人文情報学月報第102号
ISSN 2189-1621 / 2011年8月27日創刊
目次
- 《巻頭言》「図書館に求められる変化とデジタル人文学への期待:ビデオゲームのメタデータ研究を通じて」
:立命館大学大学院先端総合学術研究科・立命館大学衣笠総合研究機構 - 《連載》「Digital Japanese Studies 寸見」第58回
「CSS テキスト3題:正倉院文書のマイクロフィルム画像、「日本の中世文書 WEB」ベータ版、そして SAT 日本撰述部底本データベースの公開」
:国文学研究資料館古典籍共同研究事業センター - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第20回
「Universal Dependencies の統語記述の特徴と自動統語解析」
:ゲッティンゲン大学 - 特別寄稿「パブリックドメイン資料とリーガルコミュニケーション」
:慶應義塾大学大学院政策・メディア研究科・NPO 法人コモンスフィア - 人文情報学イベント関連カレンダー
- 編集後記
《巻頭言》「図書館に求められる変化とデジタル人文学への期待:ビデオゲームのメタデータ研究を通じて」
私がデジタル人文学と接点を持ったのは20年ほど前のことになります。学部生だった私はビデオゲームに傾倒しており、それをテーマにした研究に興味を抱いていました。丁度そんな中、所属していた学部の教員がゲームの研究プロジェクトを進めていることを知りました。1998年に活動を始めたビデオゲームの社会的利活用とアーカイブ構築を目的とする「ゲームアーカイブプロジェクト[1]」です。以来、私はそのプロジェクトや2011年に設立された立命館大学ゲーム研究センター[2]において、ビデオゲームのアーカイブをサブテーマとして研究活動を続けていました。本格的にビデオゲームの目録やメタデータを研究対象の主軸に据えるようになったのは、5年ほど前のことです。きっかけは、立命館大学ゲーム研究センターがゲーム分野のデータ作成を担当している、文化庁により運営されるメディア芸術の総合目録提供サービスであるメディア芸術データベース[3]の有識者会議の場でした。そこでメタデータを専門とする先生方のご助言を頂きました。その時点ではメタデータに関わる専門的な概念を十分には理解できておらず、今考えると、最初は恥ずかしながらそこでの議論の半分も把握できていなかったかもしれません。その時点で、ビデオゲームの目録について真剣に考えている人、さらにそれを専門的に研究している人が少なくとも国内で数少ないことは明白であり、またゲーム研究センターには多数のビデオゲームの所蔵、すなわちサンプルがありました。私はそこでほとんど勘違いともいうべき責任感を発揮し、覚悟を決めて一から勉強し直すことにしました。
図書館情報学分野のリソース記述に関する知見の蓄積は計り知れないほど膨大であり、それらを容易に身につけるのは難しいことが分かりました。さらに近年は情報通信技術の発展を受けて、Linked Data や資料のデジタイズなどのコンピュータ科学の近接分野と深く結びついており、これらの体系だった知見はとても魅力的に映り、夢中で研究を進めることができました。これまでの研究領域と違い、理論的であるだけではなく実践的であるという点に新鮮味があったのでしょう。
さて、この領域は、とてもエキサイティングであるにもかかわらず、図書館情報学分野の専門家の多くはなんだか「どんより」とした空気を纏っていて、その点に違和感がありました。結局のところその原因は、図書館という施設の社会的な位置付けに基づく危機感にあるのだろうと思います。彼らは日々の業務を遂行するだけでも大変であり、新しいことをするには圧倒的にリソースが足りないし、実際に生じる新しい課題を継続的に解決するための見通しが立たない、そのような意識が背景にあるのではないでしょうか。
ビデオゲームのメタデータには、その状況が現出していると見立てることもできます。端的にいうと、図書館が作成するそれらは不十分な品質です。ゲームのジャンルが記録されない、開発者やキャラクターを記述する要素がない、再販売版との関連がない、などスキーマにはその資料ならではの特徴を踏まえた記述力がないし、またそれをなんとかしようという意図もあまり感じません。ビデオゲームは、図書館からすると「変わり種」の資料であり、その特徴を踏まえた要件を策定すること、さらにそれらを適切に記述することは、彼ら自身のミッションのスコープ外であると考えているからでしょう。そもそもビデオゲームを所蔵する図書館は国内では国立国会図書館などのごく一部に限られています。このような資料の保存・記述・アクセシビリティの確保は、それぞれ専門性を持つ人間が考えることであり、図書館のコミュニティだけにその責任が帰されるところではありません。
しかし、福島幸宏先生なども指摘なされていますが[4]、図書館には新しいビジョンやあり方が必要なのだろうと考えられます。それは前述した図書館関係者の空気感や、なによりこれまでに私たちが調査を続けてきたビデオゲームを所蔵する多数の海外の博物館や図書館などにおけるスタッフや機能の充実ぶりを見ても明らかです。その新しいビジョンの中では、図書館が役割分担し、地域情報や学術情報などの専門化を進めることがなによりその主軸になると想定されます。そうすることで、ビデオゲームのようにこれまでスコープ外だった資料に専門性を有する機関が生じ、図書館コミュニティ全体としてより多様な資料の情報を公開・共有することができます。このような指針を採用するとすれば、地域のコミュニティや専門家のコミュニティとの協業が一つの命題となり、図書館員に求められるスキルセットも変容することになると思われます。
デジタル人文学領域では、資料のデジタイズと公開手法の標準化、Linked Data、テキストマイニング、さらには機械学習などといったトピックが議論されており、前述の新しい図書館のビジョンを達成する上で求められる知見・人材・スキルセットの一部が集中しているように思われます。また、デジタル人文学やデジタルアーカイブはプロジェクト型で展開することが多いため、若手人材のポストや生成されたデータの有期性がたびたび問題になりますが、恒常的な装置である図書館はそれをなんらかの形でカバーできるかもしれません。また、概念の翻訳や整理など理論的な論点に焦点化する傾向が強い図書館情報学の目録研究などにとっても、実践的でクリエイティブなデジタル人文学の研究は刺激的なものだと考えられます。
このように考えれば、図書館とデジタル人文学の結合は必然のように感じられます。もちろん既に多くの場面において、そのような実践が進んでいます。しかし、図書館のあり方が大きく変わっているという実感はまだあまりありません。やはり、公共サービスである図書館には強いガバナンスがあり、また日々の業務などに基づく慣性的なバイアスが強く作用しているためだろうと思われます。しかし、変化は必要だろうという考えは図書館コミュニティの総意のようにも感じられますし、そこでデジタル人文学に期待されるところは大きいのではないかと思います。
翻って私は現在、前述のような経緯を経つつ、ビデオゲームのメタデータモデルの開発や、システム実装、メタデータ制作、資料の保存環境構築などを進めています。その成果の一つが「RCGS コレクション」というビデオゲームの公開目録です[5]。また、メディア芸術データベースの開発に参加し、同データベースの協力機関のデータ連携やコミュニティ強化などといった活動を進めています。ここで対象となる表現形式であるマンガ・アニメ・ゲーム・メディアアートは、世界的に強い影響を有するにもかかわらず、デジタル人文学的アプローチの研究蓄積は未だ少ない状況です。こちらも読者の皆様にはご興味・ご助力をいただければ幸いです。また、何らかの形で私も、図書館を軸とする文化資源の記述や公開、利活用を推進する体制構築に貢献できる研究活動を進め、少しでも研究コミュニティに恩返しができればと考えています。
執筆者プロフィール
《連載》「Digital Japanese Studies 寸見」第58回
「CSS テキスト3題:正倉院文書のマイクロフィルム画像、「日本の中世文書 WEB」ベータ版、そして SAT 日本撰述部底本データベースの公開」
年度末ということもあろう、時評としては取り上げるべきものが多い。
1. 正倉院文書のマイクロフィルム画像ウェブ公開
2019年12月26日、正倉院事務所のウェブサイトが更新され、正倉院宝物検索の情報が富化されたほか、文書検索がお目見えした[1][2][3]。正倉院文書については、本連載で取り上げたことはないが、東大寺に置かれた正倉院に伝わった造東大寺司写経所文書を中心とし、同様に御倉に伝えられた光明子献納品などを包含する文書群である。一機関とはいえ奈良時代の文書群がまとまって伝来するということは世界的にも稀であり、聖武天皇との由縁もあって、長く護持されてきた宝物殿である。江戸時代にはすでに注目を集め、その一端はかつて取り上げた聆濤閣集古帖にも現れている[4]。その撮影もはやくに進んでおり、ながらく研究に利用されてきたが、このたびウェブで公開されたことはたいへん大きなことである。
とはいえ、文書検索とは言いつつも、現時点において、個々の文書が自在に検索できるようになっているわけではない。正倉院文書は、幕末から明治初期にかけての整理のなかで、写経所文書が正・続修などの六集に編纂されたほか、伝来ごとの文書群および断片的な塵芥文書に区分されており、基本的にはその整理を尊重して世に行われてきた。その整理単位がこのデータベースにおいて提示される単位であって、文書単位で構成されるわけではない(この構成そのものは東寺百合文書 Web でも見られる、文書単位の検索ができないわけではないが)。URL は安定しており、コマ単位で再アクセスも可能なようである。正倉院文書の検索としては、正倉院文書データベース SOMODA(栄原永遠男代表)などをひきつづき使う必要があろう[5]。
2. 「日本の中世文書 WEB」ベータ版公開
2020年1月8日、国立歴史民俗博物館から「日本の中世文書 WEB」ベータ版が公開された[6][7]。かつて同館で行われた同名の企画展示のウェブ展開とのことで、単に画像と釈文、および解説が公開されるわけではなく、読み上げがある点が(しかも読み上げにあわせて釈文の色が変わるのが)興味深い。また、そのためか現状点数は8点に留まる。今後公開点数は増えるとのことである。解説文や大意は図録とは異なるようである。注釈類は現状ない。
古文書のような表記では、読み方が自明に分かるものではなく、また歴史研究ではそのときどきの読み方の厳密な推定よりも内容理解が優先されるなどのこともあって、読み方を仮名で示すことも稀であるなかで、このような試みは冒険的であろう。フォーラムも用意されているが、さっそく検討会の様相を示しつつあり、いたしかたなさもありつつどう捌いていくのかも興味深い。読み上げは、もちろん書いてあるものを読めばそうなるのだが、現代でも賞状を読み上げるときに感じるような違和感を覚える。文書を文書として読む行為と、読み上げる行為とは別であるということであろうし、そのような享受の差についても展開されるのだろうか[8]。
3. SAT 日本撰述部収録典籍の底本情報
大正新脩大蔵経を電子化・Web 公開をしている SAT 大藏經テキストデータベース研究会では、1月10日に同大蔵経日本撰述部に収録される典籍の底本情報を公開した[9][10][11]。これは、大正大蔵経の本文検証の前提となる各種異文の伝存状況を整理したものだとのことである。異本の整理は所在の確認だけでも少なからぬ時間と手間を要するものであり、このような基礎情報が整理されることは大変ありがたいものである。[11]から CSV データもダウンロード可能となっている。国文学研究資料館の書誌データベースを利用したところがあるとのことである。
凡例はまだ提供されていないので、例として挙げられた聖徳太子撰の『勝鬘経義疏』によって見てみると[12]、種別・所蔵者・成立・OPAC・デジタル版所在などの情報が整理されている。種別欄は、「原本」・「写本」・「版本」などとされているが、「原本」に内容が入っている例はCSVによって見てもない。大正大蔵経そのものの底本は宝治年間版本とあるが、それに該当するとおぼしき慶應義塾大学などに所蔵される本は版本としか示されていない。「刊」とだけある分類もあり、相違点など、今後くわしい説明が期待される。また、容易ではないと思うものの、データベースとしても、大正大蔵経における異文記号との対照などが展望としてあるのではなかろうか。
以上、3点の毛色のちがうテキストに関するデジタル資源を観察してきた。三者三様にデジタル資源に欠けていた部分を補う試みがなされており、テキストの可能性として考えるべきことやテキストを伝える営為のひろがりをあらためて感じるところである。なお、このほか「フォローすべき日本関係デジタル人文学 Twitter アカウント」というコラムがあった[13]。
Yuta Hashimoto さんのツイート: “音声読み上げ機能。なんとなく「古文書でカラオケできたらおもろいやんけ」くらいの意識で実装したのですが、近世以前もっぱら文書は音読されていたはずで、ごく自然な提示の仕方だと思うようになりました。以前そういう話をここで書いたことがあります。https://t.co/9sbWnvXRDJ…”https://twitter.com/yuta1984/status/1215844308269453312
shosira / Shoji Ohashi さんのツイート: “こういうのを僕は「デザインにおける小指」と呼んでいる(嘘です、いま名付けました)。普段は無意識下にあって、喪われると露わになる機能性。この場合は喪われていたものが発見された事例かなー。” https://twitter.com/shosira/status/1215847081895546881
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第20回
「Universal Dependencies の統語記述の特徴と自動統語解析」
現在、筆者は Universal Dependencies(UD)を使ってコプト語のコーパスの統語情報のアノテーションを行っている。筆者は言語学のバックグラウンドを持っており、言語学の観点から、筆者なりに UD の特徴と UD を用いた自動統語解析ツールについてここで述べたい。UD のデータは CoNLL-U 形式で書くのが基本となっている。それぞれの UD のプロジェクトで作成されたデータは、UD の GitHub のリポジトリにアップロードされていて、誰でもアクセス・ダウンロードすることができる(https://github.com/UniversalDependencies; なお、本稿の全ての URL の最終閲覧日は2020年1月18日である)。CoNLL-U は次のような構造となっている。

まず、最初の行には文の ID が書かれ、2番目の行には文のテクストが書かれる。2番目の行からはその文に出てくる単語の分析情報である。これらの行の最初の列は単語の番号、2列目はその単語の文に出てくる形、3列目はレンマ、4列目はどの言語にも普遍的に付される品詞タグである UPOS、5列目は言語ごとに異なる品詞タグである XPOS、6列目は性・数・格、あるいは、人称・時制・相・態・法などの文法情報、7列目はその単語が文中のどの単語に依存しているか、そして8列目はその依存関係が書かれている。例えば、3行目に書かれている最初の単語の I は、4行目に書かれている2番目の単語 have に依存しており、その関係は nsubj(nominal subject; 名詞類である主語)である。
UD では、基本的に動詞、その次に名詞が主要部となる。現在の生成文法などでは、冠詞と名詞がある場合、限定詞である冠詞が主要部となり(「DP 仮説」)、前置詞と名詞があった場合、前置詞が主要部となる。これとは異なり、UD では、冠詞は名詞の、前置詞は名詞の従属部となる。生成文法などでは関係詞や補文標識は、関係節そして補文節の主要部となるが、UD の場合はそうではなく、関係詞やその関係節の、補文標識はその補文節の動詞の従属部となる。また、コピュラ文ではコピュラは主語となる名詞類の従属部となる。
生成文法的な句構造文法に慣れている者にとっては、UD はこのように大変違和感が大きい記述の仕方をする。これは、UD が類型論上ありうる全ての統語構造をそこに見えている語だけで記述しようとするためである。例えば、日本語には冠詞はないが、名詞を主要部とすれば、わざわざ形態がゼロの限定詞主要部を仮定する必要がなくなる。フィンランド語には、多数の格があり、基本的なものならば、前置詞や後置詞などの側置詞を使わなくても、様々な意味役割を表現できるが、名詞を主要部としたら、ゼロ形態の側置詞主要部を仮定せずに済む。日本語において関係代名詞はないが、この場合も関係節の動詞が先行詞の名詞に依存していると UD は考える。また、コピュラ文では、アラビア語やヘブライ語、ロシア語など、コピュラが一定の条件でゼロになる言語があるが、その場合も主語の名詞を文の主要部とすれば、ゼロコピュラを仮定せずに済む。このように、統語構造を記述するのにゼロ形態を仮定しなくても済むのが UD である。
チェコのプラハ・カレル大学の形式・応用言語学研究所によって作成された UDPipe(http://lindat.mff.cuni.cz/services/udpipe/)では、英語、日本語、古典中国語、ギリシア語、ラテン語、コプト語など様々な言語で既存の UD モデルを使って自動で統語解析することが可能である。例えば、図2は、英語の単純な文を解析した結果である。 モデルは UD2.4の english-gum-ud-2.4-190531を指定した。この UDPipe では、CoNNL-U 形式のほか、表形式とツリー形式で表示することが可能である。
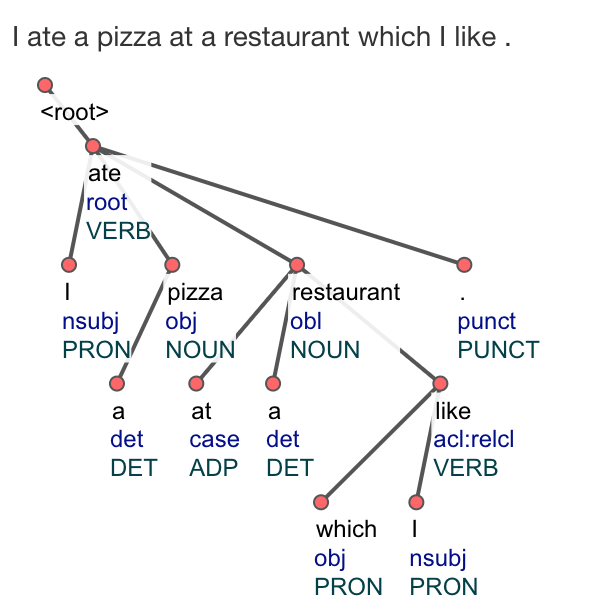
ここでは、不定冠詞 a と前置詞 at が名詞 restaurant に依存していること、そして、関係節内の動詞 like が関係代名詞である which と関係節の主語である I を支配し、主節内の先行詞である restaurant に依存していることに注目していただきたい。
現在筆者は、筆者が参加している Coptic SCRIPTORIUM(https://copticscriptorium.org/)と KELLIA プロジェクト(http://kellia.uni-goettingen.de/)が共同開発した Coptic NLP pipeline(https://corpling.uis.georgetown.edu/coptic-nlp/)でコプト語テクストの自動統語解析を行い、Arborator(https://arborator.ilpga.fr/)を用いてエラーの修正を行っている。このタスクで完成したデータはさらに精度の高い統語解析のためのトレーニングデータとして用いられる。このサイクルでどんどん統語解析の精度が上がっていくことが期待される。その成果は随時、Coptic NLP pipeline の自動統語解析に反映される。また、このデータは UDPipe で二次利用され、ユーザが入力したコプト語テクストを自動で解析し、CoNLL-U 形式で出力できるほか、図2のようなツリーも出力できる。
筆者がエラーの修正で用いている Arborator では、主要部の語から従属部の語へ矢印をドラッグして語と語を繋ぎ合わせ、品詞をドロップダウンメニューから選ぶだけで、依存関係を結ぶことができる。
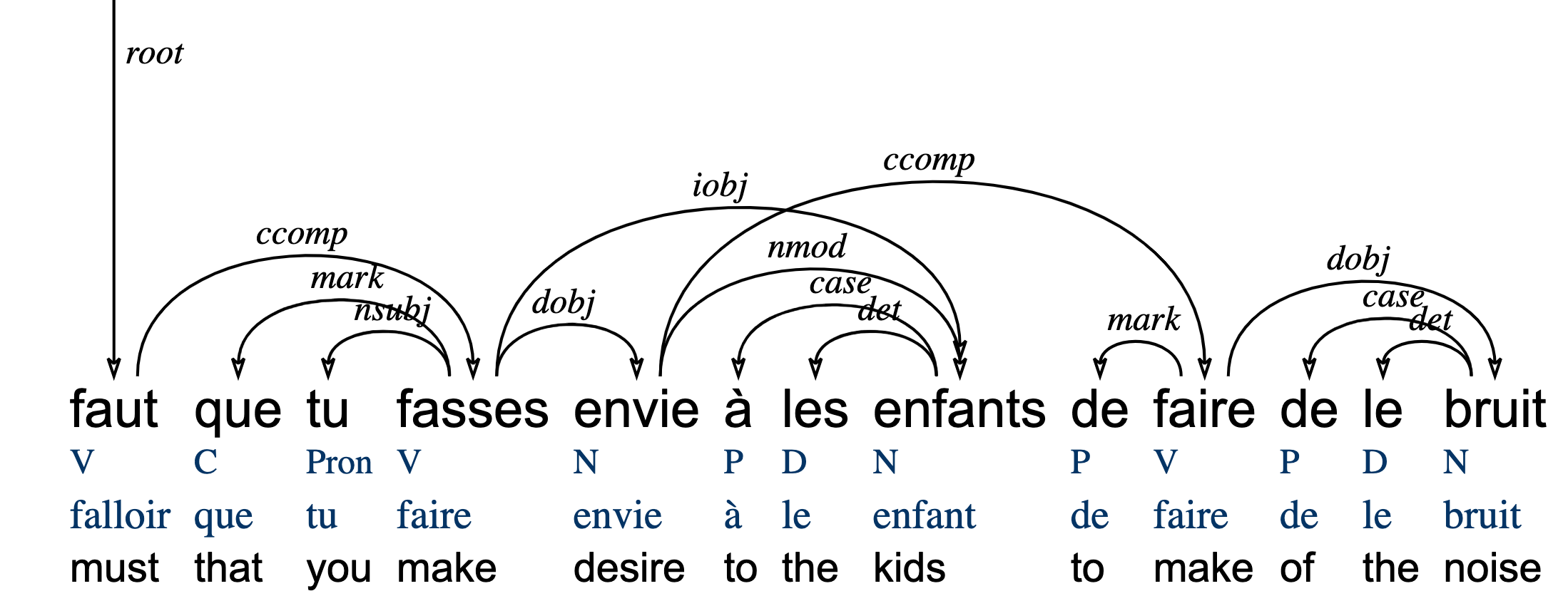
図3は Arborator がサンプルファイルとして提供しているフランス語の例である。ここではなされていないが、品詞別に色をつける設定をすることもできる。フランス語では通常 à les は aux に、de le は du に縮約されるが、UD では通常、縮約されない形に標準化される。à les enfants(通常は aux enfants と書かれる)の下を見ると、P、D、N とあるが、P は Preposition(前置詞)、D は Determiner(限定詞)、N は Noun(名詞)であり、UD が設定している普遍的な品詞タグ UPOS ではなく、それぞれの言語に特有の XPOS が表示されている。
UD は、どのような言語でも極力少ないマークアップで統語情報を記述し、ツリーを作ることができるため、Coptic SCRIPTORIUM のようなデジタル・テクスト・コーパス・プロジェクトで採用されることが多くなりつつあり、それに伴い今回紹介した UDPipe や Arborator、前回紹介したいくつかのビューワーなど、様々なツールが開発されてきている。現在 UD に対応しているツールの一覧は https://universaldependencies.org/tools.html で見ることができる。これらのツールを使って、まだ UD のデータを持たない言語や方言でも UD プロジェクトが作られ、言語類型論的な統語研究への UD の応用がますます加速していくことを願っている。
特別寄稿「パブリックドメイン資料とリーガルコミュニケーション」
2020年1月17日に、「デジタル知識基盤におけるパブリックドメイン資料の利用条件をめぐって」と題されたシンポジウムで発表、議論の機会を得た。筆者の関心は、利用者の利便性をできるだけ損なわない形でデジタル資料が提供され、活発に利用される世界の実現にあり、そのためのリーガルコミュニケーション(とでも呼ぶべき、法的、その他関連する情報のやりとり)の手法にある。
デジタルアーカイブの中には、著作権法上は既に保護期間が経過しているパブリックドメインの資料をデジタル化して提供しているものが多くあるが、日本でも、諸外国でも、そこにクリエイティブ・コモンズ・ライセンス(以下 CC ライセンス)をつけていたり、利用規約を課していたり、何らかの形で利用を制限しているものが散見される。
CC ライセンスについて言えば、リーガルコミュニケーションの手段としては、名前の付け方やビジュアル要素の構造、略称やURLの規則性、サマリーページの用意など見るべき点は多い。だが、この文脈で使い方として適切かというと、そうでもない。
パブリックドメインの平面資料(古典籍など)を忠実に再現するような画像は著作権保護の対象にはならないだろうから、デジタル化を行ったアーカイブの運営主体は著作権等の権利者ではなく、従って、ライセンスを付与する立場にはないだろう。であれば利用者は、ライセンスを無視して自由に利用したところで、著作権侵害になるということもない。
日本で CC ライセンスの普及・サポートに携わって来た身としては、他に適当な選択肢もなく、アーカイブ側が意向を伝えるのに便利だからといったリーガルコミュニケーション上の理由で CC ライセンスが採用されたという例に行き当たることは、普及のひとつの証を見るようで嬉しい面もある。だが、権利がないところに権利があると誤解させて情報資源の利用にマイナスの効果をもたらしたり、CCライセンスは場合によっては無視してよいものだという理解が広まったりする可能性もあるだけに、手放しで喜べるものでもなく、複雑な思いだ。
ライセンスではなく「利用規約」の類であればまだ、法的な有効性は担保しやすいだろう。コンテンツを提供するウェブサイトを直接利用する人に対して規約に同意させ、一定の条件を課すことは広く行われている。ただ、多種多様な利用規約が生まれることについては全く喜べない。利用規約の乱立は社会に学習コストの負担を強いることになるからだ。われわれの多くは、アプリやウェブサービスを使いながら、利用規約を全く読み切れないという事態をよく知っているし、読んで理解することを強いられる苦痛を知っているのではないだろうか。
デジタルアーカイブの利用は、ICT の発達・普及した現代では、友人とのコミュニケーションに使ったり、SNS でシェアしたりといったものまで含めると実に幅広い。その利用者も著作権法に通じていない市民が幅広く含まれることになろう。研究者に限っても途上国を含めた海外の研究者が存在するだろう。そうした人々にとって、利用規約を読んで理解することは高いハードルであり、アーカイブ毎に規約が違っているとなれば、尚更である。利用条件を課す必要があるとしても、せめて、共通化や標準化を徹底し、利用者が何度も異なる利用規約を読まずに済むような環境があって欲しいと思う。オープンデータの実現の一環として、日本政府は政府標準利用規約を作成し、全省庁のウェブサイトの利用規約のデフォルトとした。例えばそのような環境は利用規約の乱立よりずっとよい。
だが、そもそも利用条件を課す必要があるかというと、ここはアーカイブによって大きく判断が分かれるところのようだが、義務を課さず法的拘束力のない「お願い」程度でもよいとも考えられる。
アーカイブの運営主体の多くは、利用事例の報告やクレジット(アーカイブ名・運営主体名)の明記などについてのニーズを持っている。これは筆者が過去8年ほど関わって来たオープンデータの世界でも耳にすることのあるニーズだった。利用事例を把握することでオープン化の取り組みの効果を検証したり、評価を行いたい、といったニーズは理解しやすいとも感じる。効果を検証したい、取り組みの評価を行いたい、といったことはある意味ではわかりやすい。
だが、オープンデータの世界に照らして考えるなら、オープン化に程度の差はあれそれ自体として価値があり、長期的にはオープン化が便益をもたらすだろうと信じられる人と、具体的にどのデータセットにどの程度のニーズがあるのか、その効果が本当にオープン化に必要な作業量などのコストを上回っているのか、本当にオープン化でなければならず、個別の依頼への対応ではだめなのか、といった徹底した懐疑を抱く人と、反応は様々である。幅広く見れば、オープンデータは利用事例も国内外で広がりを見せており、データの利活用促進が重要な政策課題として意識されていることなどもあって、利用事例の報告を義務付けることもなく(国際的によく言われるような意味での)オープン化が実施されるようになった。「政府標準利用規約」を参照すれば第1条の2文目に明記されているが、数値データなどは通常著作物ではないから、利用規約に制約されることなく(クレジット表記もなく)自由に利用できる。オープンサイエンスやオープンアクセスの大きな文脈を考えても、デジタルアーカイブもこのようなオープン化に進む、ということに一定の合理性があると筆者は考える。
他方では、例えば政府の補助金を利用したアーカイブ構築などの文脈では、その成果がどの程度であったのかを具体的な数字などで示すことを求められることがあり、それ以外にも実施の意義を評価する上で利用事例の把握が意味を持つということがある。日本は特に政府財政が苦しい状況にあり、説明責任を果たせない支出の中には無駄な支出もあるのだから、これはこれで理解できることではある。
ただ、オープン化の価値を広く認める立場と具体的な説明責任を課す立場には中間点もあるだろう。少なくとも学術的な利用の成果に関しては、ただでさえ事務手続きなどに忙殺されて研究時間確保が難しくなっている研究者に更に利用規約を読んだり連絡の手続きを義務付けるのは目先の数字にこだわり過ぎて大きな戦略を誤っているようにも思われる。短期的にはオープン化を実施することで学術研究に貢献する効果がどの程度得られるかについてデータ収集や推計の調査を行い、それをベースに敷衍することが、中期的にはジャーナルの電子化と書誌情報記載(citation)時の DOI の利用を推進することで解決することが、効率的だろう。幸い学術研究の世界には著作権法上の利用行為に該当するか否かに関係なく、依拠・参照した先行研究や資料の書誌情報を記載する慣行が存在し、違反者を処罰する規範としても機能している。そこで、アーカイブ側も申請や報告、ひいては多様な利用規約の読解を「義務付ける」よりもこのような規範にうまく取り込んでもらうことが研究への貢献・利用の促進になるし、それに必要なのは「お願い」程度のものなのではないか。
学術的な成果以外にも、社会への貢献度を知るためにも、様々な利用例を把握したいという欲求もありうる。ただ、それについても多くのアーカイブの意向は、網羅的に把握しなければならないとか、報告を怠る者には利用して欲しくないというほどの強硬なものではないのではないだろうか。また、思想・信条の自由を守ることを職業倫理上重視して来た図書館系アーカイブなどであれば、人々のプライベートなコミュニケーションにおける利用にまでその捕捉の網を広げたいと考えているわけではないだろう。そうであれば、把握しやすいソーシャルメディアでの利用を調査する、情報提供をお願いして協力を呼びかける、サイトへのアクセスデータから閲覧状況を把握する、といった取り組みでもよく、ここでも義務づけが不要なケースが多いかも知れない。
利用者にとっての利便性を考えるなら、「お願い」であっても、それができるだけ標準化・共通化され、理解しやすい形で表示されていることが圧倒的に望ましい。そのコミュニケーションの手法については CC ライセンスを参考にすることができるだろう。
シンポジウムに参加していた非営利組織や国立系のアーカイブ(営利系の参加はなかったように思う)に限っても、このような議論があてはまらないタイプのアーカイブが存在する。それは貴重な資料を所蔵している者から許諾を得てデジタル化、アーカイブでのデジタル資料の提供を行うような、所有権なきアーカイブである。所蔵者の意向が、自らの所有権から得られる利得を最大化することにあり、文化や学術研究、社会への貢献などにはない、ということも十分考えられるところであり、アーカイブ側に交渉力がない、ということも多いように思われる。
そのような所有者に所有されてしまったばかりに、公益が犠牲になり、私益が増大することになるのは、残念なことではある。ここに法的に介入することが適当かはだいぶ議論の余地があるとは思うが、社会規範的・道徳的に、そのような所有者に対して社会への貢献を促すことは不適当ではなかろう。
最後にもうひとつ、シンポジウムでは議論しきれなかった点のひとつに触れたい。米国は Google のような民間企業の活躍も目立ち、EU はそれに対抗して政府セクター主導で大きな取り組みが進む、というのが大きな構図であるように思う。これは筆者が別の文脈で研究・議論する機会のあるパーソナルデータの領域と似ていなくもない構図である。日本はどちらにおいても受け身・後追いの面があるのも気になるところだ。先発であることや覇権争いをすることに常に意味があるわけでもなく、デジタルアーカイブについては米国勢や EU の取り組みとも連携することで研究や文化が便益を得られると思うのだが、同時にアジア諸国との連携を通じたアーカイブの価値の増大などが模索できれば、そこにも大きな意義があることだろう。
執筆者プロフィール
関連論文・著作:「クリエイティブ・コモンズ:オープンソース,パブリックドメインとの関係からの考察」月刊『パテント』72, no. 9(2019年9月)、pp. 34–47(小林心と共著)、「3D データ、3D 作品に関する著作権を考える」『Imaging Conference Japan 論文集』2016、日本画像学会、pp. 83–86.
人文情報学イベント関連カレンダー
【2020年2月】
-
2020-02-01 (Sat)
情報処理学会人文科学とコンピュータ研究会第122回研究発表会於・佐賀県/佐賀大学理工学部6号館 -
2020-02-15 (Sat)
第9回「知識・芸術・文化情報学研究会」於・大阪府/立命館大学大阪梅田キャンパス -
2020-02-29 (Sat)
第25回公開シンポジウム「人文科学とデータベース」於・東京都/図書館流通センター(TRC)本社
【2020年3月】
-
2020-03-06 (Fri)
CH研究会30周年企画「はじめての人文情報学:情報処理技術で文化資料の分析に挑戦しよう!」(情報処理学会第82回全国大会)於・石川県/金沢工業大学扇が丘キャンパスhttps://www.gakkai-web.net/ipsj/82/event/html/event/C-3.html
-
2020-03-13 (Fri)
「通時コーパス」シンポジウム2020於・東京都/立川総合研究棟(国立極地研究所、国文学研究資料館、統計数理研究所)2階大会議室https://www.ninjal.ac.jp/event/specialists/project-meeting/m-2019/20200313/
-
2020-03-16 (Mon)
第15回京都大学人文科学研究所 TOKYO 漢籍 SEMINAR『漢字と情報』於・東京都/一橋大学一橋講堂中会議場http://www.zinbun.kyoto-u.ac.jp/zinbun/tokyo_kanseki_seminar2020.htm
Digital Humanities Events カレンダー共同編集人
◆編集後記
今月は、筆者が分担研究者として関わっている科研費事業にて、パブリックドメイン資料の利用条件に関するシンポジウムを行った。渡辺先生のわかりやすく整理された基調講演は好評であり、今回のご寄稿はそれをとりまとめていただいたものである。Webで研究資料を共有し活用するための基本ラインをどう設定していくか、ということは今後の人文学においても生命線となるものであり、研究者にとっても、資料提供者や作成者など、様々なステイクホルダーにとっても、わかりやすく取り組みやすい状況がなるべくはやく実現されることを願っている次第である。(永崎研宣)
- コメントを投稿するにはログインしてください