人文情報学月報第154号【前編】
ISSN 2189-1621 / 2011年08月27日創刊
目次
【前編】
- 《巻頭言》「人文学と情報学、そして人文情報学を学ぶことの可能性」
:九州大学大学院人文科学研究院 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第70回
「機械翻訳モデルの評価方法と Hugging Face Evaluate Metric」
:筑波大学人文社会系 - 《連載》「仏教学のためのデジタルツール」第18回
「ACIP」
:東京大学大学院
【後編】
- 《特別寄稿》「歴史研究における「解釈行為」をモデル化する試み(3):来歴情報記述のための PROV Ontology とその歴史解釈行為構造化への応用可能性」
:国立情報学研究所 - 人文情報学イベント関連カレンダー
- イベントレポート「DH 国際シンポジウム「ビッグデータ時代の文学研究と研究基盤」
:国文学研究資料館 - 編集後記
《巻頭言》「人文学と情報学、そして人文情報学を学ぶことの可能性」
九州大学人文科学研究院は2022年度のデジタルと掛けるダブルメジャー大学院構築事業 (通称 X プログラム) に応募し、採択された。
事業計画名称は「ウェル・ビーイングの実現に貢献する高度人文情報人材養成プログラム:人文学×データサイエンスによる「人文情報学」大学院の設置」である。
筆者は2024年2月に九州大学に着任し、本プログラムの実現に向けて活動中である。本稿ではこれをきっかけとして、人文学、人文情報学の教育について筆者が考えたことを述べたい。
人文系の学生が情報技術を用いて行うことはどんなことだろうか?紙の資料を精読したり、フィールドワークで人から聞いた一次情報を書き取ってまとめてきた学生にとっては、そのような資料をデジタル化することが、まずできることだろう。その資料から読み取ったこと(例えば人名や地名を同定したり、同じ対象を指示する異なる固有名の同定の情報)を注釈としてデジタル化されたデータに書き込み、分析の過程を明示的にすること、また注釈を検索・集計するなどして分析に役立てることができれば、研究の効率が上がるだけでなく、思いもかけない関連が発見されるなどして分野に新たな知見をもたらすだろう。また、資料そのものをデータベース化することも需要の1つである。
くずし字などの手書き文字の解読、単語の解釈から、作者の表現しようとしていること、作者の意図とは異なるかもしれないが読み取れること、社会に与えた影響など、あらゆるレベルで資料を正確に読解する訓練を受けてきた学生が持つ能力は、このプロセスと作業結果を明示的にする必要があるデジタル資料への注釈作業において大きな力を発揮するだろう。また、このような訓練を受けなければ、学術的に有意義な注釈はそもそも不可能である。そもそも、きちんとした一次資料についての知識があることも人文学の訓練を受けてきた学生の重要な能力である。学部でこのような人文学的な教育を受けてこなかった学生には、このことの重要性を強調するのが肝要であると思う。
このような能力を身につけた学生が、デジタルデータをデジタルデータとして自分の専門分野にとって有意義な単位に分け、構造化し、有用な注釈方法を身につければ、学術研究だけでなく、ビジネスの現場においても重要な役割を果たすことになると考えられる。なぜならいずれにせよ扱っているのは文書であり、人から人へと伝えられてきた知恵や決定事項の集合であるからである。
私見では、学術界においてもビジネスにおいても、資料をデジタル化し、機械が扱いやすいように構造化して検索したり、ファイルの版を管理したり、今までの知見や決定事項の共有を簡単にしたりする需要は数多く存在するように思われる。情報技術を学んだ人文系の学生はこのような需要に応え、活躍することが期待される。
より広い視点で考えてみると、自分の所属集団の知識や決定事項とその来歴を知り、それに基づき思考することは市民社会の一員として生きるうえでの基本である。そのような観点から、我々の取り組みがより良い社会の創造に寄与していくことを願っている。
以上のような問題意識を持ちながら、学際的なシンポジウムのシリーズを2024年度に行うことを企画している。興味のある方はぜひご参加の上、討論を活性化させていただきたい。
執筆者プロフィール
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第70回
「機械翻訳モデルの評価方法と Hugging Face Evaluate Metric」
機械翻訳は、自然言語処理の分野で長い間重要な研究テーマとなっている。機械翻訳とは、ある言語で書かれた文章をコンピュータを使って自動的に別の言語に翻訳することを指す。近年、ディープラーニングの発展により機械翻訳の精度は飛躍的に向上しており、機械翻訳の評価方法について様々な研究が行われている。かつてはルールベースの手法が主流であったが、近年では大量の対訳データを用いた統計的機械翻訳や、ニューラルネットワークを用いたニューラル機械翻訳が主流となっている。
『人文情報学月報』第150号【前編】[1]では、コプト語の機械翻訳システムである Coptic Translator[2]の開発プロジェクトについて述べた。コプト語は古代エジプトで使われていた言語であり、現在では主に古代文献を読むために学ばれているほか、ボハイラ方言という方言は、19世紀後半より言語復興運動が起こっている。Coptic Translator は、2023年12月のリリース当初は、文献が多数残っているサイード方言と英語のみ対応していたが、2024年4月になされたアップデートで、ボハイラ方言および、ドイツ語、アラビア語、フランス語、オランダ語が追加された。筆者は、このプロジェクトのボハイラ方言の機械翻訳モデルを開発するために典礼文や聖歌などのデジタル対訳コーパスを提供した。
この Coptic Translator は、米国のウィリアムズ大学の学部生である Enis と Megalaa が、ウィリアムズ大学の計算機資源を用いて行っている[3]。それに対し、筆者は、これまで、様々な会社が開発した LLM をコプト語で試し、ほとんどコプト語は対応していないことがわかっていた。しかし、2024年3月4日にリリースされた、Anthropic の Claude 3 Opus[4]は、コプト語のサイード方言とボハイラ方言において、まずまずの精度で両方に翻訳したり、自動応答できることがわかった。
なお、5月14日に GPT-4o がリリースされて早速搭載された、OpenAI の ChatGPT[5]や、Google の Gemini Advanced[6]に関しては、コプト語から英語、英語からコプト語への自動翻訳は、翻訳というレベルではなかった。
これらの自動翻訳の性能を客観的に示すために、近年機械翻訳モデルの評価によく用いられている評価尺度を用いた評価を現在行っている。本稿では、これらの性能の評価の報告の他、機械翻訳の評価を GUI(グラフィカル・ユーザ・インタフェース)上で手軽に行うことができるウェブアプリについても紹介する。
もちろん、全ての機械翻訳の評価基準をここで紹介することはできない。しかしながら、よく用いられている BLEU および chrF に、最近用いられることが多くなってきた SacreBLEU および METEOR について特徴や計算方法を紹介する。
これらの評価尺度は Python を用いて簡単に使用することができる。さらに、近年ではいくつかの GUI 付きのブラウザ上で使用することができる手軽なアプリ(図1)が公開されている。特に最もよく用いられている尺度である BLEU に関しては、様々なアプリが存在する。しかしその中でも Hugging Face の Evaluate Metric[7]では、BLEU の他にも SacreBLEU、chrF、METEOR など、様々な評価尺度のアプリが用意され、使用方法も非常に手軽である。使用方法は、二つのテキスト(通常、人間の手による翻訳と、評価したい機械翻訳)をそれぞれのセルに(”)で囲んでから挿入し、計算ボタンを押すだけである。
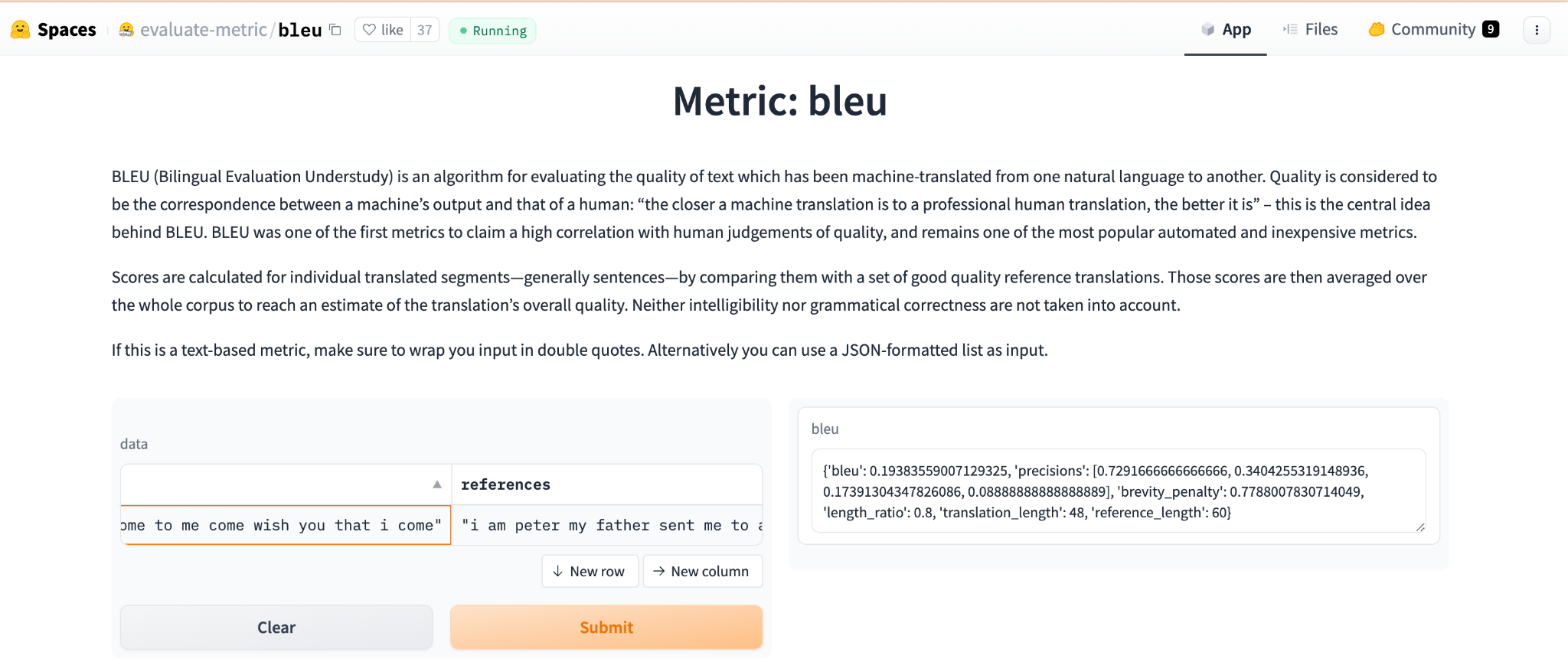
以下で、主な評価尺度についてその概略を述べる。
BLEU(二言語評価アンダースタディ)[9] は、機械翻訳の精度を評価するために最も広く用いられている自動評価尺度で、機械翻訳の出力と参照訳の一致度を連続する単語の組み合わせ(n-gram)で計算し、この n-gram の一致度に基づいて機械翻訳の精度を0から1の間の値で表す。n-gram の一致度に加えて、機械翻訳出力の長さが参照翻訳の長さからどの程度ずれているかも考慮する。これにより、過度に短い翻訳や長い翻訳にペナルティを与え、より適切な長さの翻訳に高い評価を与えることができる。
SacreBLEU[10]は、単語のセグメンテーション(トークン化)やスムージング(n-gram の一致度を計算する際の調整)の方法によって結果が異なるという問題があった BLEU の問題点を改善した評価尺度である。SacreBLEU は、BLEU と同じ n-gram の一致度と訳文長ペナルティを用いて計算されるが、再現性を確保するために計算方法の詳細が厳密に定義されている。
chrF(文字レベル F スコア)[11]は、文字レベルの n-gram を用いて計算される、機械翻訳の出力と参照翻訳の類似度の尺度である。従来の BLEU や SacreBLEU は単語レベルの n-gram を用いるが、chrF は文字レベルの n-gram を用いるため、より柔軟な評価が可能である。
METEOR(明示的順序付を用いた翻訳評価尺度)[12]は、機械翻訳出力と参照訳の一致度に加え、語順の類似度を考慮した評価指標である。まず、機械翻訳出力と参照訳の間で一致する単語を特定する。完全一致だけでなく、類義語や語幹の一致も考慮される。次に、これらの一致する単語を出現順にソートする。ここで発生した語順の入れ替えが数えられ、語順ペナルティとして使用される。最後に、マッチした単語の数と語順ペナルティからスコアが計算される。一致する単語が多く、語順の入れ替わりが少ないほどスコアは高くなる。このように語順の類似性も考慮することで、人間の評価に近い結果を得ることができる。
これらの評価指標を用いて、コプト語から英語への自動翻訳の評価を行った。論文にしか出てこず、少なくとも Coptic Translator の訓練データにはなっていない、カイロ・フランス考古学研究所所蔵のオストラコン(土器の破片)に書かれたコプト語の手紙 Ifao, OC 252 (C 1906)[13]の、コプト学者[14]による訳を reference とし、Coptic Translator と Claude 3 Opus、および GPT-4o の機械翻訳を prediction として、上記の4つの評価尺度による評価を行った。評価の際、全てのテキストを小文字化し、句読点を除去した。
良い結果の例として、定評のある2つの聖書訳(英語標準訳 ESV と新国際訳 NIV)をマルコ福音書1章1–3節で用意し同じように評価してみたところ、どちらも英語訳としてはプロの水準であるが、その値は、100%(BLEU では1.0)にはならなかった。また、"No pain, no gain."という同一のテキスト同士でも最大値として参考のために評価を行った。
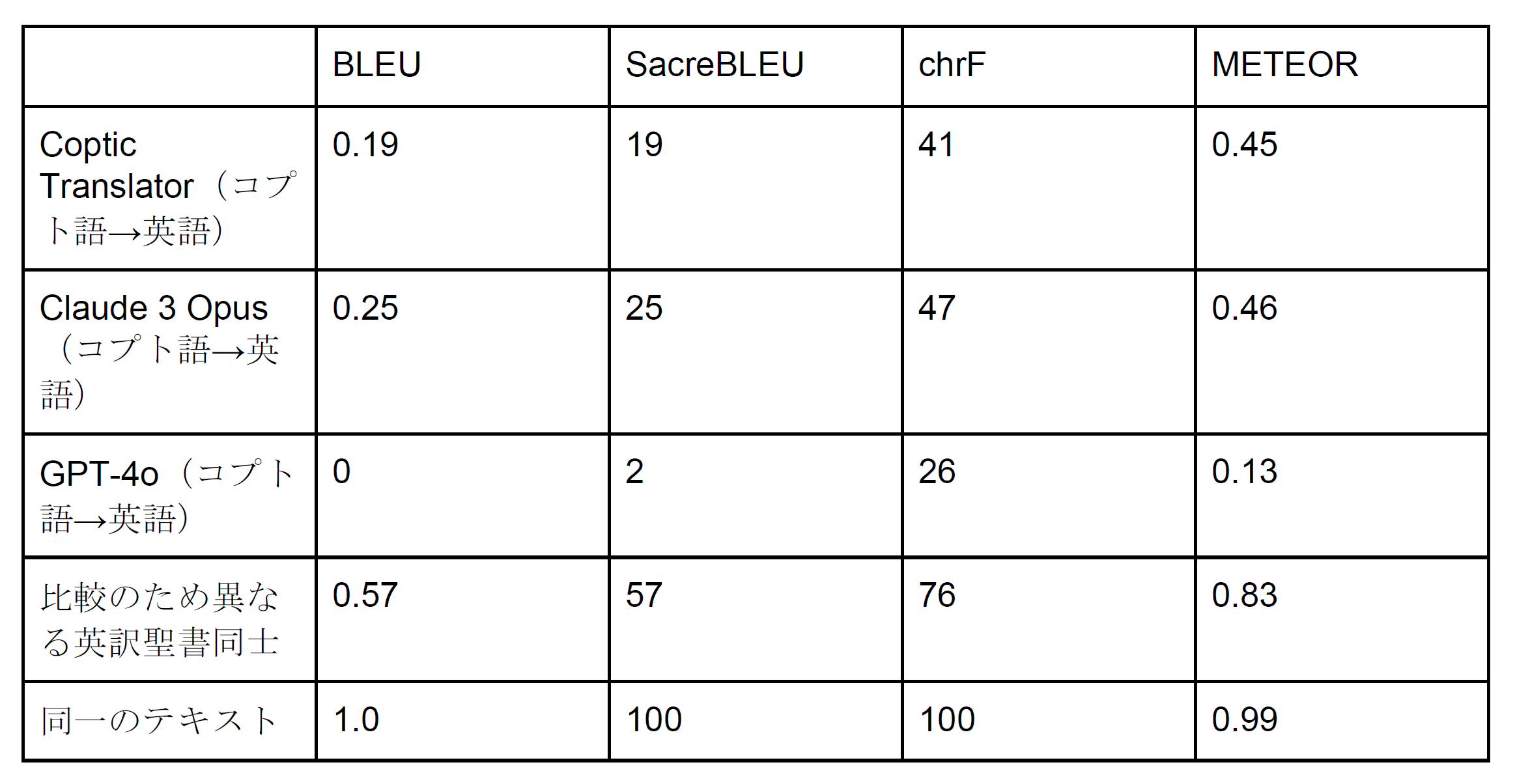
図2のように、コプト語から英語の機械翻訳は、Claude 3 Opus が最も良い性能で、僅差で Coptic Translator が続いていることがわかった。もちろん、今回はオストラコンに書かれた一つの手紙を与えたのみであり、分量的にも客観的な評価ができているとは言えない。しかしながら、人間による評価(コプト学者である宮川)の評価でも、Claude 3 Opus が最も高く、次に Coptic Translator が高く、GPT-4o は翻訳と呼べるレベルではなかった。筆者は、スイスの研究者とともに、これらの民間の LLM を含めた、コプト語および古代ギリシア語の評価結果と分析を行った論文を執筆中である。この論文では、4つのテキストを検証に用い、Coptic Translator と Claude シリーズだけでなく、GPT シリーズや Gemini シリーズにも対象を広げながら、本稿で述べたものを含めた複数の評価尺度を用いて機械翻訳の評価を行った。このような研究に興味を持った読者諸賢はぜひこの論文を参照いただきたい。
《連載》「仏教学のためのデジタルツール」第18回
仏教学は世界的に広く研究されており各地に研究拠点がありそれぞれに様々なデジタル研究プロジェクトを展開しています。本連載では、そのようななかでも、実際に研究や教育に役立てられるツールに焦点をあて、それをどのように役立てているか、若手を含む様々な立場の研究者に現場から報告していただきます。仏教学には縁が薄い読者の皆様におかれましても、デジタルツールの多様性やその有用性の在り方といった観点からご高覧いただけますと幸いです。
「ACIP」
今回は The Asian Classics Input Project が公開している「ACIP」(https://www.asianclassics.org/)を紹介する。ただし2024年5月27日現在、本 URL にはアクセスできない.
ACIP は1987年以降、チベット仏教文献の電子テキストおよび電子目録の作成を逐次進め、その成果をインターネットあるいはCD-ROMを通じて公開してきた。チベット仏教文献は近代以降のチベットにおける政治的・経済的事情からその多くが失われつつある。ACIP はこのような消失の危機に晒されているチベット仏教文献を保存し、次代に継承することを目的として設立された。ACIP によるチベット文献入力作業は経済的苦境に晒されている南インドのチベット難民に対して仕事を提供するとともに、入力されたデータをもとに出版されたテキストは南インドのチベット仏教僧院の教科書として用いられている。このように ACIP の活動はチベット仏教研究者に研究の利便性をもたらすだけでなく、チベット難民の生活に対しても経済的・文化的な貢献をしている。
ACIP が研究者にもたらす最大の貢献はチベット仏教文献の電子テキストの公開である。チベットではインドや中国からもたらされた仏教文献が組織的にチベット語に翻訳され、それら翻訳文献は後にカンギュルとテンギュルからなるチベット大蔵経に集成された。これらカンギュル・テンギュルに収録される全ての文献が電子テキスト化されている。またチベットにおいても学僧たちによる仏教文献の著作活動が行われ、著名な学僧の著作はスンブム(著作集)にまとめられて出版された。ACIP はスンブムから5000以上の作品を電子テキスト化している。
これらの電子テキストは極めて高い精度で入力されている。これらの入力作業は訓練を受けた有給のチベット難民が担っている。ある一つの著作を電子化する際、まず別人の手による二つの入力データを作成する。それらをコンピュータ・プログラミングによって一文字ずつ比較して入力ミスを修正している。確かに同様の試みは BDRC(Buddhist Digital Resource Center)[1]においても行われている。しかし BDRC において作成された電子テキストには Input eText と OCR eText の2種類があり[2]、後者は OCR によって作成され、人力による修正がなされていない。そのため電子テキストの入力精度という観点から BDRC は ACIP に劣後する。また電子化されたテキスト数においても ACIP が BDRC を大きく上回る。
もう一つの ACIP による貢献はチベット文献の電子目録の作成である。チベット本土以外にもチベット仏教文献を多数保有する国がある。これらチベット本土外で保存されているチベット文献コレクションのカタログを ACIP は公開している。ロシアでは帝政時代に探検家や学者が多数の木版本を収集しており、20万点を超える作品が現在サンクトペテルブルクのロシア科学アカデミー東洋学研究所サンクトペテルブルク支部(the St. Petersburg Branch of the Institute of Oriental Studies of the Russian Academy of Sciences)とサンクトペテルブルク大学東洋図書館(the Oriental Library, a part of the Library of the University of St. Petersburg)に所蔵されている。またモンゴルでも約140万点もの木版本・写本が保存されている。これらはウランバートルのガンダン・テクチェンリン寺(Gangdan Tekchen Ling)の図書館とモンゴル国立図書館(The National Library of Mongolia)に所蔵されている。ACIP はこれら4つの図書館に保存されているチベット仏教文献群をそれぞれロシア・コレクションとモンゴル・コレクションとしてカタログ化している。カタログには各作品のタイトル、著者名、コロフォン、サイズ、フォリオ数、所蔵場所が記録されている。これらのコレクションの中でも、とりわけウランバートル所蔵のチベット文献群は他の地域では失われてしまった文献を含んでいる点で重要である。なお、現在はラダック所蔵のチベット文献カタログも公開されているようである。
しかし管見の限りでは現在 ACIP はこれら電子テキストと電子カタログを適切にウェブ上で公開できていない。本記事冒頭に提示したURLは現在アクセスできない。カタログと電子テキストの検索ページ(Asian Classics Explorer)[3]のみ閲覧可能である。このページから、先述のロシア、モンゴル、ラダックの3つのコレクションのカタログを検索、閲覧することができる。一方、電子テキストについては極めて限られた数のカンギュル、テンギュル、スンブムしか検索できない[4]。そのため管見の限りでは、ACIP 作成のカンギュル、テンギュルの全テキストデータにアクセスしたい場合は、仏典検索データベース(The Buddhist Canons Research Database)[5]を経由する必要がある。
上記の事情から本記事は Chilton 2001[6]に基づいて執筆した。この論文は20年以上前に執筆されたものであり、その後 ACIP のカタログに前述のラダック・コレクションなどが追加されたようであるが、ここ20年間における ACIP の活動の詳細は本記事執筆時点で確認できなかった。
- コメントを投稿するにはログインしてください