人文情報学月報第89号【前編】
目次
【前編】
- 《巻頭言》「原典回帰—パラ言語を補完する人文情報学」
:国立国語研究所 - 《連載》「Digital Japanese Studies寸見」第45回
「「くずし字データセット」と「KMNIST データセット」」
:国文学研究資料館古典籍共同研究事業センター - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第9回
「テクスト・リユースと間テクスト性研究の歴史と発展」
:ゲッティンゲン大学
【中編】
- 《連載》「東アジア研究と DH を学ぶ」第9回
「DH 研究情報の集約と発信に向けた取り組み」
:関西大学アジア・オープン・リサーチセンター - 《連載》「Tokyo DigitalHistory」第8回
「Omeka S を用いたデータ管理システムの試作」
:東京大学情報基盤センター
【後編】
- 特別寄稿「Carolina Digital Humanities Initiative Fellow の経験を通じて〈前半〉」
- 人文情報学イベントカレンダー
- 編集後記
《巻頭言》「原典回帰—パラ言語を補完する人文情報学」
周辺事象志向
恐らく自分は、ひねくれ者の部類に入る人間なのだろう。昔から傍流ばかり選ぶ傾向にある。
1995年、Windows95がリリースされたその年に大学4年生だった私は、日本語を格文法に当てはめることに夢中になっていた。しかし、なぜか研究対象として選んだのは格助詞「で」。家にある書籍という書籍の「で」に〇を付け用例を採取しまくるという奇行を妹たちが心配し、「お姉ちゃんは頭がおかしい」と母親に訴えたそうだ。せっかく読もうと手にした村上春樹が、〇囲みの「で」に溢れていては、物語に集中できようはずもない。妹たちはいまだに小説を読まない。彼女たちから物語を読む喜びを奪ったことは申し訳なく思う。
TEI との出会い
10年後の2005年、国立国語研究所の非常勤研究員として『現代日本語書き言葉均衡コーパス』(BCCWJ)の設計・構築に参画を許された私は、当時の上司、山口昌也さんと一緒にテキストエンコーディングの仕様策定を担当することになった。議論の末、BCCWJ が新聞や雑誌の1記事、書籍の1章などのまとまりのある文章をサンプルの単位として収録すると決まった時、私はこのコーパスが文法や語彙だけでなく文章や文体の研究にも利用できるコーパスになることを期待した。周辺事象志向ゆえか、当時の私は言語の特徴に関して、新聞・雑誌・書籍・Web などの発表媒体や書き手の位相による差以上に、文章の中のどのような部品かによる差の方に関心を持っていた。文章のタイトルにはタイトルなりの、キャプションにはキャプションなりの、箇条書きには箇条書きなりの文法や用字法・用語法があり、また、文章の種類によって、どの部品を組み合わせて構成されるかに特徴が見られる。そういったことを研究できるコーパスにしたいという妄想(?)に駆られていた時出会ったのが、TEI による文書マークアップだ。山口さんが「これからは TEI です」とおっしゃったせい(お陰)で、来る日も来る日も TEI のガイドラインと向き合うことになった。
TEI は、私が思い描く「文章の部品」の記述に極めて有用な夢のスキーマだった。が、いかんせん時期尚早。当時、TEI で構造化された日本語の文章など皆無に等しく、5年間で1億語を超える大規模なコーパスを作成する、しかもそのすべてに斉一な単語情報を付けて公開する、という至上命令を前に、BCCWJ を TEI で作るという夢は一笑に付されたのだった…。
しかしその後、子育てのため現場を離れているうちに進行していた『日本語歴史コーパス』では、なんと TEI 準拠の構造化が採用されていた。2013年現場復帰した私は、ようやく時代が追いついてきたな、とほくそ笑んだ。否、ただただ、山口さんの先見の明にリスペクトの思いを強くしたのだった。
最新の情報学利用
そして2018年、私は新たに “異分野融合による「総合書物学」の構築” というプロジェクトにかかわることになった。多角的な視点で書物を分析し、書物の持つ可能性を探るというこのプロジェクトで、国語研は、表記や書記の状態、書物の版面の形状などを総合的・重層的に捉え、それぞれの相関について文献学や計量国語学の手法を用いて解明することを目的に、精緻な表記情報・書誌形態情報を加えた言語コーパスの開発を進めている。
現在、その第1弾として、「人情本」と呼ばれる江戸時代末期の恋愛小説の版本(木版印刷本)を対象に、文字の連綿(切れ続き)の情報、Unicode に基づく変体仮名の字体情報、口絵や挿絵等の図版の情報を XML 形式で格納した構造化テキストを作成している(もちろん、これも TEI 拡張)。連綿や変体仮名の Unicode 情報を持つコーパス構築というのは、恐らく初の試みだろう。
例えば『比翼連理花廼志満台』という作品[1]の初巻の仮名に、変体仮名を含む Unicode10.0を適用してみる[2]。対象となるのは、本文行の仮名4,552字とルビの仮名2,582字。このうち、一つの音価に対して一つの仮名しか持たないものは48音中14音で複数の仮名を持つものが34音、最も多いのは5文字の仮名を持つ「つ」「な」「も」「る」であるということ。あるいは、ある音価を表記する文字に、使用頻度等により代表的な字体が認められる時、それが現行の平仮名と一致するのは48音中32音(三分の二)だということ。またあるいは、「し」の仮名には、①「志」を字母とする U+1B048、②「之」を字母とする現行仮名の「し」、③「し」の跳ね上げがない U+1B045の3字体があり、それぞれ①は語頭か行頭、②は語中濁点付き、③は語中標準と、使われ方に偏りがあるということ。コーパスに Unicode 情報を与えるということは、例えばこんなことが「秒で」分かるようになるということだ。
そして、原典回帰
一方で、書物の部立てやページ・行、書きぶりなどの情報を得て初めて、その字体の使用理由を知ることもある。前述の資料では「も」に5種の仮名が用いられている。①「毛」を字母とする現行仮名「も」、②「毛」の草化(くずし)が進んでいない U+1B0D9、③現行「も」をさらにくずした U+1B0DA、④「母」を字母とする U+1B0D7、⑤「裳」を字母とする U+1B0DC。ただし、通常用いられるのは③のみで、他の4字体は序文(物語に先立ち創作経緯などが示される部分)にしか出現しない。この序文は、背景に模様が刷り込まれ、とても優麗かつ格式のある書きぶりで、極めて装飾性の高い部分だ。実は、同様に、本文では見られず口絵や挿絵のページでのみ用いられる字体というのが散見されることから、芸術性・装飾性の高い箇所でのみ現れる字体が存在するということに気づく。さらには、隣接位置に同じ字体を表記しない配慮なども見て取ることができ、いかに当時の書字意識が繊細であるかに感動すら覚えるのだが、こういったことは、文字の連なり、語の連なり、文の連なりだけを相手にしていては得られない、書物を丸ごと対象とするからこそ得られる新しい知見と言える。
原典万歳! 原典に戻ろう! 周辺事象志向の私は快哉を叫ぶ。
国語研が提供する歴史資料のコーパスでは、こういった「やっぱ原典に戻らないとね」を実現する手立てとして、可能な範囲で底本の画像およびその情報を共に公開している。IIIF の画像 API を用いて、コーパスで検索した用例の周辺行を表示するなどの機能を持つものもある。原典画像との対応付けは、今後さらに様々な形態によって提供されることになるだろう。
コーパスと人文情報学
コーパスは、そのものが情報学を最大限活用した人文学である。そして、コーパスの構築基盤や利用の周辺を固める様々な技術・方法も、やはり情報学の恩恵を大いに受けている。
人文情報学がその利用を支えてくれる、文字列の外にあるさまざまな情報。これは、言ってみれば「パラ言語」のようなものかもしれない。「パラ言語」とは主に音声言語研究に用いられる用語で、発話における言語外の情報(表情や声のトーン、ジェスチャーなど)を指すが、書き言葉においても同様に、言語外の様々な背景情報をそう呼んでも良いように思う。一般的な文字化をした時に落ちてしまう、でも伝達上実はとても大切な情報、そんなパラ言語情報を実に端的に補完してくれる大事な相棒。それが、私にとっての人文情報学だ。
執筆者プロフィール
《連載》「Digital Japanese Studies 寸見」第45回
「「くずし字データセット」と「KMNIST データセット」」
2018年12月8日、人文学オープンデータ共同利用センター[1](以下 CODH)は、文字自動認識研究において標準的なデータセットである「MNISTデータセット」に準じたかたちでデータセットを構築した「KMNIST データセット」(以下 KMNIST データセット)を公開した[2]。これは、文字字形データセット「日本古典籍くずし字データセット」[3]をもとにしたもので、データの内容にあわせて「Kuzushiji-MNIST」「Kuzushiji-49」「Kuzushiji-Kanji」の3種類が提供されている。
MNIST(Modified NIST)データセットは、Léon Bottou や Yann LeCun らが1994年に公開したもので[4]、NIST(アメリカ国立標準技術研究所)が1992年に国勢調査票文字認識コンテストのために配布した訓練用の Special Database 3と試験用の Special Database 7(別名 Test Data 1)のデータの数字に関するデータを組み替えて作ったものである[5]。もともとのデータセットでは(縦横)20×20の白黒二値画像であったものが、MNIST データセットでは28×28の独自形式のグレイスケール画像とされ、それが文字認識用データセットの標準的な規格として用いられるようになった。各字に訓練用については6万例、試験用については1万例が各字に用意されている。KMNIST データセットは、この MNIST 形式にあわせて日本古典籍くずし字データセットを加工したものということになる。
日本古典籍くずし字データセットは、KMNIST データセット公開に合わせて「日本古典籍字形データセット」から改称したもので[6]、もともとは、古典籍 OCR[7]の開発の際の副産物として生み出されたものをデータセットの形式にしたものである[8]。現在でも拡充が続くほか、国語研からもデータ提供を受けている。ラベルは現代の仮名に正規化されており Unicode の変体仮名はとくに活用されていないが、活用するには十分な訓練データを用意できない問題が指摘されており、今後も難しいと言われている。そもそもコンピュータ用に変体仮名のテクストを得たいのかが問題ではある。それはさておき、CODH では、このデータセットをもとに「くずし字チャレンジ!」として PRMU アルゴリズムコンテストの一環としてすでに機械学習による文字認識コンテストを開催しており[9]、たんに公開するだけでなく活用のための多様なチャンネルを模索していた。今回の公開もその一環であろう。
KMNIST データセットは、GitHub で公開されている[10]。Kuzushiji-MNIST データセットは、MNIST 形式にあわせて10字にそれぞれ6万例の訓練データと1万例の学習データを提供する。複数の仮名字体がひとつの現代の仮名のラベルのもとに提供されていることにより、MNIST データセットよりも機械学習上考慮すべきことが多くなり、多様なチャレンジが求められることが重要であるという。Kuzushiji-49データセットは平仮名全字と踊り字「ゝ」、Kuzushiji-Kanji データセットは漢字について MNIST の画像サイズに基づいてデータ提供するものである。こちらは、実例の偏りもあり MNIST 形式ではない。
KMNIST データセットの目標のひとつに、「MNIST のバリエーションとしての KMNIST を気軽に使ってみることで、くずし字を対象とした研究に興味をもつ研究者を増やすこと」があるという。人文学は「くずし字」という一語を越えた世界をあきらかにしてきた。KMNIST データセットが扉を開けたその先には、どんな多様性が描かれていくのだろうか。
Tarin Clanuwat, et al., “Deep Learning for Classical Japanese Literature,” arXiv:1812.01718 (2018).
現状、KMNIST データセットが依拠した具体的なデータは公開されていない。
Léon Bottou, et al., “Comparison of Classifier Methods: A Case Study in Handwritten Digit Recognition,” in vol. 3 of Proceedings of the 12th IAPR International Conference on Pattern Recognition, 1994, doi:10.1109/ICPR.1994.576879.
NIST Special Database 19 doi:10.18434/T4H01C
Gregory Cohen, et al., “EMNIST: an extension of MNIST to handwritten letters,” 2017, arXiv:1702.05373
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第9回
「テクスト・リユースと間テクスト性研究の歴史と発展」
デジタル・ヒューマニティーズにおけるテクスト・リユース研究は現在ヨーロッパにおいて発展している。テクスト・リユース(text reuse、あるいは、text re-use)とは、引用、引喩、パラフレーズ、剽窃、諺、イディオム、言い回しなど、あるテクストを元に統語的、または意味的に同一な、または、類似性のあるテクストを用いる人間の創作活動においてよく起こる現象のことである。ここでは、イディオムや諺、言い回しも、リユースであると認識される。テクスト・リユースはコンピュータ言語学の分野で発達した概念だが、それは、ヨーロッパにおける哲学・文学理論で発達した「間テクスト性」と扱う対象が似ている。そのため、現在、デジタル・ヒューマニティーズの分野で両者の統合が盛んに行われている。この研究では、起源となったテクストをソース・テクスト、簡略化して「ソース」、ソースの要素が用いられた(「再利用」された)テクストをターゲット・テクスト、または「ターゲット」と呼ぶ。
まず、最も代表的なテクスト・リユースとして、引用が挙げられる。引用は、ソースとターゲットの違いの度合いに応じて、そのままの引用(verbatim quotation)、多少の変化はあるがそのままに近い引用(near-verbatim quotation)などがある。変化の度が大きすぎるとパラフレーズになる。引用する際に、近代以前の著者は、しばしば引用した文章の語句を、ターゲットの文脈に合わせて、比較的に自由に変化させることが多い。また、引用元を明示しないことも多々ある。現代ならば、パロディやオマージュといったジャンルでない限り、引用は忠実な引用でなければならず、引用元も明示しなければ、「剽窃」として非難されるが、近代以前は必ずしもそうではなかった。一方、引喩(allusion)は、ソース・テクストの内容やイベントをターゲット・テクストで言及し、読者にソースの内容を想起させてターゲット・テクストを解釈させる手法である。日本古典文学では、(諸説あるが)和歌の本歌取りが有名である。引喩に関しては、他の定義もあり、研究者間で多少の違いはあるものの、引用が(無論意味も含むが)統語的テクスト・リユース(syntactic text reuse)の代表格であるのに対して、引喩は意味的テクスト・リユース(semantic text reuse)の代表格である。
テクスト・リユースはコンピュータ言語学の用語として発達してきたが、それは、主に、テクスト・リユース探知の分野においてである。テクスト・リユース探知(text re-use detection)とは、簡単にいえば、1つ以上のテクストをコンピュータに与え、コンピュータにそ(れら)のテクストの中からテクスト・リユースを見つけさせる技術である。多くの場合は,比較されるテクストは1つ以上であり、言語は同一のものだが、1つのテクストのなかで類似するフレーズを探すのもテクスト・リユース探知に入る他、最近では複数言語間のテクスト・リユース探知も研究されている。テクスト・リユース探知は、コンピュータ言語学の分野において、データ・マイニング(data mining)をテクストに応用したテクスト・マイニング(text mining)の発展の中で開発されてきた剽窃探知のプログラムを中心に発展し、近年、この技術が、剽窃という社会的悪を発見するという実用的なものでなく、近代以前の、引用元や引喩元を明示しない文化におけるテクスト・リユースを研究する、という純学問的・人文学的な目的で用いられるようになったものである。
哲学や文学理論の分野では、コンピュータ言語学から発展してきたテクスト・リユースとは別に、「間テクスト性」(intertextuality/intertextualité)という概念が発達してきた。ブルガリア系フランス人哲学者ジュリア・クリステヴァ(Julia Kristeva)、1969年に発表された著書において、ロシアのミハイル・バフチン(Mikhail Bakhtin)のカーニヴァル論やオーストリアのジークムント・フロイト(Siegmund Freud)の精神分析学、そしてスイスのフェルディナン・ド・ソシュール(Ferdinand de Saussure)のアナグラム論に影響を受けた「間テクスト性」という概念を発表した。間テクスト性とは、テクストにおいて、他のテクストから取られた様々なテクストの断片が互いに交差しているという性質のことである[1]。この「間テクスト性」の研究は、ジェラール・ジュネット(Gérard Genette)らによって、洗練され、ハイパーテクストなど様々な種類の間テクスト性の関連概念が編み出された[2]。筆者の研究する初期キリスト教文学の分野でも、この間テクスト性の研究が盛んになってきている。例えば、この分野を含む学会で最も大きなものとして聖書文学会(Society of Biblical Literature)があるが、オンライン上で公開されている当学会のアメリカでの年次大会のアブストラクト・ブックを調べると、intertextualityのタイプ頻度は年々増えている傾向にある。
間テクスト性を生み出したフランス、そしてその隣国のドイツでは、哲学から出た間テクスト性の研究とコンピュータ言語学から生じたテクスト・リユース研究を統合させる動きが、デジタル・ヒューマニティーズの世界で起こっている。初期のものとしては、Biblia Patristica[3]のデジタル化が挙げられる。Biblia Patristica はキリスト教のいわゆる教父文学[4]における聖書からの引用や引喩のリストであるが、最初は、紙媒体で出版されたのみであった。しかし、フランス国立科学研究センター(Centre National de la Recherche Scientifique、略して CNRS)の BiblIndex(https://www.biblindex.info/)というプロジェクトによって全てオンラインでクエリによる検索が可能なデータベースとなって公開されている。これは、テクスト・リユースのデータのデジタル化・データベース化のプロジェクトとしては非常に優れたものであるが、テクスト・リユースは自動で探知されたものではない。
西洋古典学における初期の自動テクスト・リユース探知(automatic text reuse detection)のプログラムとして、Tesserae[5]が挙げられる。これはアメリカのニューヨーク州立大学バッファロー校の Neil Coffee のチームが開発しているもので、彼らの論文によれば、ウェルギリウス(Vergilius)の『アエネイス』(Aeneis)とルカヌス(Lucanus)の『ファルサリア(内乱)』(Pharsalia/The Civil War)において、それまでの西洋古典学の学者たちが見つけることができなかったテクスト・リユースを Tesserae は46も発見した。
近年では、タフツ大学の Perseus Digital Library(http://www.perseus.tufts.edu/)のリーダーである Gregory Crane が率いるライプチヒ大学のフンボルト・デジタル・ヒューマニティーズ講座はこの分野の研究で突出してきている。このライプチヒ大学において Marco Büchler は、古典文学におけるテクスト・リユース探知で博士論文を書き、その後、古代ギリシア語最大のコーパスである Thesaurus Linguae Graecae で自動でテクスト・リユースを探知する eAQUA(http://www.eaqua.net/)、そして、eTRACES プロジェクト(https://dig-hum.de/forschung/projekt/etraces)で TRACER という汎用テクスト・リユース探知ソフトウェアを開発し2015年から、ドイツ連邦教育・研究省の4年間1.6万ユーロの助成金を獲得し、ゲッティンゲン大学のゲッティンゲン・センター・フォー・デジタル・ヒューマニティーズおよびコンピュータ科学研究所の eTRAP リサーチ・グループ(https://www.etrap.eu/)で開発が引き継がれた。現在は、英語、ドイツ語、古代ギリシア語、ラテン語、チベット語、コプト語、ヘブライ語、アラビア語でこのソフトウェアの成功例がある。筆者は、このプロジェクトのコプト語のパートにコプト学者として参加し、西暦 4–5 世紀に生きた上エジプトの修道院長であるアトリペのシェヌーテの著作にある古いコプト語訳聖書からの引用・引喩を探すのに用いている。見つかった聖書からの引用は、コプト語訳聖書で見つかっていない箇所のものもあり、聖書のうち紀元後2–4世紀になされた非常に古い訳から取られたはずなので、コプト語訳聖書のみならず、ギリシア語新約聖書や70人訳旧約聖書の本文批評学[6]にとって重要なものも数多い。
現在、例えば、シェヌーテの『第六カノン』というテクストで、19世紀末から、すでに引用が過去の研究者によって研究された部分だけでも、旧約聖書の詩篇だけで14の未発見の引用が見つかっている。『第六カノン』は、未発表の断片も全体の5分の1ほどあり、筆者たちはそのデジタル・エディションを作成しているが、その部分でも多数のテクスト・リユースが発見されている。いったん Karl Heinz Kuhn によって引用と引喩が隅々まで研究された[7]、シェヌーテの弟子のベーサの手紙・説教集と旧約聖書の詩篇からは18の未発見の引用が TRACER によって発見された。現在、よりレンマ化などを洗練させたコーパスで再度分析を行なっている。これらの結果は筆者の博士論文で詳述される。
TRACER は WordNet のデータを与えると、意味論的テクスト・リユースをより多く発見できるようになる。そのため、現在は、コプト語の WordNet をオスロ大学の Laura Slaughter と 南洋理工大学の Luís Morgado da Costa とともに開発している。また、テクスト・リユースの結果を用いて、様々な視覚化がなされた Web ページが、ライプチヒ大学の Stefan Jänicke が開発した TRAViz によって JavaScript を用いた HTML として生成される。
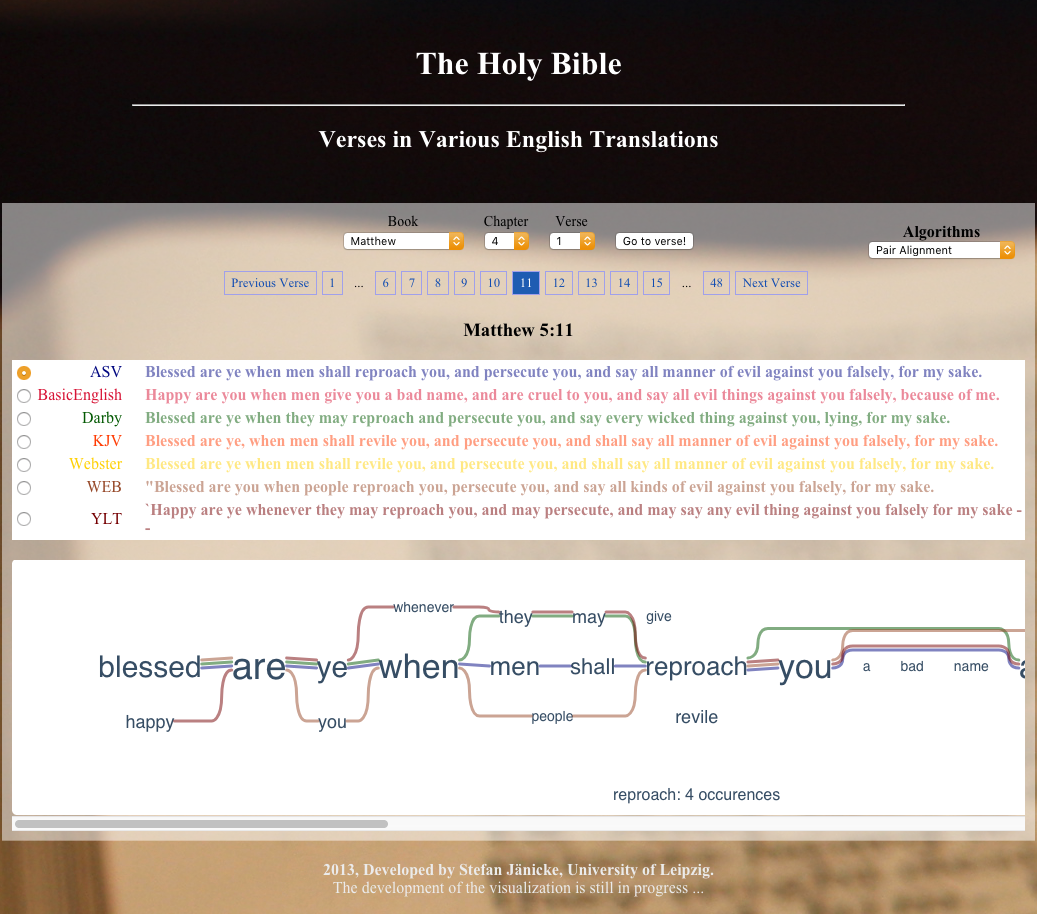
ライプチヒ大学の Monica Berti が主に執筆しているブログである Fragmentary TextsQuotations and Text Re-uses of Lost Authors and Works(http://www.fragmentarytexts.org/)では、TEI などテクスト・リユースに関わる事項がよく解説されているほか、アテナエウス(Athenaeus)などのテクストのテクスト・リユースの TEI XML によるマーク・アップの例、そして X テクノロジーを駆使したテクスト・リユースの視覚化のデモを見ることができる。Monica Berti や Gregory Crane をはじめとするこの fragmentarytexts.org のプロジェクトの成果は、論文として発表されている[8]。また、アテナエウスの XML を用いたデジタル・エディションの諸相は Digital Athanaeus(http://www.digitalathenaeus.org/)で公開されている。
最近では、Wikipedia のデータを活用した Picapica(https://www.picapica.org/)という新しいテクスト・リユース・ツールが登場したが、これはいくつかの現代語にしかまだ対応していない。
以上、まとめると、DHにおけるテクスト・リユース研究には次の3つのカテゴリーが設けられる。
- 自動テクスト・リユース探知(Tesserae、TRACER、Picapica など)
- テクスト・リユースのマーク・アップ(TEI、fragmentarytext.org など)
- 古いテクスト・リユースの情報源のデジタル・データベース化(BiblIndex など)
この分野は Gregory Crane 率いるライプチヒ大学の Global Philology プロジェクト(http://www.dh.uni-leipzig.de/wo/projects/global-philology-project/)などで学術交流が促進され、筆者もそこで Historical Text Reuse Data Workshop(http://www.dh.uni-leipzig.de/wo/historical-text-reuse-data-workshop/)など、2016年から2017年にかけてライプチヒおよびゲッティンゲンで開催された多数の会議およびワークショップに参加した。ハーヴァード大学の Donald Sturgeon が Chinese Text Project プロジェクト(https://ctext。org/)に関して Global Philology が主催した Global Philology Open Conference(http://www.dh.uni-leipzig.de/wo/events/global-philology-open-conference/)と Global Philology: Big Textual Data(http://www.dh.uni-leipzig.de/wo/events/global-philology-big-textual-data/)で行った2つの発表のように、ヨーロッパ・中東の文献以外の DH における優れたテクスト・リユース研究も知ることができ、大変有意義であった。下の図2は Chinese Text Project(https://ctext.org)におけるテクスト・リユースの一例を表示している画面である。Global Philology のリーダーである、ライプチヒ大学フンボルト・デジタル・ヒューマニティーズ講座教授の Gregory Crane は、DH におけるオープンデータ、オープンソースを推進しており、彼の関係したプロジェクトは、その多くがコードやソースがオープンで入手可能である。ライプチヒ大学における Marco Büchler の博士論文での研究が元になった TRACER も GitLab でコードを手に入れることができる(https://vcs.etrap.eu/tracer-framework/tracer)。

- コメントを投稿するにはログインしてください