人文情報学月報第161号【前編】
ISSN 2189-1621 / 2011年08月27日創刊
目次
【前編】
- 《巻頭言》「書名らしさの分析を振り返って思う言語処理の現在」
:筑波大学図書館情報メディア系 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第77回
「デジタルテキスト資料アーカイブ構築が可能にする古代エジプト『死者の書』の計量的研究」
:筑波大学人文社会系
【後編】
- 《特別寄稿》「Camille Desenclos による「10. Early Modern Correspondence: A New Challenge for Digital Editions」(『Digital Scholarly Editing-Theories and Practices』所収)の要約と紹介」
:早稲田大学大学院文学研究科 - 人文情報学イベント関連カレンダー
- イベントレポート「DARIAH Annual Event 2024参加レポート」
:人間文化研究機構/国立歴史民俗博物館 - 編集後記
《巻頭言》「書名らしさの分析を振り返って思う言語処理の現在」
読者の皆さんの多くは、書物の中身にデジタル技術を適用した様々な面白い研究にご関心がおありのことと思う。私も書物に興味があるが、図書館情報学を専門としているためか、少しだけメタなことに学生時代取り組んだ。書物のタイトル、書名とは、普通どのような形をしているだろうか、というものである。例えば『自由論』、『ドゥルーズの哲学原理』のような名詞句になることが一般的に思われるが、『ある日、』や『同志少女よ、敵を撃て』のように、節や文の形をとることも少なくない。見るからに書物のようなものから、それは本当に本のタイトルなのかと思われるようなものまで、さまざまである。
こうした文字列としての「書名らしさ」に関心を持ったのは、何らかの書物についての言及をソーシャルメディアから自動的に収集したかったからだ。人が書物について話すとき、その書物を参照するために、まずは書名を挙げる。もちろん、“村上春樹の新刊、夜通し引き込まれた!”のように、書名以外の書誌情報を参照することも多々あろうが、典型的には読んだ本のタイトルに触れるだろう——“(…)「六人の嘘つきな大学生」ヤバイ!面白すぎる!(…)”[1]。
書名を含む発言を、それら以外の一般的な発言から識別する場合、その発言が権威ある“テクスト”上にあるならば二重鉤括弧が使われるはずなので、素朴なパターンマッチ(正規表現など)でも悪くない。ところがソーシャルメディア上では、書名はほとんどの場合、何ら囲い文字を使われることなく出現しうる——“これからラヴクラフト全集読む”。一重鉤括弧が使われていればまだマシだが、書名以外の何かを囲む方が多い。もっと発言の文脈や意味を考慮したい、それが私と言語処理[2]との出会いであった。
ソーシャルメディア上の発言が書物に関連したものか判定するのは、言語処理のタスクとしてはテキスト分類に相当する。当時は深層学習が言語処理学に輸入され始めた頃で、主流ではなかった。標準だったのは、研究者が試行錯誤の末に見つけた解釈可能な「素性」を設計し、SVM などの機械学習モデルに投入するというものだ。私はまず、日本で刊行された全書名リストが入手可能であることを前提に、何らかの書名に一致する文字列を含む発言の中から、実際に書物に関連するかを識別することにした。実際、全書名リストは国立国会図書館等の書誌 DB から得られる。そして、書物をめぐる発言にありがちな単語——「読む」、「買う」、「借りる」などの動詞や「小説」、「書店」、「連載」のような名詞——が書名文字列の近辺に出現することが大きな手がかりとなると考えた私は、単語頻度に基づく素性を設計し、そこそこの性能(精度0.8、再現率0.7程度)を出せる分類器を構築するにいたった[3]。
しかしこの分類器は残念なことに、次のような発言も書物への言及と誤判定してしまう——”落ちてた本を棚に返したら書店員さんに「ありがとう」って言われた”。その一因には、そもそも『ありがとう』という書名が実在することがある。私の分類器は書名文字列が含まれることが前提で、その文脈が書物をめぐるかどうかに焦点を当てていたので、書名文字列自身を素性から取り除いている。先ほどの例は”ありがとう”を除いた単語の列、しかも出現順序は考慮されない Bag-of-Words として解釈され、かなり書物に関連しているように見えてしまうのだ。
そこでやっと冒頭の疑問に立ち返ることになる。「書名らしい書名」であるかが判断できていれば、このようなミスは防げるのではないかと思った。もちろん、書名が節や文の形式をとる面白い本はたくさんあるが、『物理学論集』とか『死語辞典』などの明らかに書名らしい文字列をまるで手がかりにできていないのは、あまりにもったいない。そういうわけで、分類器構築にあたり使用していた「全書名リスト」の中身を分析したのである。
研究手法はいたってシンプルだ。形態素解析器 (MeCab) と係受け解析器 (CaboCha) を用いて、書名を品詞とその係受けのレベルに抽象化し、共通するパターンで数え直した。まず書名の9割近くは句の形式をとり、句の7割近くは名詞が占める。自由な形式の書名はそれほど多くはない。最も典型的なパターンは何なのか、名詞(句)に着目して集約しつつ、共通する一般名詞や助詞があれば適宜展開してみると、簡単のため具体的な頻度は挙げないが、上位3パターンは次のようになる。
- ○○(例:羅生門):○○集、○○入門、○○論
- ○○の○○(例:種の起源):○○の○○学、○○の研究、日本の○○
- ○○と○○(例:罪と罰):○○社会と○○、○○と○○社会
この結果は皆さんの想像とも合っただろうか。本研究は国内学会でポスター発表した単発の研究[4]であるが、個人的には品詞や係受けと親しむ機会となって、思い入れがある。その後、この素性をうまく使った分類器の性能向上……には至らなかった。深層学習が言語処理にも本格的に到来し、意味や文脈も含めたテキストの素性はモデルが自動的にコーパスから学習できるようになったためである。しかし、人間が解釈可能な言語学的知見として書名の形式の一端を明らかにするといった基礎的研究は、応用(結果としてのテキスト分類性能など)だけに関心を持つ深層学習手法では切り込むことができない。
さて、大規模言語モデル(LLM)に駆動された生成AIが人口に膾炙してはや2年近く経つ。今や「LLM」という単語が含まれない言語処理論文を見つける方が困難だ。この LLM、古典的な形態素解析や係受け解析の技術に依拠しない。入力テキストの分割(トークナイズ)はされるが、「単語」や「句」のような言語学的単位とは何ら関係なく、コーパスから統計的に導き出された単位(バイト列であることすらある)による。言語学的にいう品詞や係受けの概念は、コーパスを通じた学習によってひとりでに組まれていくので、外側から与える必要は無くなった。一足とびに応用結果(分類、抽出、翻訳、…)を得られる LLM を前に、かつて言語処理システムを構成していた形態素解析などのモジュールについて研究することは無価値である……そう考える研究者もいる。
デジタル人文学に携わられている研究者の皆さんには、ぜひこの状況を叱咤いただきたい。「現状の言語処理ツールではこの<文献>の解析にはちっとも役に立たない」という事例を言語処理研究者に見せつけてほしい。LLM はきちんと文字を数えることも難しい[5]。諦観に支配された言語処理研究者が、古典的な言語処理ツールへの興味を失ってしまう前に、声を上げていただくのが良いと思う。
実のところ、少ないながらも基礎的言語処理ツールの研究・開発は続いている[6][7]。LLM 性能を競う研究は大企業の独壇場となり、大学研究室のレベルではその競争にすら入り込めないことは、よく知られた状況である。また、LLM を作った・使っただけの研究への飽きが広がっていることも肌で感じる。近いうちに、基礎的な言語処理へと回帰する向きも増えてくるのではないかと個人的には思っている。2024年の言語処理学会年次大会では、デジタル人文学チュートリアルが開催され[8]、言語処理研究者の関心も引いた。人文学が求める精緻な分析を支援する言語処理学の発展を期待したい。
執筆者プロフィール
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第77回
「デジタルテキスト資料アーカイブ構築が可能にする古代エジプト『死者の書』の計量的研究」
古代エジプト文明における『死者の書』は、約1500年にわたり継承された宗教的・文化的遺産であり、古代エジプトの来世観や宗教思想を理解する上で欠かすことのできない文献である。新王国時代(紀元前1550年頃)からローマ時代(紀元後1世紀頃)まで、『死者の書』は多様な社会層に普及し、そのテキストはおよそ200程度の独立した呪文(Spruch)によって構成されている[1]。これらはパピルスを中心とした媒体に記され、時にミイラ包帯や棺、墓壁といった別素材にも展開する。また、テキストにはヴィネット(挿絵)が添えられ、ヒエログリフ(聖刻文字)、ヒエラティック(神官文字)、稀にデモティック(民衆文字)など時代や書記形態の変遷に応じた文字体系が用いられる。このような多層的な情報構造を有する死者の書は、古代エジプト人の死後世界観のみならず、社会学や言語学、文学や考古学など、幅広い研究領域に示唆を与えてきた。
従来、この膨大な資料群の研究は、主に文献学的手法によって行われてきた。だが、散在する写本、異なる時代・地域、変遷する文字体系、さらに多様なヴィネット様式という複雑性は、個別研究に終始しやすく、包括的な比較分析や大規模統計的手法の導入は困難を極めていた。しかし、20世紀末から21世紀初頭にかけてのデジタル技術の発展および国際的な学術協働の深化により、デジタル・ヒューマニティーズのアプローチが新たな可能性を切り開いた。その象徴的な成果として注目されるのが、ボン大学を拠点とする研究グループが20年以上にわたり推進してきた『死者の書』デジタル・アーカイブ化プロジェクト Das Altägyptische Totenbuch: ein Digitales Textzeugenarchiv(古代エジプトの死者の書:デジタルテキスト資料アーカイブ)である(図1)[2]。2004年以降、ノルトライン・ヴェストファーレン州学術芸術アカデミー(Nordrhein-Westfälische Akademie der Wissenschaften und der Künste)の支援を受け、散在していた資料を集約し、オンライン上で世界中の研究者が参照できる形態を整えることで、研究環境が一変した。
このデジタルアーカイブには、2993件の資料が収録されている。世界37を超える国・地域に所蔵された死者の書関連の文献を統合し、パピルスのみならず、リネン、棺、墓壁上に残された資料までを包括的にカバーする。このような統合的環境により、以前は特定機関に足を運ばなければ参照できなかった写本を、地理的・時間的制約なく比較検討できるようになったのである。さらに、このアーカイブには詳細なメタデータが付与されている。各テキストには、来歴、年代、出土地、文字体系、媒体、呪文配列パターン、ヴィネットの有無と様式など、多面的な属性情報が体系的に組み込まれ、研究者は任意の検索条件を用いて、観点を変えた資料比較を行うことが可能となった。
このメタデータを駆使した横断的検索・分析は、従来の文献学研究を大幅に強化する。異本間比較や伝承プロセスの追跡はもちろん、特定の呪文がある時代や地域で特異的に多用されたり、逆に別の時代・地域で衰退していくといった現象を可視化することができる。これにより、社会的・政治的変動、死生観の移り変わり、あるいは書記職集団の編成や書字教育制度の発展といった、テキスト背後に潜む文化的・歴史的要因をより精細に浮かび上がらせることが可能となる。
さらに、このアーカイブを通じて国際的な学術協働が飛躍的に促進されている。以前は、各国の博物館・大学所蔵の写本を研究するには、複数回の現地訪問や特別許可が必要であった。それに対し、オンラインアクセスの実現は、研究者同士が地理的境界を越えて同一資料を同時に検討することを可能にする。国際的ワークショップやオンライン・セミナーを通じて、異なる専門分野や理論的背景を持つ研究者が共同で新たな解釈・分析法を開発し、学際的・比較的視点が強化されている。こうしたネットワークの形成は、人文学研究をグローバルな協働型へと転換させる一助となっている。
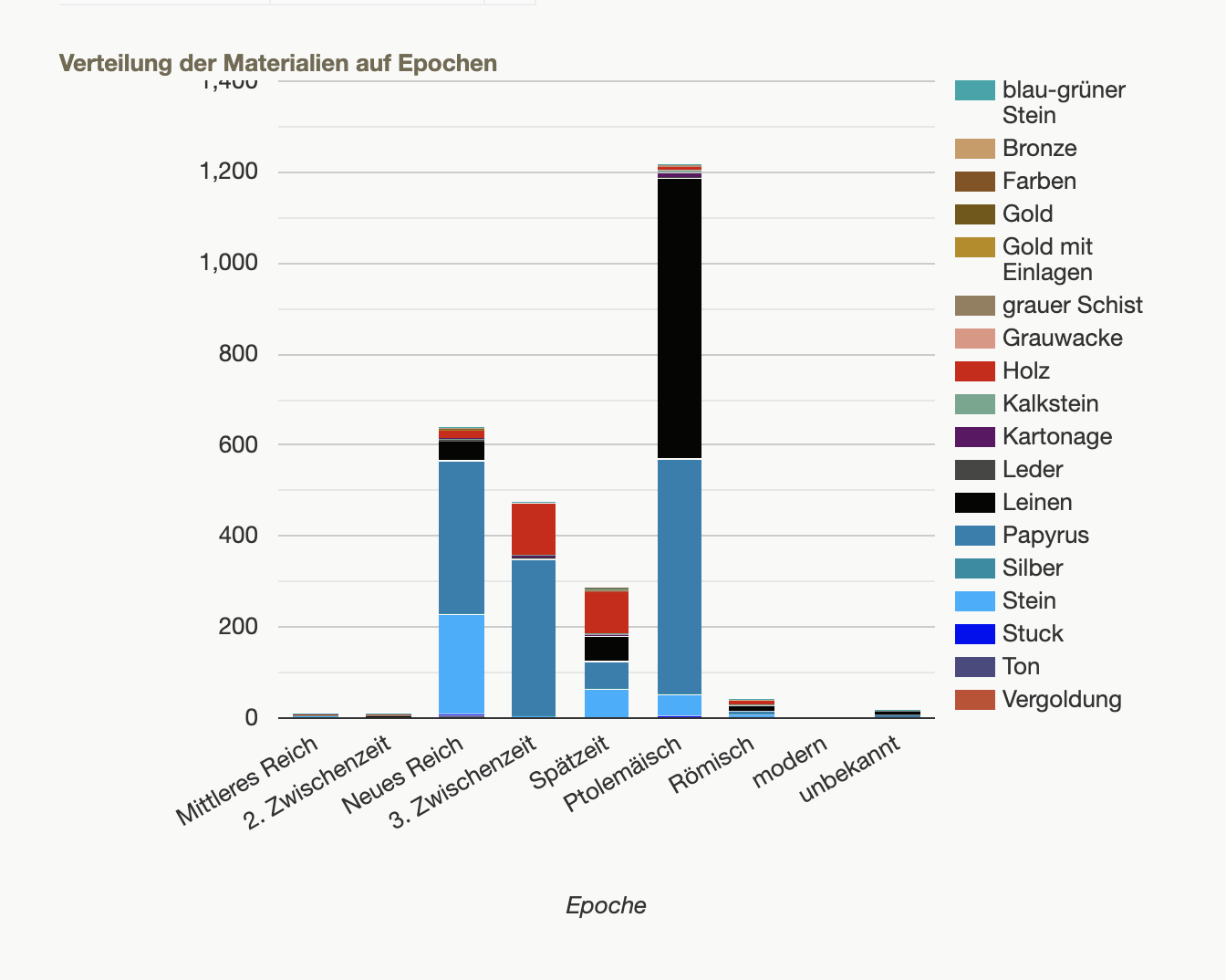
多数の様々な統計のグラフはインタラクティブな形式で、ポータル上で公開されている。また、ヴィネットに出現する神々、材質、色彩などの統計も取られており、これらのグラフをポータル上で閲覧することができる(図2)。
例えば、対象となるオブジェクトに用いられている文字体系は、主にヒエログリフとヒエラティックが多数を占め、一部にデモティック、ギリシア語、不明、無記載、文字そのものがないケースが存在する。全体的には、筆記体ヒエログリフおよびヒエラティックが特に多く観察される。本データベースによる文字体系別の分布(オブジェクト数)は以下の通りである[4]。
- ヒエログリフ(Hieroglyphisch): 1,270件(41.8%)
- ヒエラティック(Hieratisch): 1,265件(41.7%)
- 記載なし(keine Angaben): 474件
- 不明(nicht bekannt): 16件
- 文字なし(keine Schrift vorhanden): 6件
- デモティック(Demotisch): 4件
- ギリシア語(Griechisch): 1件
これらの結果は、ヒエログリフやヒエラティックがオブジェクト上で圧倒的多数を占め、他の文字体系や情報不明・記載なしの割合が相対的に小さいことを示している。
また、計算機科学との連携により、新たな分析手法が開拓されている。自然言語処理技術は、呪文中の語彙頻度や構文パターンを自動的かつ大規模に解析し、今まで見過ごされていた言語的特質や時代的推移を抽出することを可能にする。機械学習や深層学習手法のトレーニングデータとして本データベースのデータを用いて自動判別モデルを作成すれば、新たに発見される『死者の書』写本を自動で判別できたり、テキスト間の類似性や典型性、異質な構文構造を数値的に評価でき、従来は定性的な直観に頼っていた解釈を、より客観的な根拠をもって行うことができる。また、画像認識技術を用いたヴィネット分析は、様式的特徴の定量化や、図像要素の組み合わせパターンの発見などを促し、テキストと図像の統合的理解を深化させる。
このようなデジタルアーカイブは、19世紀にリヒャルト・レプシウス(Richard Lepsius)やエドゥアール・ナヴィーユ(Édouard Naville)らのエジプト学者によって確立された初期の学術基盤の上に築かれている。当時は限られた数の写本を用い、シノプティックな対比や校訂を行うことが精一杯であったが、21世紀のデジタル手法は、膨大な資料を一元管理し、多変量的・多次元的な分析を可能にしたのである。この進歩は、古代エジプト学における文献研究を、過去の学術的蓄積を継承しながら、新たなパラダイムへと飛躍させている。
結論として、「死者の書」デジタルアーカイブの構築は、デジタル・ヒューマニティーズが人文学研究へもたらす変革を具現化したモデルケースである。国際的な学術協働と先端的な計算機技術の導入により、これまで困難であった大規模・比較的・動態的分析が可能となり、古代エジプト研究は新しい知見と解釈に満ちた創造的な領域へと進化し続けている。これは文献学と情報科学の融合によって生み出される新しい人文学研究手法の方向性を示すものであり、今後さらなる発展が期待される。古代世界の資料をデジタル的に再構築し、多面的・多角的アプローチを取り入れることは、人類の過去に対する理解を深化させるのみならず、その知識を現代社会へと還元し、文化多様性や文明間対話の重要性を再確認する契機となるであろう。
- コメントを投稿するにはログインしてください