰もがアクセスできるものであるべきだという理念のもと、私たちはこのシステムを広く公開することを目指している。しかし、現時点では OpenAI 社の LLM 使用料がネックとなっており、無料での公開には課題が残っている。将来的には、オープンリソースで公開されている大規模言語モデルを活用し、誰もが利用できるシステムを構築する予定である。
このプロジェクトを通じて得た経験は、私にとって非常に貴重なものであった。デジタル技術と人文学の融合が生み出す新たな可能性に触れることで、研究の幅が広がり、これまでになかった交流が生まれた。今後もこのような取り組みを続け、より多くの人々に人文学の魅力を伝えていきたいと考えている。
執筆者プロフィール
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第72回
「ギリシア神話研究と地理空間リンクトオープンデータ: MANTO プロジェクトによる Nodegoat の活用」
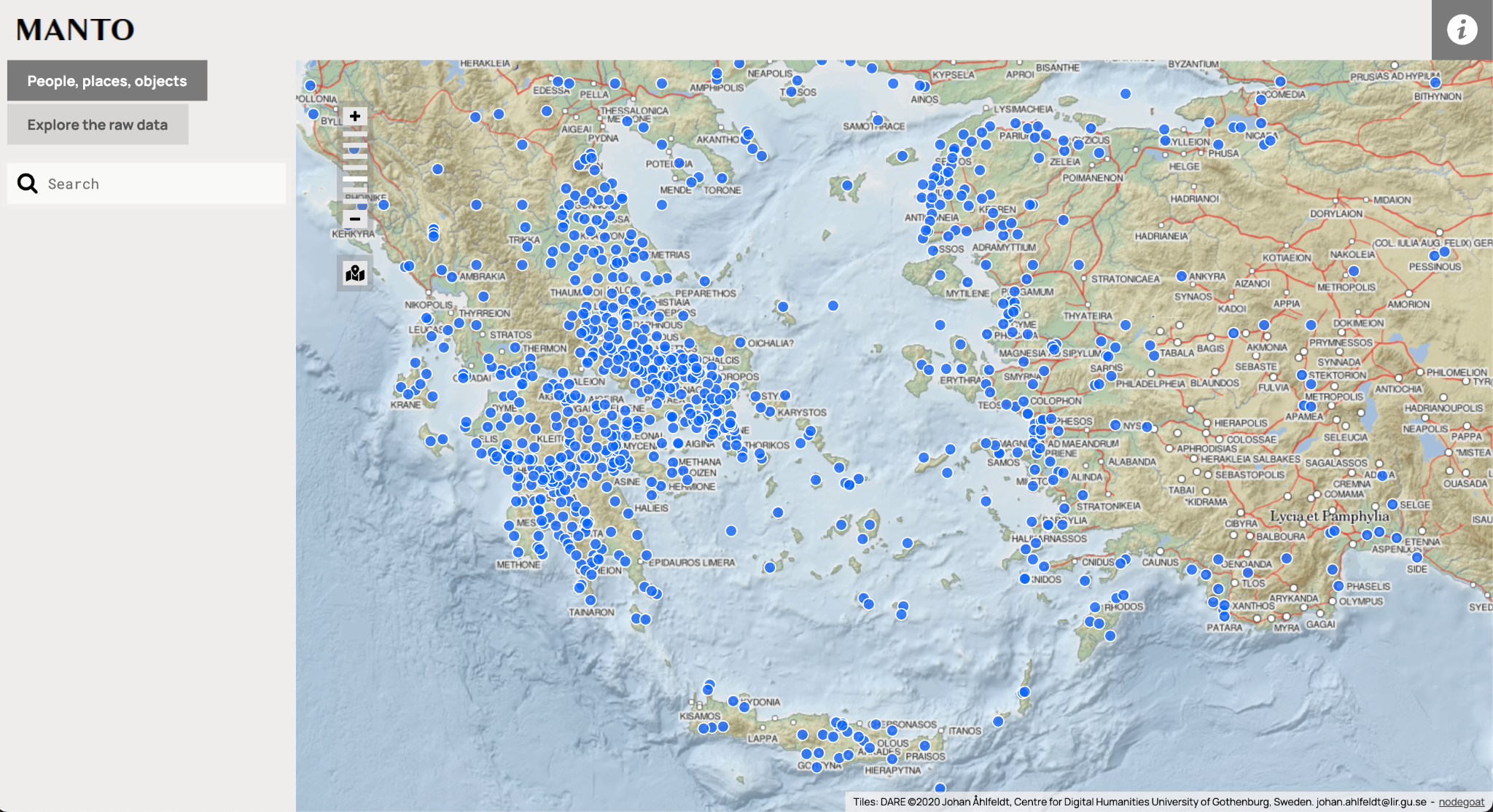
デジタル・ヒューマニティーズの分野において、近年注目を集めているプロジェクトの一つが MANTO[1]である。MANTO は、ギリシア神話のデジタルポータルである MYTHLAB の一部であり、2500年以上にわたる神話の伝統のインタラクティブな学習・研究を可能にすることを目的としている。MANTO では、地図や時代、人物・神々間のネットワークグラフなど様々なインタラクティブなツール(図1)を使いながら、神話自体や、神話に登場する人物や土地、重要概念などの地理的・歴史的・相関的な関係性を調べることができる。
この MANTO プロジェクトは、2017年後半、アメリカ合衆国のニューハンプシャー大学の R. Scott Smith 教授とオーストラリアのマッコーリー大学の Greta Hawes 教授によって始められたものである。両教授は当初、デジタルツールの使用経験に乏しかったが、ギリシア神話を新たな視点で捉え、幅広い層に役立つツールの創造を目指していた。
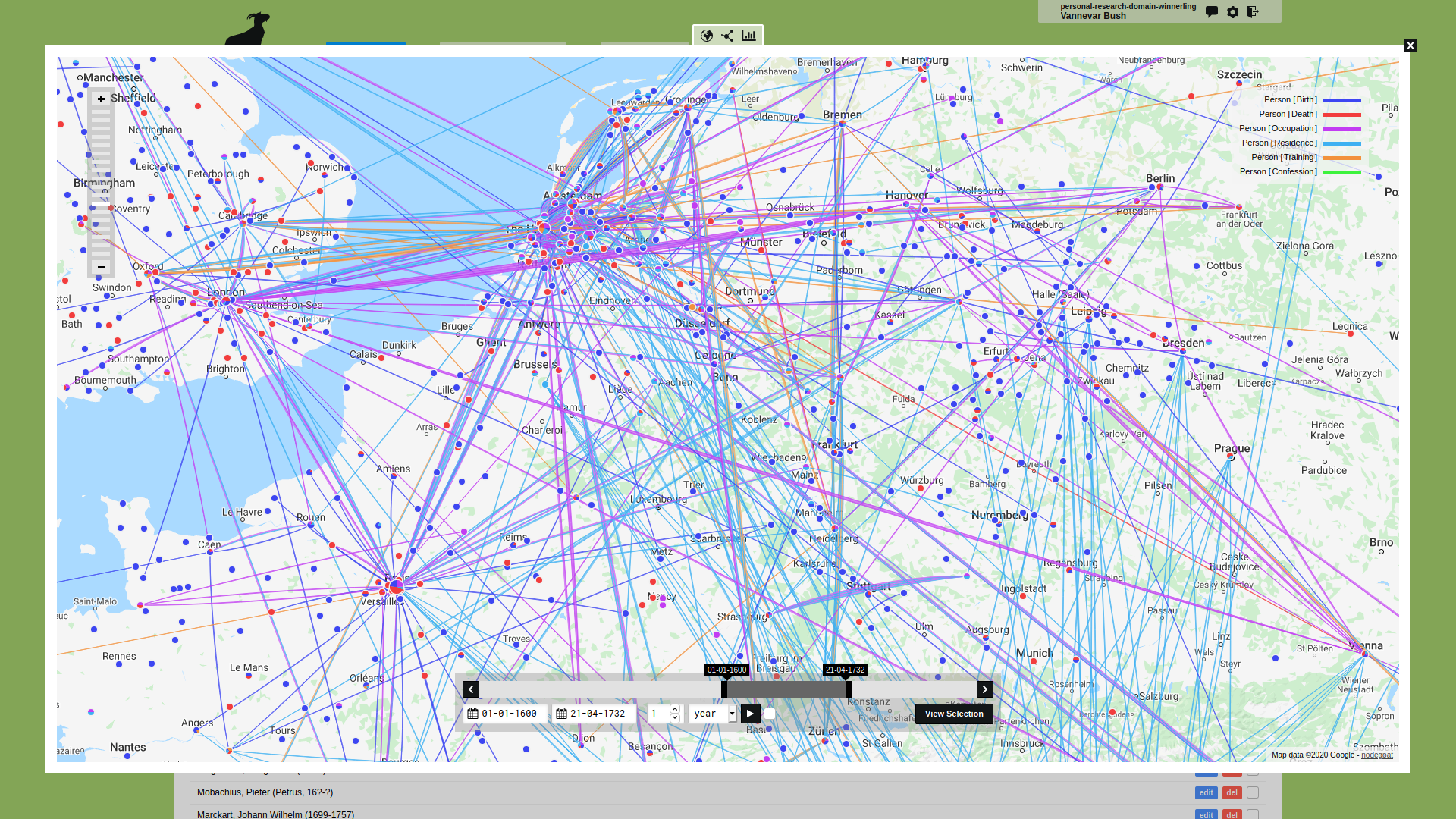
そんな中、Hawes 教授は、Nodegoat[2]というデータプラットフォームを発見し、検討の結果、このツールを使用することを決断した[3]。Nodegoat は、2011年にアムステルダム大学の Joep Leerssen 教授の支援のもと開発が始まった、ウェブベースのデータ管理・ネットワーク分析・可視化環境である。技術的な専門知識が乏しい MANTO チームにとって、Nodegoat は信頼性が高く、費用対効果に優れ、プロジェクトの特定のニーズに合わせて正確にカスタマイズできる理想的なデータ収集環境を提供した。
Nodegoat は、ヨーロッパを中心に、デジタル・ヒューマニティーズ分野において広く活用されているツールである。その中核機能は、研究者が独自のデータモデルを構築できることにある。これにより、個人または共同でデータセットを作成・管理することが可能となる。さらに、すべてのオブジェクトに時間的・空間的コンテキストを付与できるため、歴史的な深層マップの作成や独自のガゼッティア(地名辞典)の構築も実現できる。
Nodegoat は、関係性のパターンや中心的なノードを明らかにする内蔵のネットワーク分析ツールも提供している。加えて、地理的可視化や社会ネットワークの可視化を通じて、時間の経過に伴うデータの変化を探索することも可能である。また、SPARQL エンドポイントや API リソースを設定することで、外部のリンクトデータリソースとの連携も実現できる。
欧州の様々なプロジェクトにおいて、Nodegoat は幅広く活用されている。例えば、ベルン大学の Repertorium Academicum Germanicum[5]プロジェクトでは、中世後期から近世初期のドイツ語圏の学者のデータベース構築に利用されている。ルーヴェン・カトリック大学の Global Academies: Scientific Societies and the Globalization of Science (1930–1990)[6]プロジェクトでは、科学のグローバル化の研究に活用されている。
このように、Nodegoat は歴史学、文学、社会学など様々な人文科学分野での研究を支援している。データの構造化、分析、可視化を一つのプラットフォームで行えることが、その強みとなっている。
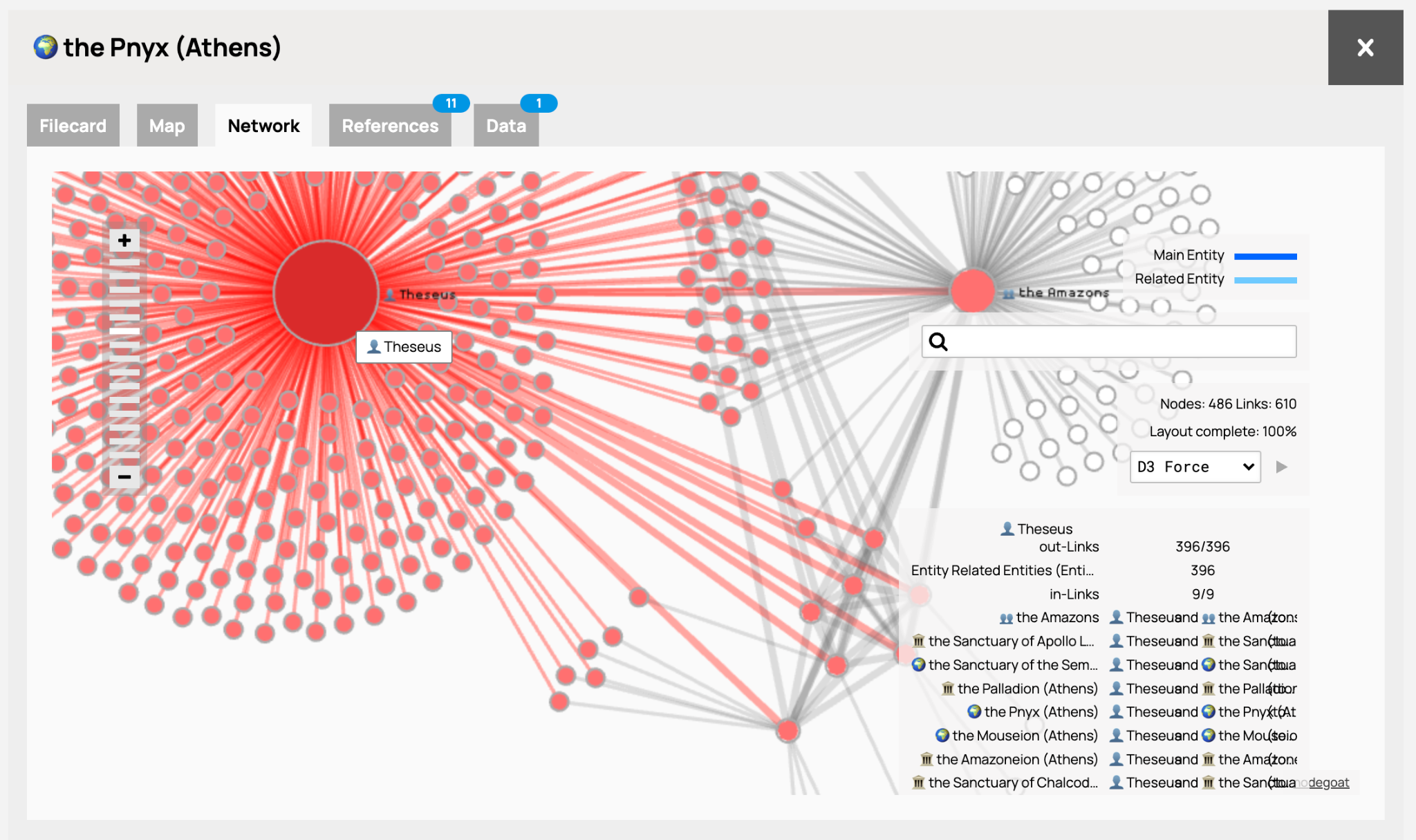
MANTO チームは Nodegoat を活用し、ギリシア神話に登場する人物、場所、物体、出来事を識別し、神話の語りの現象を反映した独自の「関係」語彙でつなぐことに成功した(図3)。Nodegoat の柔軟なデータモデリング機能により、MANTO は独自のデータモデルを構築することができた。さらに、データを安定した URI で公開し、API や CSV ダウンロードで共有可能にしたことで、ギリシア神話について大規模な分析や古代の語りの文脈の理解が可能になった。
MANTO のもう一つの特徴は、リンクトオープンデータ(LOD)の手法を積極的に取り入れている点である。LOD とは、構造化されたデータをウェブ上で公開し、それらを相互にリンクさせることで、データの検索性や再利用性を高める取り組みである。
MANTO は、Pelagios Network[7]のパートナーの一つでもある。Pelagios Network は、歴史的な場所に関する情報をリンクし、探索するためのセマンティックアノテーションの使用を支援し、場所や人物に関する構造化された LOD の標準化を目指している。Pelagios Network と MANTO の連携により、MANTO のデータを他のツールで活用したり、ウェブ上の他のデータと接続したりすることが可能になった。
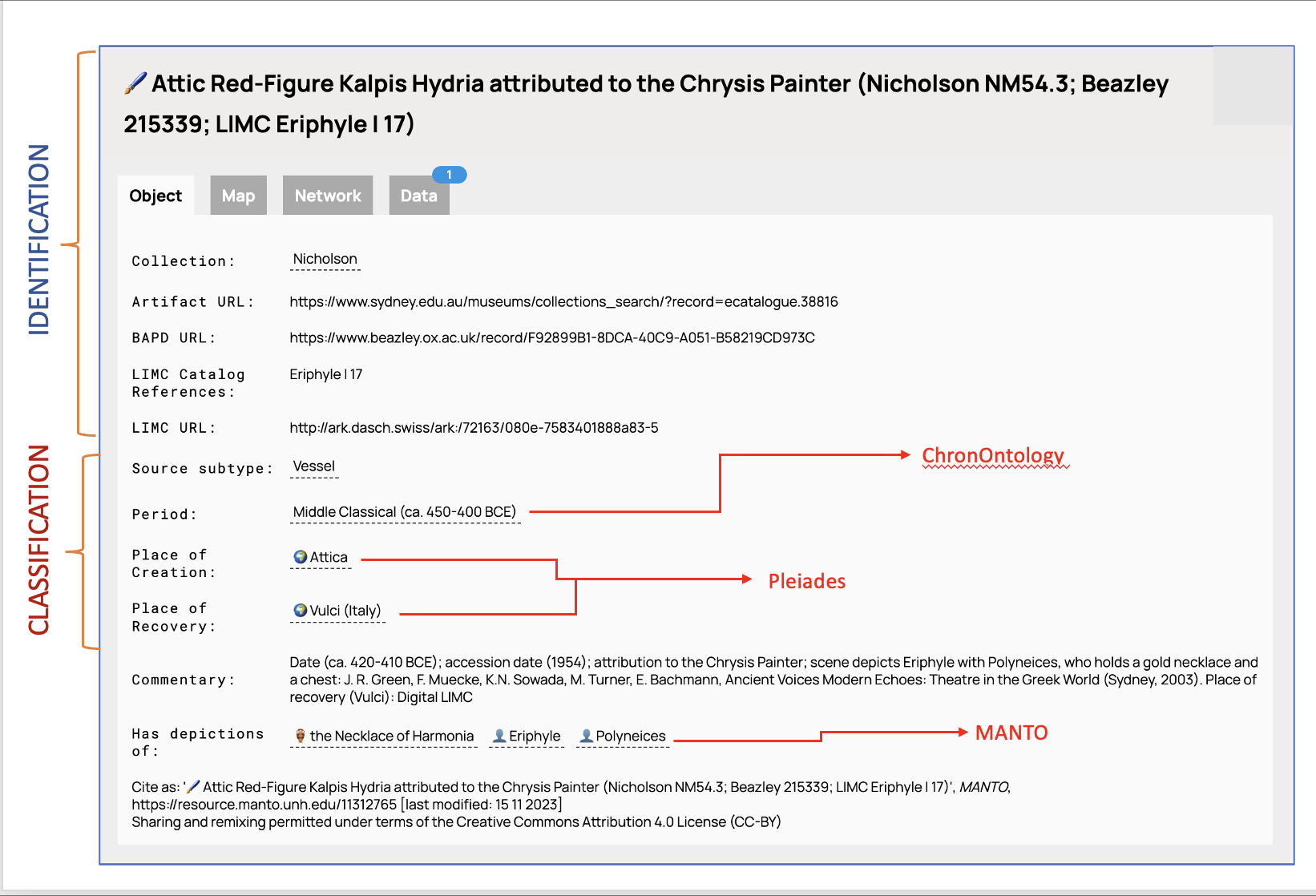
例えば、MANTO は、オープンアクセスのデータリポジトリである Open Context に公開されているテル・ケデシュ(Tel Kedesh)遺跡で出土した印章に関するデータ[8]を容易に取り込むことができた。これは、印章に描かれた神々や英雄が MANTO のエンティティと整合されていたからである。
また、MANTO は、ギリシア神話の地理情報を可視化する際に、ローマ帝国の地理情報を提供する Digital Atlas of the Roman Empire(DARE)[10]のデジタル地図をベースマップとして活用している。DARE はクリエイティブ・コモンズ・ライセンスの下で公開されており、ヨーテボリ大学の Johan Åhlfeldt 氏が中心となって開発している。
MANTO の事例は、デジタル・ヒューマニティーズがもたらす学際的な研究の可能性を示すものでもある。デジタル技術を活用して人文学の研究対象をデータ化し、構造化することで、従来は見えなかった関係性を明らかにすることができる。また、データの公開と共有を進めることで、国境を越えた研究者間の協働を促進することもできる。
MANTO に代表されるようなプロジェクトは、人文学研究のあり方そのものを変革しつつある。デジタル・ヒューマニティーズは、単なる技術の応用ではなく、新しい研究の方法論であり、知の体系化の試みである。MANTO の挑戦は、古代ギリシア神話という一見すると現代からは遠い研究対象においてさえ、デジタル技術がいかに新たな扉を開くかを示している。
MYTHLAB のポータルには、MANTO の他に、ギリシア神話の教育のための記事を多数掲載している Greek Myth Files[11]、そして、ピア・レビューによる高品質の翻訳を提供している Canopos[12]などがある。MANTO を含む MYTHLAB の取り組みは、デジタル・ヒューマニティーズの可能性を大いに示すものである。リンクトオープンデータを活用した、学際的で協働的な研究スタイルは、人文学の新たなスタンダードになりつつある。本プロジェクトは、神話研究という枠を超えて、デジタル時代の人文学の在り方そのものを問いかけている。
《連載》「仏教学のためのデジタルツール」第20回
仏教学は世界的に広く研究されており各地に研究拠点がありそれぞれに様々なデジタル研究プロジェクトを展開しています。本連載では、そのようななかでも、実際に研究や教育に役立てられるツールに焦点をあて、それをどのように役立てているか、若手を含む様々な立場の研究者に現場から報告していただきます。仏教学には縁が薄い読者の皆様におかれましても、デジタルツールの多様性やその有用性の在り方といった観点からご高覧いただけますと幸いです。
「Chaṭṭha Saṅgāyana Tipiṭaka」
はじめに
Chaṭṭha Saṅgāyana Tipiṭaka (CST) は Vipassana Research Institute (VRI) からリリースされているパーリ語文献 (上座部仏教の聖典言語であるパーリ語で記された仏教文献群)の検索および読解のためのソフトウェアである。パーリ語文献を研究する上で有用な機能を備えているため、パーリ語文献の研究者でこれを使用しない者はいないと言ってよいだろう。以下、CST が開発された背景、CST の利用方法、CST が抱える問題の三点について簡単に説明し、今後のパーリ語文献研究における CST の位置づけについて私見を述べたい。
CSTが開発された背景
CST をリリースしている VRI は、ヴィパッサナー瞑想のためのセンターである Vipassana International Academy (VIA) により1985年にインドのマハーラーシュトラ州イガップリ (Igatpuri) に設立された研究機関である。その名が示す通り、ヴィパッサナー瞑想に関する研究を目的とした組織であり、パーリ語文献に基づきヴィパッサナー瞑想の起源と応用について研究することを目的としている[1]。
この目的のために、VRI が最初に取り掛かったのが、パーリ語文献をインドで広く用いられるデーヴァナーガリー文字で出版することであった。設立から5年後の1990年、デーヴァナーガリー文字版パーリ語文献を出版するためのプロジェクトを始動し[2]、1993年から1998年にかけてパーリ語文献140冊を出版した[3]。このように短期間で出版を終えることができたのは、ビルマ第六結集版を底本とし、それをビルマ文字からデーヴァナーガリー文字に転写することで制作したからである。パーリ語文献には他にも Pali Text Society (PTS) 版、タイ王室版、シンハラ版 (Buddha Jayanti 版)など複数の版本があるにもかかわらず、何故、ビルマ第六結集版を底本として採用したかと言えば、VIA および VRI の創設者ゴエンカ(1924~2013年)がミャンマー出身であるとともに[4]、彼の実践するヴィパッサナー瞑想がレディ・サヤドー(1846~1923年)に遡り[5]、ミャンマーの上座部仏教に端を発するものであったからであろう。
このデーヴァナーガリー文字版パーリ語文献を出版するにあたり、VRI はコンピューターを用い、ビルマ第六結集版をデーヴァナーガリー文字で入力し、デジタルテクストを作成していたようである。そのデジタルテクストを応用することで、当時の CD-ROM の普及に合わせて、CST の前身である Chaṭṭha Saṅgāyana CD-ROM (CSCD) が制作され、1997 年にリリースされた[6]。デーヴァナーガリー文字以外にローマ字でも表示でき、検索機能にも優れていたため、次第に多くのパーリ語文献研究者が研究に利用するようになっていった。ただし、最初期のバージョンは Windows パソコンでのみ利用できるものであった。また、テクストの表示および全文検索のためには、VRI Roman Pali fonts という特殊なフォントをパソコンにインストールする必要があった。
その後、徐々にバージョンアップが進み、ソフトウェアの取得方法は CD-ROM からインターネットでのダウンロードへと変更された。2008年にリリースされた CSCD version 3では Unicode への対応がなされた[7]。そして、2022年にリリースされた version 4からは名称が CSCD から CST へと変更された。最近では iOS での利用も可能となった。
CST の利用方法
2022年3月にリリースされた最新版の CST version 4.1は https://tipitaka.org/cst4 から無料でダウンロードすることができる(iOS 向けのアプリは https://tipitaka.org/webapp からダウンロードすることができる)。ダウンロードの終了後、セットアップファイル(setup.exe)を開き、パソコンにインストールすれば、すぐに利用が可能となる。必要に応じて、https://tipitaka.org/keyboard.html から Pāli Keyboard をダウンロードして、パソコンに追加するとよいだろう(筆者は「English (US) + Pali」を追加した)。
CST の利用方法については、https://tipitaka.org/cst4 の下部にあるデモンストレーション動画で詳しく説明されているので、ここではごく簡単な説明にとどめたい。先ず、テクストの開き方であるが、ブラウザー左上の 「Book」というタブをクリックし、更に 「Open」をクリックすると、以下のように「Select a Book」というウィンドウが現れる。
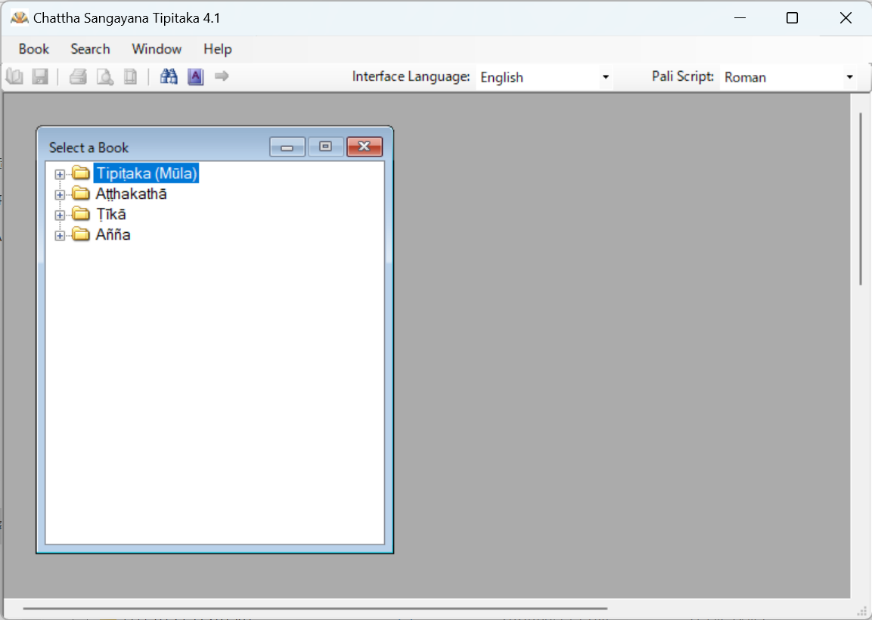
そこから文献を選び、クリックすると、以下のように新たなウィンドウが現れ、テクストが表示される。
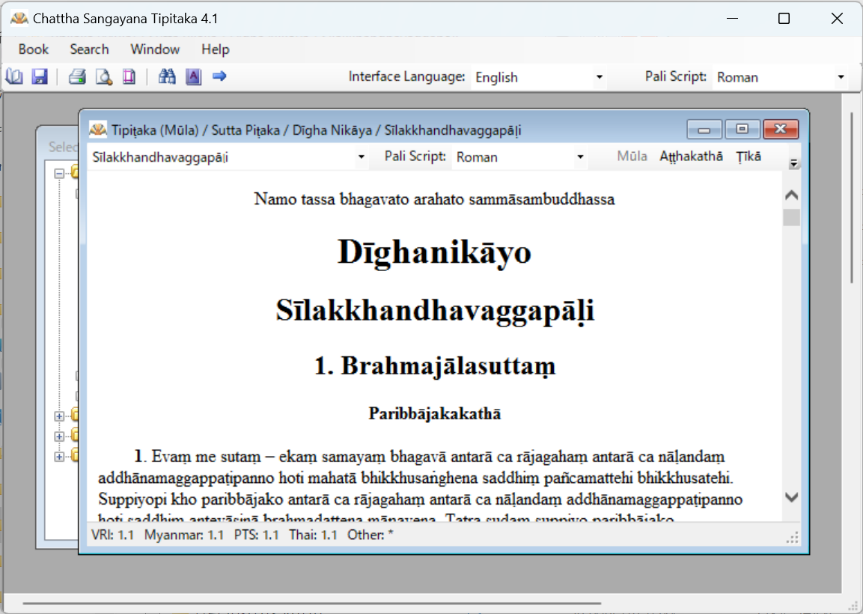
テクストのウィンドウの下部には、「Myanmar」=ビルマ第六結集版、「PTS」=PTS 版、「Thai」=タイ王室版の対応箇所の巻数・頁数が記されている。また、右上部には 「Aṭṭhakathā」(注釈書)と「Ṭīkā」(復注釈書)というタブがあり、これをクリックすると新たなウィンドウが現れ、当該箇所に対する注釈書または復注釈書の注解部分が表示される。
次に、検索の仕方についてであるが、ブラウザー左上の「Search」というタブをクリックし、更に「Word」をクリックすると、以下のように「Search」というウィンドウが現れる。
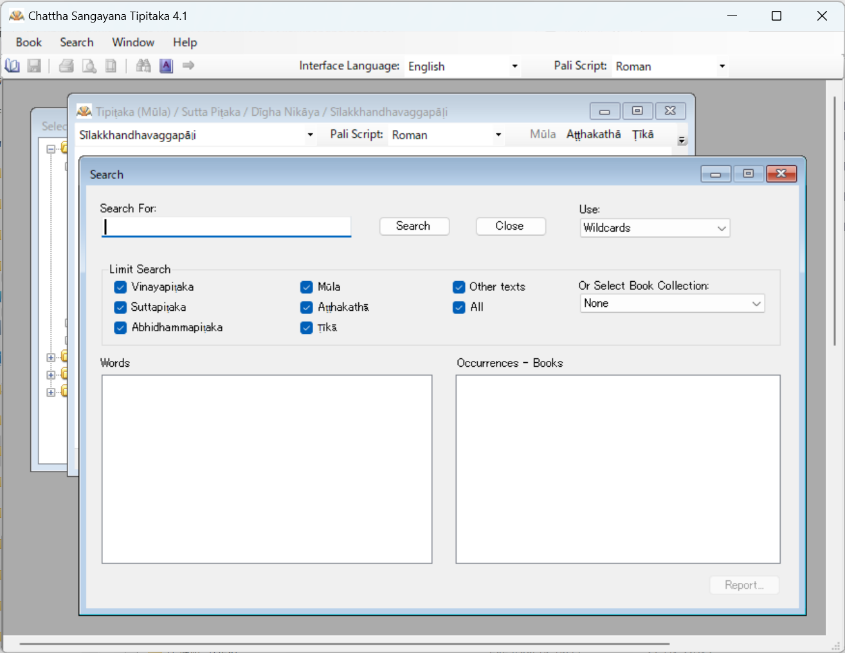
「Search For」という文字列の下にある検索バーに検索語句を入力し、「Limit Search」と記されている部分で検索範囲を定めて検索を行う。正規表現による検索もできるが、ワイルドカードによる検索が標準設定となっている。例えば、検索範囲を「Vinayapiṭaka」(戒律聖典)に絞って、「vinayadhara」(戒律専門家)という語についてアスタリスクを用いて前方一致のあいまい検索をしてみると、次のような検索結果が出るだろう。
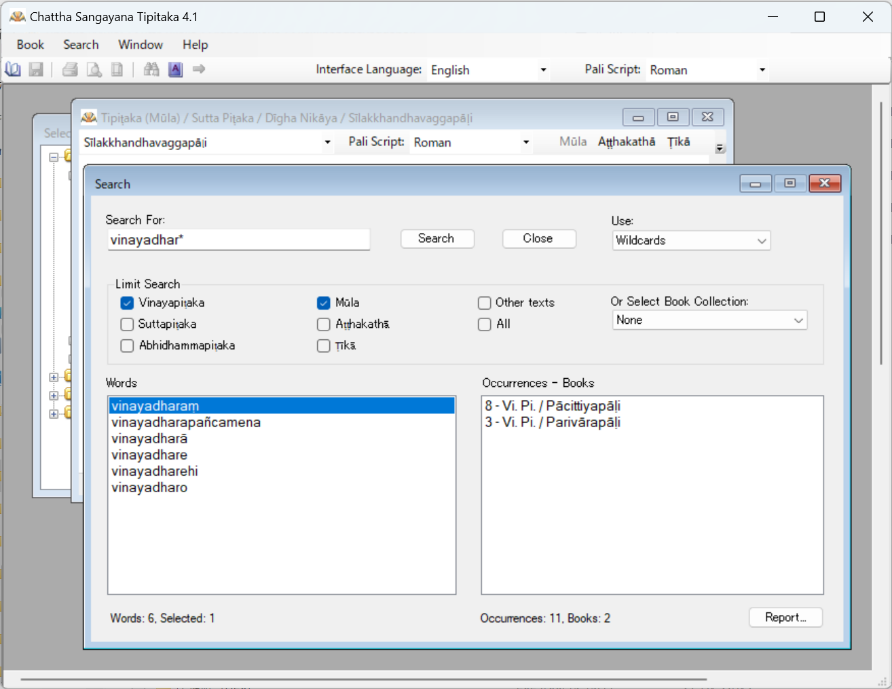
「vinayadhar」に始まる表現は「vinayadharaṃ」「vinayadharapañcamena」「vinayadharā」「vinayadhare」「vinayadharehi」「vinayadharo」の6種類があり、そのうち 「vinayadharaṃ」という表現は Pācittiyapāḷi という部分に8回、Parivārapāḷi という部分に3回現れることが分かる。「Search」ウィンドウの「8 – Vi. Pi./Pācittiyapāḷi」または「3 – Vi. Pi./Parivārapāḷi」という部分をクリックすると、新たなウィンドウが現れ、該当箇所のテクストが表示される仕組みになっている。この機能は語句の用例を研究し、パーリ語文献を厳密に読解する上できわめて有効であり、これこそがパーリ語文献研究者が CST を重宝する最大の理由となっている。
ところで、パーリ語文献研究者にとって、研究上の基準となる版本は PTS 版である。諸版本のうち PTS 版のみが学術的な校訂版と見なされており、論文等でパーリ語文献を引用する際には PTS 版の巻数・頁数を記すのが慣例となっている。この PTS 版についても、GRETIL(https://gretil.sub.uni-goettingen.de/gretil.html)で公開されているデジタルテクストを検索するためのツール(https://scrapbox.io/utdh/Pali_Text_Searcher)が整備されている。パーリ文法学の研究者であった故渡邉要一郎氏が作成したもので、非常に有用なものである。しかしながら、PTS 版のデジタルテクストは文献横断的な検索には不向きである。ビルマ第六結集版と異なり、PTS 版は文字列の表記法 (連声の表記方法など)が文献によって若干異なっており、その表記法の不統一がデジタルテクストにも反映されてしまっているからである。この他、タイ版およびシンハラ版にも、デジタルテクストは存在するが、検索システムが未だ整備されていない。現状、PTS 版、タイ版、シンハラ版のデジタルテクストでは、CST 並みの正確さおよび網羅性を伴う検索は難しいのである。
CST が抱える問題
あらゆるデジタルテクストが抱える問題として、元の媒体との齟齬というものがある。両者を完全に一致させることは非常に難しく、正確性を期すならば、最終的には人力でチェックするしかない[8]。これは CST にも当てはまることであり、ビルマ第六結集版との齟齬があることはヘビーユーザーにはよく知られていることであろう。
実は、そのことは VRI 自体も認めていることであり、VRI のウェブサイトにある「FAQs on the CSCD」[9]という記事に以下のような記述が見られる。
「Vinaya Piṭaka」「Sutta Piṭaka」「Abhidhamma Piṭaka」という見出し語のもとにあるテクストは、二度入力し、コンピューターで電子的に比較し、入力ミスの約98%を除去しました。その後、イガップリのVRIの研究者や多くのミャンマーのパーリ語文献研究者が、起こり得る入力ミスを除去するために、綿密に校正しました。しかし、これらのテクストについて 「完全に」ミスがないとは言えません。どんなミスでもご指摘いただければ、次のバージョンの CSCD で修正するようにいたします。 「Añña」という見出し語のもとにあるテクストについては、それほど徹底的には校正していません。これらの巻のほとんどについては、二つの入力ファイルを電子的に比較しました。しかし、多くの場合、人力での校正は行っていません。そのため、これらの巻については若干のミスが含まれている可能性があります。(筆者による英語からの和訳)
図1の 「Select a Book」ウィンドウに列挙される項目のうち、 「Tipiṭaka (Mūla)」 (三蔵)に含まれる「Vinaya Piṭaka」「Sutta Piṭaka」「Abhidhamma Piṭaka」については、研究者による人力の校正が綿密に行われたとされるが、 「Añña」 (その他)に含まれる典籍 ( 『清浄道論』、史書、文法学書など)については、それほど綿密な校正は行われていないということである。「Aṭṭhakathā」 (注釈書)および 「Ṭīkā」 (復注釈書)については言及がないため、そこに含まれるテクストの校正にどの程度の労力がかけられたのかはっきりしないが、「Tipiṭaka (Mūla)」ほどの労力はかけられていないのではないだろうか。
上記引用は CSCD の初期バージョンをリリースする時に準備された記事であると考えられ、恐らく1997 年頃の状況を物語ったものであろう[10]。ユーザーの指摘に基づき入力ミスを修正し、バージョンアップ時にそれを反映する方針であるとされるので、現在のバージョンは当時よりは正確にビルマ第六結集版のテクストを再現したものとなっているのではないだろうか。
しかし、依然として、ビルマ第六結集版と CST との間には齟齬が見出せる。例えば、「Aṭṭhakathā」に含まれる Pācittiya-aṭṭhakathā というテクスト(「Vinaya Piṭaka」の注釈書の一部であり、PTS 版で224頁分に相当する)について、CST 4.1とビルマ第六結集版とを比較してみると、百を優に超える不一致を見出すことができる。それらの中には、単なる入力ミスだけでなく、意図的な改変と思われるものもある。また、本文だけでなく、それ以外の部分に現れる場合もある。以下にいくつかの例を挙げておこう。

不一致の詳細については改めて論じるつもりであるが、ビルマ第六結集版と CST との間には少なからぬ不一致が見いだせるのである。したがって、CST だけに頼って用例研究を行うと、見落としが生じてしまう可能性も考えられよう。
おわりに
以上のように、CST のデジタルテクストには誤入力や意図的な改変というものが少なからず認められる。また、その底本であるビルマ第六結集版が学術研究における標準版ではないという難点もある。しかしながら、CST には他には代えがたい有用な機能が備わっている。一つは文献横断的に検索できる機能であり、もう一つは聖典である三蔵から注釈書および復注釈書の対応箇所に瞬時にジャンプできる機能である。これらの機能は研究者がパーリ語文献を精読する上で欠かせないものである。学術研究の標準版である PTS 版において、表記法の不統一の解消および注釈書および復注釈書のデジタルテクストの整備がなかなか進まない現状にあっては、今後も当面は CST がパーリ語文献研究のデジタル・プラットフォームであり続けるのではないだろうか[11]。
- コメントを投稿するにはログインしてください