人文情報学月報第146号【後編】
ISSN 2189-1621 / 2011年08月27日創刊
目次
【前編】
- 《巻頭言》「オープンサイエンス時代における人文学の研究データ」
:一般財団法人人文情報学研究所 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第63回
「古代エジプト民衆文字(デモティック)の字形画像データベースとテキストコーパス: Demotic Palaeographical Database Project」
:人間文化研究機構国立国語研究所研究系
【後編】
- 《連載》「仏教学のためのデジタルツール」第11回
「Indoskript 2.0」
:東京大学大学院人文社会系研究科 - 《特別寄稿》「ロンドン滞在備忘録」
:ROIS-DS 人文学オープンデータ共同利用センター - 人文情報学イベント関連カレンダー
- イベントレポート「グラフ形式データ構造化と TEI:Joint MEC and TEI Conference 2023参加報告」
:ROIS-DS 人文学オープンデータ共同利用センター - イベントレポート「Joint MEC TEI conference 2023参加報告」
:早稲田大学大学院文学研究科 - 編集後記
《連載》「仏教学のためのデジタルツール」第11回
仏教学は世界的に広く研究されており各地に研究拠点がありそれぞれに様々なデジタル研究プロジェクトを展開しています。本連載では、そのようななかでも、実際に研究や教育に役立てられるツールに焦点をあて、それをどのように役立てているか、若手を含む様々な立場の研究者に現場から報告していただきます。仏教学には縁が薄い読者の皆様におかれましても、デジタルツールの多様性やその有用性の在り方といった観点からご高覧いただけますと幸いです。
「Indoskript 2.0」
Indoskript 2.0の概要と機能
Indoskript 2.0(http://www.indoskript.org/)は、インドの文字であるブラーフミー系文字とカローシュティー系文字の画像データベースである。トップページの解説によれば、このプロジェクトの前身は、ベルリン大学とハレ大学の共同で2000年から2005年にかけて実施され、850以上の写本から185,000字以上の文字や記号を収集し、写本の日付や地理情報を紐づけたという。オリジナルの Indoskript は Windows XP 用のデスクトップツールとして開発されたが、その後 Web インターフェースとしての Indoskript 2.0が、ハリー・フォーク博士とオリバー・ヘルウィグ博士によって2017年に公開されたようだ。
主な機能
- 文字検索: サイト上段のタブメニューにある “Your query” タブから、音、年代、地域などの条件を指定して文字を検索できる。例えば、 “ka”という音(Transliteration)でブラーフミー系の文字を検索すると、古くは紀元前3世紀のアショーカ石柱に記される “ + ” のような文字から、新しいものだとナーガリー文字の “क” に至るまで、合計1127件がヒットし、並べて表示される。
- 文字情報の閲覧:上でヒットしたそれぞれの文字画像にカーソルを合わせると、画面右上の地図にその文字が記される碑、あるいは写本の位置情報が表示される。文字画像の下にある丸字で囲まれたⓘのマークにカーソルを合わせると、その文字の年代が表示される。文字の画像をクリックすると、その文字が掲載されている碑、あるいは写本の書誌情報を閲覧できる。
- 書誌情報の確認:タブメニューの “Manuscripts” からも特定の写本、碑文の書誌情報やそこに含まれている文字のリストを閲覧することができる。
- 文字の比較表示:“Cross tables” では写本、碑文を選択した上でそこに登録されている文字を指定し、それらを並べて表示させることができる。
- 一時保存機能:検索した文字を “Basket” に一時保存して、後で参照することができる。
筆者の経験と評価
Indoskript 2.0で検索した文字の群れを眺めていると、文字を専門にしない者にも、時代と地域による形の傾向、その変遷が直感的に見てとれる。インドの文字を学び調べる上では、ぜひ参照すべきツールだと言える。特に、自身が扱う写本の文字と似た字形が Indoskript 2.0に登録されていれば、その写本が書写された時代や地域を知るヒントになりうる。あるいは登録されていない場合も、その事実は情報として価値がある。写本の文字を調査した論文の中で、この Indoskript 2.0のコーパスが参照されることも度々あり、文字研究の最前線で重宝されているようだ。
個人的な経験としては、写本断片を読む勉強会に参加していた際、このツールを頻繁に参照していた。まとまった分量のある写本を読む場合には、同じ写本内の文字の例を参照することができるので、その写本の外にある文字の情報を参照することは多くない。しかし断片など部分的な写本を読む際には、そこに十分な文字の用例がないので、Indoskript 2.0 のような参照用の文字データベースが大いに役立つ。
また必ずしも研究者だけでなく、インドの文字をこれから学ぶという学習者にとっても、このデータベースは貴重だろう。少し調べてみると、某所のサンスクリット初等文法の授業では、Indoskript 2.0が文字の参照用リンクとしてシラバスに掲載されているらしい。インドの文献を扱っている、あるいはこれから扱う人にとって、一度は触れてみるべきツールだろう。
《特別寄稿》「ロンドン滞在備忘録」
本記事は、本号掲載の小川潤「グラフ形式データ構造化と TEI:Joint MEC and TEI Conference 2023参加報告」の番外編である。筆者はパーダーボルンでの学会に参加したのち、9月9日からロンドンを訪れ、ロンドン大学・School of Advanced Study(SAS)の Gabriel Bodard 博士とのミーティングや、King’s Digital Lab の訪問を行った。そこで議論したことや学んだことについて、可能な範囲で紹介したいと思う。
今回のロンドン訪問の主な目的は、Bodard 博士とのミーティングにあった。このミーティングの内容は、Pelagios Network における新たな研究グループ(正式には「アクティビティ」と呼ぶ)設立に向けた提案文書作成である。Pelagios Network とは、地名を中心とした歴史情報を Linked Open Data(LOD)として構造化し、広く利用可能にすることを目的とする研究コミュニティであり、欧米を中心に近年盛んに活動している[1]。筆者は昨年12月、ヨークにおいて、この Pelagios Network のパートナーの一角を占めるLinked Pasts VIII Symposium に参加した[2]。その際、Pelagios Network のメンバーとも交流を深め、その一人であった Bodard 氏から、氏が企画している歴史人物の LOD 構造化研究グループ(「People Activity」)の共同チェアの誘いを受けた。かねて歴史情報の LOD 構造化に広く関心を有していた筆者にとってこの誘いは、国際的な研究に関わることのできるよい機会と思われたため、これを引き受けることとした。People Activity の基本的な問題設定と活動内容については、Linked Pasts VIII Symposium におけるセッションの一つですでに複数の参加者によって議論され、ウェブ文書としてまとめられていたが、今回のミーティングではその内容を改めて精査し、加筆修正した上で提出版の設立提案書を作成した。この提案書が採択されれば、Pelagios Network に正式に「People Activity」が加わり、歴史人物データの整備に向けて本格的に動き出すことになる。
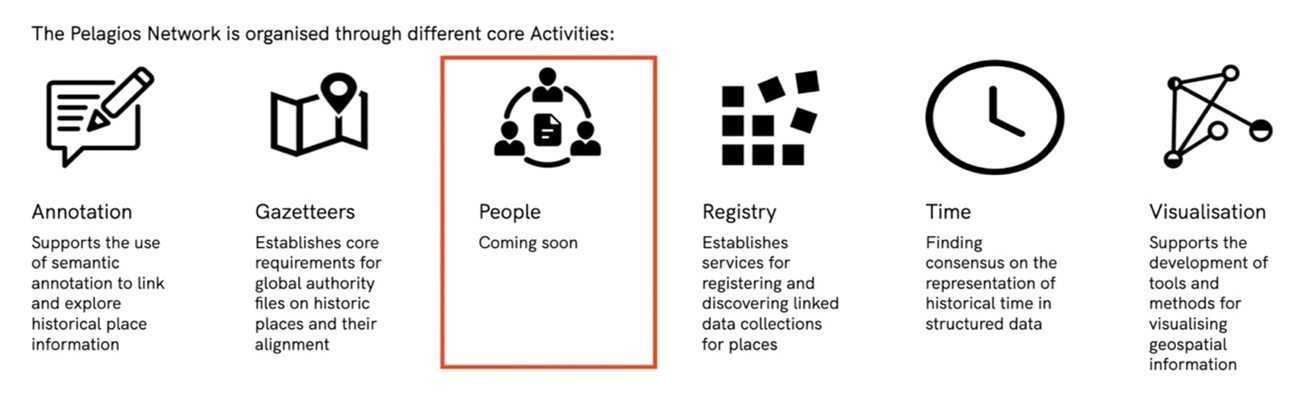
歴史人物についてのデータ整備は、各地域・時代ごとにさまざまなプロジェクトが進められてはいるものの、その情報の曖昧性や複雑性はもちろん、端的にエンティティ数が膨大であることもあって、標準化にあたっては課題が残されている。新たに設立予定の「People Activity」はまさにこうした課題に取り組む予定であり、その成果や知見は将来的には日本研究における人物データの整備にも活用できるものになるだろう。その意味でも、「People Activity」の活動については、今後も可能な限り積極的に発信していきたいと考えている。
ロンドンでは、主目的である Bodard 博士とのミーティングに加えて、いくつかの DH 関連施設訪問を行ったため、これについても簡単に触れておきたい。一つは、Bodard 博士も所属する SAS の Digital Humanities Research Hub(DHRH)である[3]。DHRH のラボには、スキャナーや撮影機材、3D プリンターといった機材が完備されており、画像データや3D モデルの作成・出力を行うことのできる環境が整備されていた。また、こうした機材を揃えるのみならず、その活用についての試行錯誤が行われる空間であるとの印象を強く受けた。たとえば、3D プリンターを使って小型の活版印刷機を出力し、それを使って紙への印刷を体験する、古代の彫像を小型の3D モデルとして出力しアクセサリを作成する、あるいは、大理石の石板を用意し、刻字の専門家を呼んで碑文の刻字を体験するなど、専門研究の枠に捉われない自由な発想と「体験」を重視する、まさに DH「実験室」としての機能を備える空間であった。
もう一つの訪問先は、King’s Digital Lab(KDL)である。KDL は、名称からも明らかなように King’s College London の機関であり、さまざまな分野のデータをもとに、データ管理、研究ソフトウェアの開発、デジタル技術を用いた研究遂行のコンサルタントなどを担う[4]。KDL が進めてきた数多くのプロジェクトの中には、DH 分野において重要な意義を持つものも多く、国際的にきわめて重要な研究拠点の一つである。今回は、KDL の Arianna Ciula 氏と個人的にコンタクトを取ったことで訪問が実現したが、正式な訪問ではなく個人的な見学として訪れたこともあり、むしろ KDL 内部のレギュラーミーティングに同席を許されるなど、内部の仕事の様子を垣間見ることができた。筆者が同席したミーティングは、KDL に新たに加わったメンバーのための講習会のようなもので、KDL の基本的な理念やプロジェクトワークフローについて説明するものであった。参加者は、Arianna 氏のほかに、Samantha Callaghan 氏、Alessandra Esposito 氏、Lucie Mingmei Hao 氏である[5]。ミーティングの詳細についてここで述べることはできないが、KDL は単なるソフトウェア開発のみならず、デジタル研究の企画からデザイン、実装、管理までを包括的に担う機関であるため、それぞれのプロセスにおける意思決定の過程やプロジェクト遂行・管理の手法がきわめて厳密に検討されていることがよくわかった。その概要については、KDL のウェブサイトに掲載されている以下の図に簡潔に示されているように思う。
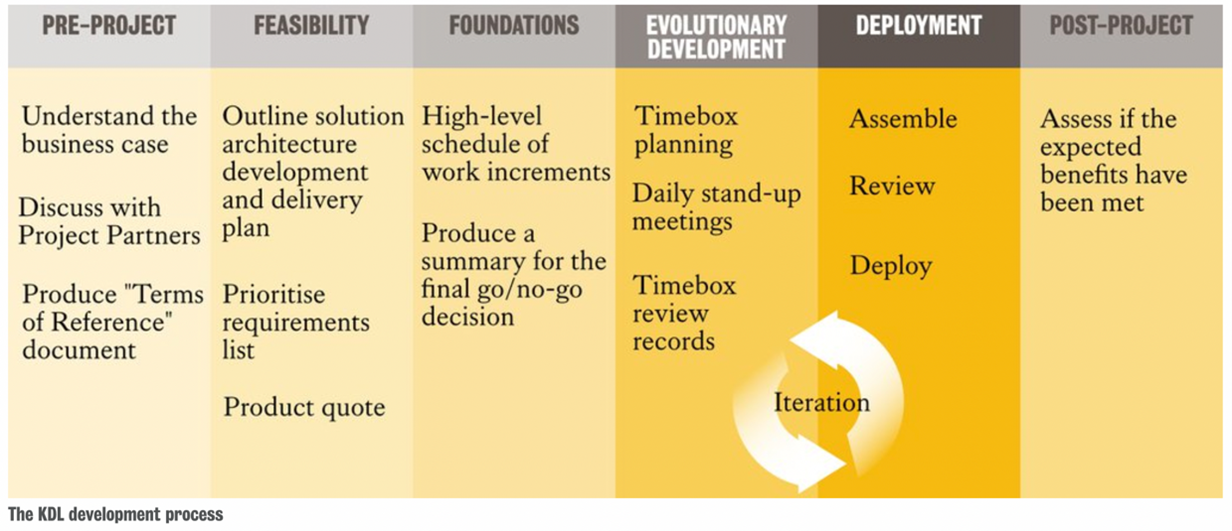
こうした、デジタル技術を用いたソフトウェア開発を中心としつつも、そこで用いられる技術基盤や、開発に関わる人々、開発時のコンテキストにまで焦点を当てる態度は Research Software Engineering(RSE)の問題意識そのものであるともいえ[6]、DH の研究環境そのものを批判的検討の対象とすることの重要性にも改めて気付かされる経験となった。
ロンドン滞在は、移動日を除けば計3日と短かったが、「People Activity」の進展はもちろん、ロンドンにおけるDH 最前線の環境と活動を知ることができたという意味でも、非常に有意義な滞在になった。
人文情報学イベント関連カレンダー
【2023年10月】
-
2023-10-7 (Sat)~2023-10-8 (Sun)
日本図書館情報学会 第71回研究大会https://jslis.jp/events/annual-conference/
於・愛知淑徳大学 星が丘キャンパス -
2023-10-5 (Thu), 11 (Wed), 19 (Thu), 25 (Wed)
TEI 研究会於・オンライン
【2023年11月】
-
2023-11-3 (Fri)~2023-11-5 (Sun)
PNC 2023 Annual Conference and Joint Meetingshttps://sites.google.com/view/pnc2023
於・琉球大学 -
2023-11-10 (Fri)~2023-11-12 (Sun)
デジタルアーカイブ学会第 8 回研究大会https://digitalarchivejapan.org/kenkyutaikai/8th/
於・石川県立図書館、石川県立音楽堂交流ホール -
2023-11-2 (Thu), 8 (Wed), 16 (Thu), 22 (Wed), 30 (Thu)
TEI 研究会於・オンライン
【2023年12月】
-
2023-12-1 (Fri)~2023-12-3 (Sun)
DADH 2023: The Fourteenth International Conference of Digital Archives and Digital Humanitieshttps://dadh2023.chinese.ncku.edu.tw/%E9%A6%96%E9%A0%81
於・國立成功大學 -
2023-12-9 (Sat)~2023-12-10 (Sun)
じんもんこん2023: 人文学のためのデータインフラストラクチャー構築に向けてhttp://jinmoncom.jp/sympo2023/
於・オンライン -
2023-12-6 (Wed), 14 (Thu), 20 (Wed), 28 (Thu)
TEI 研究会於・オンライン
Digital Humanities Events カレンダー共同編集人
イベントレポート「グラフ形式データ構造化と TEI:Joint MEC and TEI Conference 2023参加報告」
今年の TEI(Text Encoding Initiative)年次総会は9月4日から8日(ワークショップ含む)にドイツ・パーダーボルンにおいて、MEI(Music Encoding Initiative)との合同会議として開催された。合同会議ということもあって、例年の TEI では見かけない、楽譜・音楽資料の構造化に取り組む人々との新たな出会いもあり、よい刺激を受ける大会であった。また特筆すべきは、日本からの参加者・発表者のボリュームであろう。日本からは計11名がパーダーボルンに集い、そのうち8名が何らかの形で報告を行った。とくに、今回が初参加となった参加者・報告者も多く、TEI および MEI コミュニティにおける日本のプレゼンスが高まりつつあることを肌で感じることができた。
さて、会議の内容についてであるが、残念ながら筆者は MEI 側の研究について言及できる見識は持ち合わせていないため、それは他の参加者による記事に譲り、もっぱら TEI に焦点を絞っていくつかの議論を紹介する。毎度のことで恐縮ではあるが、筆者の関心は TEI と Linked Data、あるいは RDF との関連にあるため、今回もこの観点から、主に2つの動向を紹介することでイベントの参加報告としたい。
一つ目に取り上げるのは、昨年の TEI 参加報告でも言及した LINCS という研究コミュニティによる最新の研究成果の報告である[1]。カナダ・オタワ大学の Constance Crompton と Alice Defoure の2名による報告では、昨年と同様に TEI に基づく CIDOC CRM トリプル生成手法についての報告がなされた。昨年からの発展としては、ドイツ・マインツにある科学文学アカデミー(Akademie der Wissenschaften und der Literatur)の Torsten Schrader が開発した XTriples という、XML から RDF トリプルを自動生成するためのシステムを新たに採用し[2]、CIDOC CRM のオントロジーに則ったリンクトデータを作成するための手法を提案している点である。XTriples は、それ自体 XML で記述されるコンフィギュレーションファイルによって XML から RDF への変換を制御することで、任意の形にデータ形式を変換することができる。それゆえ、XTriples においては、コンフィギュレーションファイルの記述がもっとも重要ということになる。このコンフィギュレーションファイルのテンプレートは、XTriples のウェブサイトで公開されている。
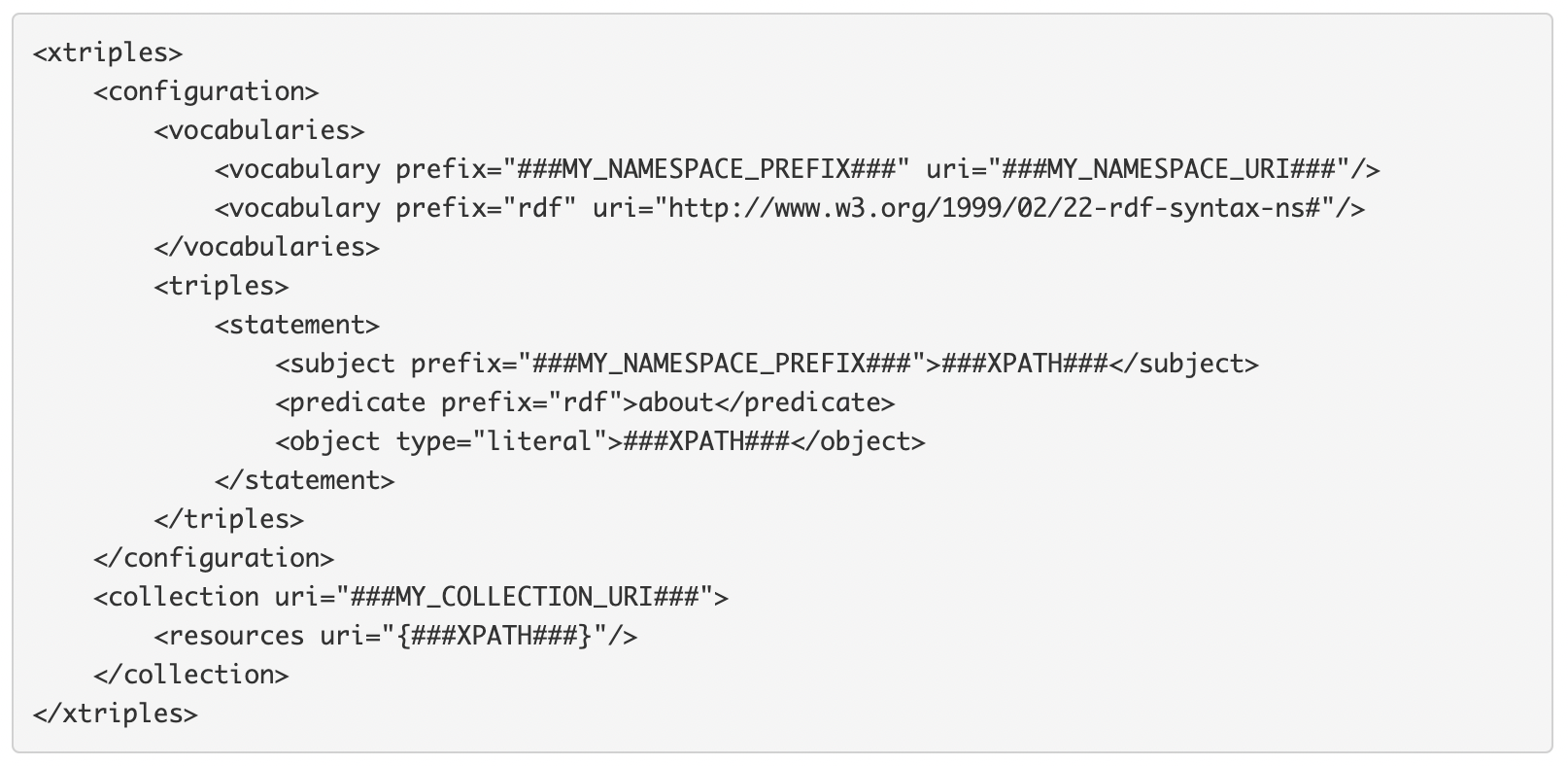
このテンプレートからわかるように、<triples> の中の <statement> においてトリプルの主語・述語・目的語を定義する。主語・目的語の値は XPath を用いて指定するため、既存の XML ファイルから柔軟にトリプルを生成できる点が XTriples の強みであろう。こうしたシステムは、すでに XML によって構造化されたテクストが大量に存在する分野においては、それを一括して RDF データに変換し、利用できるという点できわめて有用な技術である。LINCS の基本的な目標は、さまざまな場所で別個に存在する、あるいは作成されるデータを RDF という共通の形式で接続することで大規模なデータインフラを構築することであり、まさに XTriples のような技術が最大限有用に活用されうるケースであると言える。今後、このプロジェクトにおいては XTriples を用いた TEI データの RDF への大規模変換が進められるものと思われ、その動きに注目していきたいと思う。
二つ目に取り上げるのは、すでに触れたマインツ科学文学アカデミーの Andreas Kuczera によるロングペーパー報告である[3]。この報告は相当にラディカルな内容で、「TEI は XML によるマークアップを離れて、すべてグラフ形式のデータで記述することができる」という主張がなされた。そもそも、TEI と XML は一括して扱われることが多いが、両者が必ずしも不可分のものではないことは事実であり、TEI が提供する語彙、すなわちオントロジーに従って記述される情報は、原理的には XML 以外の形式でも表現可能である。このことは、上で取り上げた LINCS が TEI から RDF 形式のデータを抽出することを試みている点からも明らかであろう。また、TEI をグラフ形式のデータとして表現するという考え方そのものも決して新しいものではなく、長年議論がなされてきたテーマである[4]。今回の Kuczera による報告も、基本的にはこうした議論の延長線上にあるが、重要なのは、実際のテクストを対象としてグラフ構造、具体的には Neo4J というグラフデータベースを用いた TEI エンコーディングを実装し、その可視化・編集のためのシステムまでを実現している点である。いわば、これまでもっぱら抽象的・理論的になされてきた議論を具体化したという点に、この研究の大きな意義があるといえる。彼が構築した実際のデータの詳細はここでは説明できないが、端的に言えば、テクストを文字の連なりとみて、各文字を最小単位のノードとして構造化することで、XML において自明のものとして表現されるテクストのリニアな情報を保持しつつ、それを完全なグラフ構造データとして表現するものである。以下の図は Kuczera の報告要旨に掲載されているものだが、こうした文字単位でのグラフ構造化のイメージがよくわかる。
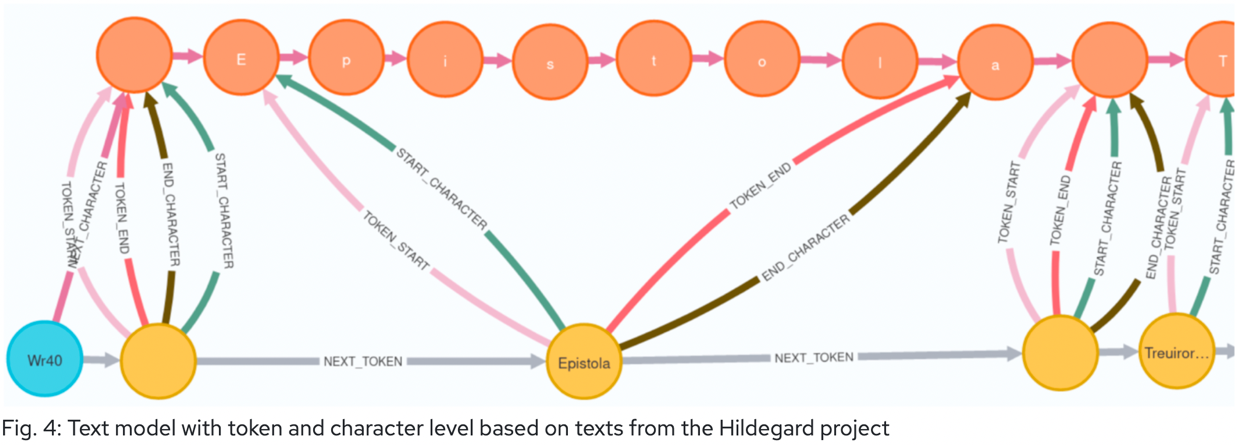
このようなグラフ構造を用いた TEI の記述については Kuczera の報告に加えて、パネルセッションでも扱われた[5]。Kuczera もパネリストとして参加したパネルでは、RDF による TEI の表現の可能性も議論され、そこでは Reification(具象化)やラベル付きプロパティ・グラフ(labeled property graph)、RDF-Star を用いた複雑な情報表現の可能性が提起されるなど、セマンティックウェブ分野の専門知識も交えたテクスト構造化手法の検討がなされた。また、Kuczera らのプロジェクトはすでに、Neo4J で構築したデータを基盤とした GraphQL システムを開発しており[6]、その紹介もなされた。
以上、同じく TEI とグラフ・データというテーマを扱いつつも、やや毛色の異なる2つの報告を紹介した。しかし、グラフ形式のデータを XML ファイルから生成するか、最初から XML 以外のデータとして記述するかという手法の違いはあるとはいえ、いずれも XML による構造上の限界を超えた情報記述を志向するという点では共通している。さらに、本会議における筆者自身のロングペーパー報告もじつは、このような文脈に位置付けられるものである。筆者は、XML によるマークアップは文献学的情報など XML によるリニアな構造化が適する最小限の情報に留め、それ以外のセマンティック情報は RDF で記述した上で XML と接続する手法を提案した[7]。こうした、XML の枠を超えた知識記述手法として TEI を捉える動きは今回の会議においても一定の存在感を有していたように思われ、実践研究も含めた今後の発展が期待されるとともに、筆者自身も及ばずながら取り組んでいきたいと考えている。
イベントレポート「Joint MEC TEI conference 2023参加報告」
今回の TEI カンファレンスは MEI との初の合同カンファレンスであり、2023年9月4日から9月8日の5日間にわたってドイツのパーダーボルン大学にて開催された。TEI の活動については既に何度も紹介されているが、ここで再度簡単に整理しておくと、TEI とは Text Encoding Initiative の略称であり、人文科学における機械可読テキストの符号化(encode) 方法を指定する一連のガイドラインを発行している[1]。対して、MEI は Music Encoding Initiative の略称であり、主に音楽ドキュメントを符号化するためのガイドラインを提供している[2]。こうした2つのコミュニティによる合同カンファレンスということで、本来であれば、合同カンファレンスならではの試みに焦点をあてた学会報告を試みるべきではあるが、筆者の専門が日本近代文学ということもあり、そちらへの応用可能性を踏まえて、校合についてのワークショップ「Thinking about collation」と筆者らのポスター発表を中心とする報告になることを最初にお断りしたい。
さて、デジタル環境が発達するに従って、学術的な観点に即して作られる scholarly edition(ここでは仮に「学術編集版」と訳す)を、デジタル環境下で作成する事例が増えている。こうした試みをデジタル学術編集(digital scholarly editing)といい、またその成果物はデジタル学術編集版(digital scholarly edition)と呼称される。本会議の2日目のワークショップ「Thinking about collation」は、まさにこのデジタル学術編集の特にテキストの異なるバージョンを比較する校合作業に焦点をあてたものである。ワークショップでは、校合とはどういった作業なのかという根本的な確認から始まり、どの程度の違いがあれば違うバージョンとして扱うべきなのか、また校合作業を行うにあたって、どのようなツールが最も適切な助けとなるか等の問題が提起され、参加者同士の議論が促された。その中で紹介された事例として興味深いのは Flankenstein variorum の Variorum viewer である[3]。サイトを確認すれば了解できるように、これは「フランケンシュタイン」の5つのバージョンを比較できるようにしたものである。例えば、草稿の本文をベースとして表示させると(CHOOSE A VERSION で「MS」を選んだ後、「variations」を表示させる)、当該部分がどのように発展していったのか他のバージョンとの比較で確認できるようになっている。また、LERA という自動校合ツールも紹介された[4]。LERA は利用者が文書をアップロードするだけで、TEI ガイドラインに準拠した符号化を自動的に行う機能をもっており、エクスポートも可能である。実際にこうしたツールを使ったプロジェクトがいくつも進行中であり、学術編集版を考える際、またその実践の際にはこうしたデジタルツールの使用が検討されるようになっている。LERA の運営チームはデジタル編集版作成プロジェクトにおいて、当該ツールの使用を考えている場合、連絡をすればブラウザ経由でアクセス可能であると述べているので、日本近代文学においても、異同の多い作品で試してみても面白いかもしれない。
続いて、筆者らのポスター発表の紹介に移るが、筆者らの発表もデジタル学術編集版に関連する物である。作家の草稿のデジタル学術編集版に関しては、テキストの意味構造に焦点をあてたマークアップ方法(text-oriented markup, 前段で紹介した Frankenstein variorum はこの方式を採っている)ではなく、テキストが書かれている物理的な文書に焦点をあててマークアップする方法(document-oriented markup)を採る場合がある。この方法は、テキストの個々の要素の配置などが重要となる草稿においては非常に有用な方法である。実際にこうした観点でマークアップを行ったデジタル学術編集版 はヨーロッパにおいては既にあり、プルーストの草稿を用いた試みや[5]、Shelley-Godwin archive の事例がそれにあたる[6]。こうした手法の日本近代文学の草稿資料における有効性を実証してみるべく、筆者らは(発表題目「A Preliminary Proposal for Digital Scholarly Editing that Uses Modern Japanese Autograph Manuscripts: How to Markup Autograph Manuscripts of Rampo Edogawa」)江戸川乱歩の「二銭銅貨」草稿[7]のマークアップを通して日本近代文学の草稿資料におけるデジタル学術編集についてのポスター発表を行った。現在、日本近代文学において、草稿の紹介はデジタル環境下では画像の提供、紙版においては翻刻と草稿の画像のセットという形で主に行われている。しかし、近代の作家のくずし字が研究者にとっても読みにくいことを考えると画像のみの提供は研究利用において不便を感じる状況となっている。紙版での翻刻は、草稿での手入れが多岐にわたる場合、その分多くの記号を用いて加除訂正等を表現せざるを得ず、版面が煩雑となり可読性が著しく損なわれる。また、草稿内に複数のバリエーションが存在しても、作家の加除訂正等を反映させたテキストの「最終形」のみが翻刻されるため、生成批評の観点からは不十分な点が残る場合がある。こういった状況をより適切に記述し表現するための手法が TEI ガイドラインにおける document-oriented markup である。これに沿って、筆者らは江戸川乱歩の「二銭銅貨」草稿をマークアップする際、執筆段階ごとの文章の状況を<creation>、<listChange>、<change>タグを用いることで表現した。また、乱歩に特有なくずし字の使用方法は<charDecl>、<glyph>、<localProp>、<mapping>、<g>等を用いて表現した。この発表の背景について簡単に説明しておくと、これらのタグで記述した情報は、いずれも、紙版ではカバーしきれない物理的な情報である。このように様々なタグが挿入されたテキストは一見すると複雑なものになるが、デジタル媒体においては、そのような多様な情報を利用者の必要に応じて表示したり非表示にしたり、あるいは様々な視覚化を行うなど、多様な利活用が可能となる。
筆者らのポスター発表に対し、多種多様な質問があったが、文化的な差異に起因する根本的な質問が多かったことに驚いた。例えば、日本近代文学の資料は縦書きで右から左に読んでいくが、かなりの質問者に読む順番を確認された。また、日本において作家は作品を執筆する際に、基本的に原稿用紙を使用するが(勿論例外も多数ある)、その原稿用紙とはどのようなものかとも尋ねられた。こうした質問が示すのは、日本の草稿資料において当たり前であると考えられている物事は、海外においては共有されていない物事であるということである。今後の課題としては、日本語とは異なる文化圏の草稿資料と比較しながら、日本語草稿資料の特性を正確に把握しつつ、デジタル学術編集のより良い方法を検討することが挙げられるだろう。
◆編集後記
このところ、人文学におけるデジタル媒体の特性を活かした研究基盤とその活用方法が注目を浴びつつあります。先日公表された文部科学省の概算要求の中には、「人文学・社会科学のDX化に向けた研究開発推進事業」ということでそれをテーマとするものがありました。そして、11月18日(土)には、そのようなテーマをめぐり、当研究所などが主催して国際シンポジウム「デジタル・ヒューマニティーズと研究基盤:欧州と日本の最新トレンド」を開催することになりました。EU による人文学向けデジタル研究基盤事業 DARIAH の director、Toma Tasovac 氏をご招待しての同時通訳付きイベントです。参加費無料・要申込、ということで、今回は恐縮ですが、基本的には対面イベントということになりますので、お近くのみなさま、あるいは、この時期に会場近辺に来ておられる方々におかれましてはふるってご参加ください。(永崎研宣)
- コメントを投稿するにはログインしてください