人文情報学月報第125号
ISSN 2189-1621 / 2011年8月27日創刊
目次
- 《巻頭言》「匡郭と人文情報学」
:天理大学附属天理図書館 - 《連載》「Digital Japanese Studies 寸見」第81回
「「渋沢栄一フォトグラフ」として、「『渋沢栄一伝記資料』別巻第10」と「みんなで古写真【渋沢栄一伝記資料】」が β 版公開」
:北海学園大学人文学部 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第42回
「複雑な文字の符号化:漢字、マヤ文字、古代エジプト・ヒエログリフ―京都大学デジタル人文学国際会議 KUDH2021「Digital Transformation in the Humanities」2日目 Session 2 開催報告―」
:京都大学大学院文学研究科附属文化遺産学・人文知連携センター - 人文情報学イベント関連カレンダー
- イベントレポート「じんもんこん2021に参加して」
:一般財団法人人文情報学研究所 - 編集後記
《巻頭言》「匡郭と人文情報学」
日本の江戸時代の出版物のほとんどは、版画のように木板(板木)[1]に文字を彫り付けて印刷する整版本です。
活版と比較した際の整版本の特徴として、数十年、数百年の長期に亘って同一の板木で印刷し続けられることが挙げられます。そのため、17世紀に印刷されたものと、明治時代に印刷されたものが同一の板木を使っている(同版である)ということがしばしば起こります。そのため、出版事項を示す刊記があって出版者・出版時期が異なることが明らかな本の間でも版の同異の判定が重要な事項となります。
逆に同時期にいわゆる海賊版が出ていることもあります。この海賊版は覆刻(おっかぶせ)という、元の書物を分解し、板木に貼り付けて彫る手法を用いることがあり、そうすると一見して同版に見えることがあります。特に江戸時代の早い時期には出版事項を十分に示さない書籍も多いため、同版か異版かを判断する必要も生じます。あるいは、蔵版者が板木の焼失や摩耗によって、一部や全部を新調することもあり、この場合は新刻・覆刻の両様があります。
この版の同異を判定する伝統的な手法として、版面の比較があります。同じ板木を使っていれば、字詰・行詰、書体や字画まで原則として一致します。違う板木を使っていればたとえ似せていたとしてもわずかな差が生じます。ただし、同版でも摺りの巧拙や経年劣化で版面の印象が変わったり、一部を彫りかえて内容が異なったりするなど注意すべき事項があり、板本書誌学においてはそれらを弁別する技能を訓練することが求められてきました。
その版の同定をする際に重要な情報を与えてくれるものに匡郭があります。匡郭は文字面の外側にある枠、印刷面を囲むように配置されている線のことです[2]。この匡郭はしばしば欠損します。これはたとえば板木の出し入れをするときに板木同士をぶつけることなどによって生ずるのでしょう。この欠損は新刻や覆刻の際などにはほとんど再現されないため、同一箇所に匡郭の欠損を有する場合は同版である蓋然性が高いといえます。共通の欠損が複数箇所に現れるようなら、なお蓋然性は高くなります。
また、刷りの先後を検討する際にもこの欠損の有無は用いられます。原則として同版においては欠損がない方が早い時期に刷られたものであるといえます。(稀に欠損を埋めているものがあることには注意が必要です。)
板本書誌学分野ではこの版面比較はおおむね比較対象(もしくは複写物)を並べて目視によって行われていた訳ですが、印刷製版の現場では校正に用いる「あおり検版(校正)」という技術が存在していました。これは修正前と修正後の原稿を重ね合わせてめくり/戻すことによって、残像を用いて変更箇所を確認する手法です。今ではデジタル検版に引き継がれ、電子的に差分を検出しています。
この電子的に差分を検出する手法は、すなわち整版本の版面比較に流用することが可能です。北本朝展氏が進めている「差読(Differential Reading)」[3]はこのような思想に基づくものといえるでしょう。従来の版面比較による分析の正統後継電子版といえそうです。何百、何千頁もある書物の全頁にわたって各頁を同定するのには今のところあまり向いておらず、従来手法同様、標本調査となるのだと思われます。
一方、稿者は板木の木材としての性質に着目しました。板木は彫製の際に版材の含水率の低下によって収縮します。板木や整版本から算出するに、縦方向の収縮率は平均2.8%であり、0%から5.6%の範囲で正規分布することがわかりました[4]。実際に袋綴の整版本を折り目側から観察すると、一般に地の匡郭を揃えて製本するため、天の匡郭が不揃いであることに気付かされます。これは活版だと天地ともにほとんど揃っていること[5]と対蹠的です。整版本の匡郭の縦寸のばらつきが木材の性質による現象である以上、人為的な再現は困難であり、またそこまでしてわざわざ再現する理由もありません。すなわち、同版であればこのばらつきが共通していると考えられるのです。
これが何を意味するかといえば、匡郭はつまり線分ですから、紙面中から線分を検出し、2線間の距離を測り、各頁のばらつきかたを比較することで、複数の版において版の異同を検討することができるということです。一部だけが差し替えられているものも検出可能です。また、この距離は単純な数値ですから、計算コストも極めて低く抑えられます。ピクセルをメートル法に変換することで電子化されていない書物の実測値との比較も可能です。そこでまずは電子画像から線分の検出と2線間距離の計測を半自動で行うプログラム「RulerJB」を試作(外注)し、紹介・公開しています[6]。実際の運用についてはそちらをご覧いただければと存じます。
精密な分析に向く版面比較と、当りを付けるのに便利な本手法とは相補的な関係にあります。書誌学はありとあらゆる側面からの分析によって書物から情報を抽出し統合する学問であり、妥当なものである限り、使える手法は多いに越したことはありません。研究の素案が2011年、プログラムの試作が2014年、時機を窺っていた論文の発表が2019年、プログラムの公開が2020年ですから、いろいろ併行していたとはいえ、結構長いお付き合いになりました。専門の皆様からみるとまだまだ改良の余地の多いものだと思いますので、ご指摘をいただけますと幸いです。共同研究のお申し出をいただけましたら、飛び上がって喜びます。
稿者は国文学者であり、自分でコードを書く能力にも乏しく、人文情報学に携わっているとは口が裂けてもいえません。しかし、幸いに機械に忌避感なく、機械処理ができそうなことと難しそうなことをなんとなく察することくらいは若干ながらできるようになってきつつあります。国文学者と情報学者に限らず、他分野の研究者が協同する際には、通訳が必要なのだろうと思います。それもできれば、各分野よりの通訳が2名いる方が良いでしょう。あたかも国家元首間の重要会談のように。そういう意味でもこれから国文学と情報学とに貢献できればと思う次第です。
執筆者プロフィール
《連載》「Digital Japanese Studies 寸見」第81回
「「渋沢栄一フォトグラフ」として、「『渋沢栄一伝記資料』別巻第10」と「みんなで古写真【渋沢栄一伝記資料】」が β 版公開」
2021年12月11日、渋沢栄一記念財団(以下、同財団)から、「渋沢栄一フォトグラフ」β 版(以下「フォトグラフ」)が公開された[1][2]。これは、明治から昭和初期にかけての官僚・実業家・社会活動家など多面的な活動をした人物である渋沢栄一の資料写真について整理をする試みで、1971年に同財団の前身・渋沢青淵記念財団竜門社から刊行された『渋沢栄一伝記資料』の別巻第10を公開するもの[3](以下、断らないかぎり書籍体全体を指して『同伝記資料』、ウェブサイトを指して「別巻第10」と称する)と、同資料に収録された写真にたいして、市民参加の形態でアノテーションを附与する「みんなで古写真【渋沢栄一伝記資料】」[4](以下「みんなで古写真」)からなる。「フォトグラフ」は、同財団情報センター(以下、同センター)の参画した、令和3(2021)年度の国立歴史民俗博物館総合資料学奨励研究による成果のひとつであるという。
「別巻第10」は、渋沢栄一の生涯にまつわる写真を3期4テーマからまとめたものである。「フォトグラフ」は、そこに掲載される700点ほどになるという写真へアノテーションをするプラットフォームとなる[5]。「別巻第10」はほぼ画像とテキストが提供されるのみなので、ここでは「フォトグラフ」について主に扱う。
同センターは、国立歴史民俗博物館(以下、歴博)からこれまでも2020年度に共同研究を行い、「渋沢栄一ダイアリー」を公開している[6]。こちらは、同じく『渋沢栄一伝記資料』の別巻第1、第2の渋沢栄一の日記資料を符号化したものである。『伝記資料』本編もまた同センターがデジタル化を行っているが[7]、資料の性格の異なる別巻は研究を進めながら資料の取り扱いを模索しているというものらしい。デジタル化本編も無料公開であるが、別巻はさらにオープンアクセスが許されている。「渋沢栄一ダイアリー」では、符号化された情報をもとに、日時や人名・地名などの情報を抽出するだけでなく、人物相関図も描き出せるようにされている。また、符号化オリジナルデータも提供されており、オープンアクセスと相俟って利活用が容易となっている。
今回の共同研究では、歴博の橋本雄太氏らを交え、写真資料をどのように市民参加型で写真のアノテーションを行うかの研究を行ったものである。橋本氏は、市民参加型翻刻プラットフォーム「みんなで翻刻」[8]でよく知られる人文情報学の研究者であるが、このプロジェクトでもプラットフォーム等の技術開発に当たっているものと思われる。解説動画も氏によるものがすでに公開されている[9]。そのほかにも同センター以外の参加者の名も示され、橋本氏のみならず多方面からの協力が得られていることが分かる。
「みんなで翻刻」と異なり、媒体が写真であること、デジタル化も済んで行われるべきこともアノテーションが中心であるため、見た目や参加方法は「みんなの翻刻」と類似するが、作業には大きな差がある。たとえば、「みんなで翻刻」、とくに IIIF 対応後のものは、さまざまな資料提供サイトのデータを IIIF を通して呼び出し、そこに書いてある文字をデータ化することが目的となる(マークアップも多少はできるとしても)。それにたいして、「みんなで古写真」は、写真内の人物・位置・文字の情報を与えるほか、参考情報や現在の姿など外的情報についても附与できることになっていて、すこしシステムとしても高度である。人物の同定には、同財団で準備した人物データベースにすでに登録されている必要がある。ただし、漏れがないならば市民参加の必要もないわけで、表記揺れも含めてか、登録したい人物がデータベースにない場合は、登録希望をすることになる。
β 版公開の日に「じんもんこん2021」という人文情報学のシンポジウムの場で行われた、橋本氏が代表の、この共同研究の参加者の連名による研究発表では[10]、協調学習というステップが市民参加型プロジェクトには有効な解を与えるとされている。協調学習とは、学習者がともに伝達しあうことで学習が高まるという教育実践の在り方であるとされる。これは、「みんなで翻刻」からの解なのだろうが[11]、「みんなで翻刻」と比べると、扱うデータが簡単すぎるか難しすぎるかのどちらかで、もう一歩工夫が必要かもしれない。その点、現在地の写真や参考情報の附加は、うまくいけば参加しやすくなると思われるので、使いやすさを定期的に見直して、関心を持った層を逃がさないなどの工夫が求められていくのだろう。
同研究発表[10]にあるように、このシステムは、「別巻第10」にしぼったものではなく、汎用性があるため、今後は一般的なプラットフォームへの拡大を目指したいという。あまりシステムの操作感などには触れられなかったが、多機能でかつシンプルなシステムであり、今後が楽しみである。
ところで、古写真には学術的に明確な定義はされていないようである。戦前までとするものを見るが、なにか便宜の感が強い。古典籍と言われるものの領域も、幕末までとされてきたのが明治まで侵食してきたように感じる。コンピュータ以前を古とする時代もあれよあれよと来てしまいそうだ。今の幅が着実に狭まっている。
渋沢栄一記念財団情報資源センター、「渋沢栄一ダイアリー」の公開を発表|カレントアウェアネス・ポータル https://current.ndl.go.jp/node/43881。
「渋沢栄一ダイアリー」公開。渋沢栄一の日常を覗いてみよう! - 情報資源センター・ブログ https://tobira.hatenadiary.jp/entry/20210423/1619161341。
本連載でも第22回・第53回で取り上げている。
[付記]
E2456 - 『渋沢栄一伝記資料』とデジタル化の現在|カレントアウェアネス・ポータル https://current.ndl.go.jp/e2456。
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第42回
「複雑な文字の符号化:漢字、マヤ文字、古代エジプト・ヒエログリフ―京都大学デジタル人文学国際会議 KUDH2021「Digital Transformation in the Humanities」2日目 Session 2 開催報告―」
先月に引き続いて、京都大学デジタル人文学国際会議 KUDH2021「Digital Transformation in the Humanities」の報告を今回も行う。先月は1日目の10月2日に行われた、京都大学の安岡孝一氏と米国・ジョージタウン大学のアミール・ゼルデス(Amir Zeldes)氏の Universal Dependencies を主眼とする発表があった Session 1について報告した。今回は2日目(10月16日)の前半部である Session 2の報告である。
Session 2のテーマは、「複雑な文字の符号化:漢字、マヤ文字、エジプト・ヒエログリフ」である。京都大学からは、人文科学研究所附属東アジア人文情報学研究センターの守岡知彦氏が登壇した。海外からは、ドイツのボン大学のカルロス・パラン・ガヨル(Carlos Pallán Gayol)氏と、英国のセント・アンドリューズ大学のマーク=ヤン・ネーデルホフ(Mark-Jan Nederhof)氏が登壇した。発表自体は、大会公式ホームページ[1]および京都大学大学院文学研究科・文学部人文知連携拠点成果公開 WEB[2]で録画を見ることができる。
最初の守岡氏の発表は、漢字の符号化についてである。氏は、歴史上現われたどんな漢字にも対応できる符号化方式である CHISE(CHaracter Information Service Environment)を開発している[3]。Unicodeにも多くの漢字が登録されているが、歴史上すべての漢字を表現できるわけではない。Unicodeでは、一字一字が符号化されていく方式であるが、CHISE では、部首などの文字のパーツ、すなわち、文字素毎に符号化され、文字素の符号と、文字素の一字内の位置情報・レイアウト情報を表す符号とを組み合わせて、それぞれの文字が、IDS(Ideographic Description Sequence)、すなわち、漢字構成記述文字列として記述される。例えば、「𩠓」という漢字は、「⿰首乞」と文字素毎に記述でき、さらに「<⿰・⿺>首<⿱・⿸><⿰・⿺>丿一乙」(ID: bafyreiafy5l6h3w4zfq4yumcw5l4skd6umz2yf6xgzvatvvstyllyk3dne)と精密に記述できる[4]。ここで⿰⿺⿱⿸は文字素のレイアウトの符号である。CHISE のシステムはオープンソースであり汎用文字コードにかかわらない文字処理環境構築を目指している。具体的には、CHISE IDS 漢字検索で指定した漢字の文字素を含む漢字の IDS を検索し、その文字素を含む漢字の一覧とそれらの IDS を表示できる[5]。CHISE プロジェクトは、GitLab で成果を公開しているほか、SPARQL エンドポイントで RDF による文字データを取得することができる[6]。CHISE は特にその IDS が、歴史的な漢文を扱う様々な DH プロジェクトで用いられている。
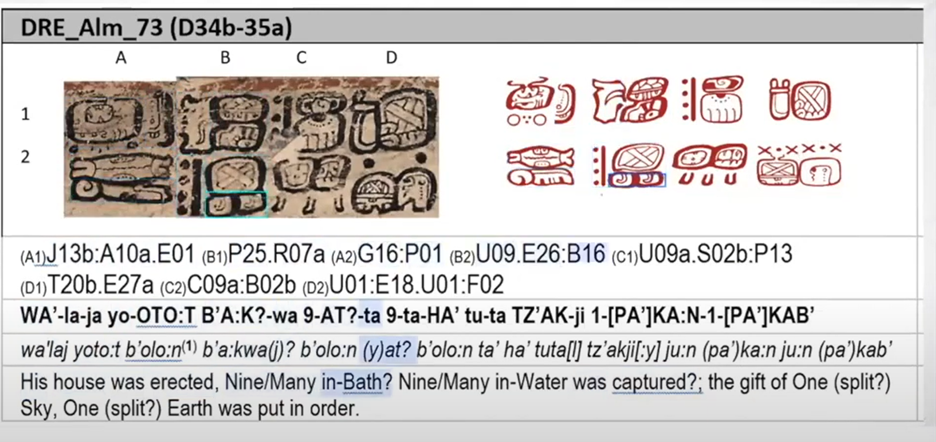
次のパラン・ガヨル氏の発表は、マヤ文字の符号化である。マヤ文字とは、マヤ聖刻文字、あるいはマヤ・ヒエログリフ(Mayan Hieroglyphs)とも呼ばれる。メキシコ・ユカタン半島を中心としたマヤ文明で紀元前3世紀頃から紀元後16世紀にかけて用いられた文字で、ソビエト連邦のユーリ・クノロゾフ(Yuri Knorozov)の研究以来、その解読が進んできている。この文字体系も、漢字と同じく、部首のように意味を持つ限定符、音を表す文字素、表語的な文字素などから構成されているが、文字素の配置が非常に自由な点で、大変複雑な文字体系である。この文字も、漢字と同じように方形(quadrat)が単位となる。メインの方形の文字素に様々な音節を表す文字素や意味を表す文字素、語を表す文字素、もしくは、同じ音節を繰り返す文字素をはめ込んだり、付け足したり、メインの方形の文字素の一部と組み替えたりして、1単語を表す(例:図1)。ちなみに、マヤ文字の音を表す文字素は子音1つと母音1つの組み合わせである音節文字素であり、子音で終わる閉音節は、その末子音と直前の母音を表す音節文字素が付与される。例えば、balam「ジャガー」という語は、<ba> と <la> と <ma> の音節文字素を組み合わせて表される(なお、<>は1文字素を表す他、音の表記は簡略化されている。また、表語文字素や限定符を使う別の書き方もある)。未だ Unicode にはマヤ文字は含まれていないが、マヤ文字の符号化プロジェクトの進展とともに、マヤ文字を Unicode 化する試みがなされてきている[7]。このマヤ文字符号化プロジェクトは、カリフォルニア大学バークレー校のデボラ・アンダーソン(Deborah Anderson)氏が監督しており、パラン・ガヨル氏はこのプロジェクトの主要メンバーである[8]。パラン・ガヨル氏らのマヤ文字符号化でも、文字のパーツ毎に符号化され、さらに、方形内の位置を表す符号を組み合わせる。とりわけ、方形内のレイアウト・位置の符号化は、2017年のモデルでは164個あったが、2018年のモデルでは142個に集約された。
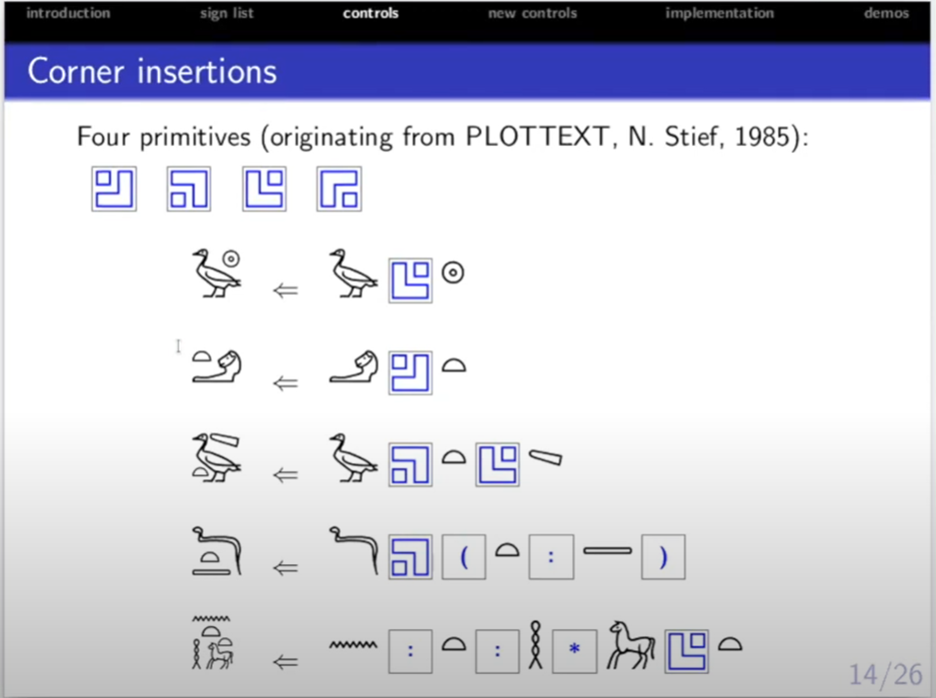
最後の発表は、ネーデルホフ氏の古代エジプトのヒエログリフの符号化の研究である。ヒエログリフは、音を表す文字である表音文字、語を表す文字である表語文字、語のカテゴリーを表す限定符を組み合わせて通常複数の音節がある単語を表す。ネーデルホフ氏は、ヒエログリフの Unicode 化を進めてきた。2009年には、ガーディナーの中エジプト語文法[9]に記載されている1071文字が追加されたが、これらは基本的な文字でしかない。さらに、ヒエログリフは、様々な大きさの文字を正方形の枠の中に敷き詰めるように書いていくが、Unicode では、この文字の配置には対応できていない。そこで、ネーデルホフ氏やセルジュ・ロスモルデュック(Serge Rosmorduc)氏らによって、Unicode Consortium において、この正方形の枠の中に様々な形の文字を詰めて書いていくための制御文字(例:図2)が提案され、Unicode に追加された[10]。現在、フォントや入力方法で、この制御文字に対応できているものは開発中である。ネーデルホフ氏はそうしたシステムをこの発表で提示した。開発中の氏のシステムは GitHub から入手可能である[11]。
本セッションでは、漢字・マヤ文字・ヒエログリフを符号化する際の共通点と相違点も明確になった。共通点としては、どちらも正方形の枠の中に文字あるいは文字素を埋め込んでいくため、文字素の符号化だけでなく、方形の枠内で文字あるいは文字素を配置する位置(レイアウト)を示す符号あるいは制御文字が必要であることである。相違点としては、漢字が1語=1音節=1文字であり、1文字のなかに、意符や音符などの文字素が入りうるのに対して、ヒエログリフは、1語=1音節以上=1文字以上で、方形に文字を納めるのは、レイアウトの観点のみからなされ、表音文字や限定符が文字として独立している。これらに対して、マヤ文字は、基本、1文字=1音節以上=1語で、方形の枠のなかに、複数の音節文字素や限定符などが入る。漢字に関しては、文字素の配置の符号化は、CHISE においてかなり整備されているのに対し、エジプト・ヒエログリフでは、何種類の位置情報が必要か近年議論が決着しつつあり、最も文字素の配置が複雑なマヤ文字では、パラン・ガヨル氏らのプロジェクトによって年々整備されていっているということが感じられた。
次回は、2日目の後半部であり、デジタル・アーカイブとキュレーションに関する Session 3と3日目の Universal Dependencies に関する Session 1b について報告する予定である。
人文情報学イベント関連カレンダー
【2022年1月】
-
2022-1-10 (Mon)
令和3年度東日本大震災アーカイブシンポジウム―震災記録を残す、伝える、活かす―於・東北大学災害科学国際研究所多目的ホール -
2022-1-22 (Sat)
日本学術会議 公開シンポジウム「総合知創出に向けた人文・社会科学のデジタル研究基盤構築の現在」於・オンライン -
2022-1-29 (Sat)
言語学フェス2022於・オンライン
【2022年2月】
-
2022-2-9 (Wed)
国立国会図書館 フォーラム「デジタル化及びデジタルアーカイブ構築の現状と未来」於・オンラインhttps://www.ndl.go.jp/jp/event/events/20220209digi_info.html
Digital Humanities Events カレンダー共同編集人
イベントレポート「じんもんこん2021に参加して」
2021年12月11日(土)~12日(日)に開催されたじんもんこん2021 人文科学とコンピュータシンポジウムに参加したので、ごく主観的な感想めいたものではあるが、筆者の参加記としてお届けしたい。
じんもんこんシンポジウムは、デジタル・ヒューマニティーズに関する日本語で開催される最大のシンポジウムと言うこともできるものであり、1999年から毎年開催されている、情報処理学会人文科学とコンピュータ研究会による査読付きシンポジウムである。すでに鬼籍に入られた方もおられるが、やがてはこれを査読付き論文誌に展開し、分野としての発展を目指そうとする取り組みの一環として当時の気鋭の研究者達によって開始され、その後継続して今に至るというものである。この流れは、公式には現在は隔年で発行されている情報処理学会論文誌の人文科学とコンピュータ特集号へと結実し、その一方で、その意思は日本デジタル・ヒューマニティーズ学会(JADH)の設立と日本語・英語論文誌の刊行にも継承され、現在に至っている。JADH の日本語論文誌が情報処理学会論文誌の当該特集号の間を縫って隔年刊行されているのは、これが一連の流れであることを端的に示していると言えるだろう。
じんもんこんシンポジウムは、発表申し込みとして提出された A4で2枚までの概要論文に対してプログラム委員会が主導する査読が行われ、その評価に基づいて採択が決定される。採択後、フルペーパーの論文を書いて論文集に掲載し、シンポジウム当日にはそれに基づいて口頭発表やポスター・デモ発表を行うことになる。概要論文とはいえ査読を経ているため、内容的な興味深くかつ意義のある発表が揃っている。
今回のシンポジウムは、オンライン開催ということで、Zoom による口頭発表と、oVice というコミュニケーションツールを用いたポスター発表・デモ発表が行われた。事前に実行委員会を中心とした利用者講習会も提供され、いずれのツールにも特に混乱することなく発表が行われたようであった。とりわけ、oVice によるポスター・デモ発表は、比較的広いスペースに各発表がうまく配置され、個別に発表者のところに聞きにいって質問をしたり、他の人の質問を聞きながら自分も質問に参加でき、さらに、掲示されたポスターに変わる Google スライドを各自が自由に閲覧した上で発表者に質問することもできるなど、対面開催でのポスター・デモ発表のよさをかなり再現したものになっていたように思う。
発表内容の方は、いつものように、興味深い発表が目白押しだったが、中でも、人文学オープンデータ共同利用センターからの発表群が、これまでの成果を集大成したようなものが多く、聞いているだけで大変勉強になるようなものがいくつもあった。江戸時代の江戸の地図を現代の地図と効果的に結びつける手法や、シルクロードにおける1世紀前の調査と現在の状況をリンクさせる手法とその意義、版面が似た木版整版画像の差分を比較する手法、くずし字 OCR など、いずれも今後の人文学の基礎になっていくような発表であったように思う。また、テキスト資料を構造化して共有するための国際標準のガイドラインである TEI(Text Encoding Initiative)に関わる発表も目立っており、特に東洋学や日本研究に関するものがいくつも見られたことは、今後の日本の人文学の研究データがよりよいものになっていく兆しであるように思われた。他にも、クラウドシーシングに関わる発表もあり、渋沢栄一資料やフランス百科全書のデータを構築するなど、それぞれに工夫が凝らされたものであった。また、源氏物語の写本の関係を字母から考えてみるという長く続けられてきた研究が、今回もポスター発表で行われ、じっくりとお話をおうかがいでき、これも個人的にはとても勉強になった。
また、個人的に興味深かったのは、ナノ3D プリンタを使った3次元デジタルデータの長期保存技術に関する発表であった。確立した技術としての発表ではなかったものの、ナノ3D プリンタで出力したものは、観測した際に観測対象が変形してしまうことがある、という話や、一方で、色を構造体として出力することができるので退色しないようにすることもできる、という話など、ナノ3D プリンタをよく知る人にとっては常識的なことだったかもしれないが、筆者はそういう機会がこれまでなかったため、良い機会に恵まれたと感じている。このように、自分の情報のアンテナだけではなかなか引っかかってこない情報を得ることができるのも、このシンポジウムの良いことの一つである。
一方、併設イベントとして、関西大学アジア・オープン・リサーチセンター(KU-ORCAS)による国際シンポジウム「東アジア DH 研究の推進とそのための環境の構築―次世代の東アジア文化交渉学のために―」も夜間に開催され、そちらにもおうかがいして、東アジア DH 研究の現状にも触れることができ、充実した二日間を過ごすことができた。ただ、一つ、このシンポジウムを拝聴して感じた課題として、イギリスの大学を退職して中国の大学に赴任している教授が東アジアの DH 研究の現状をまとめて紹介してくださった際、日本デジタル・ヒューマニティーズ学会(JADH)の活動には言及があったものの、情報処理学会人文科学とコンピュータ研究会(SIG-CH)やじんもんこんシンポジウムへの言及がなく、結果的に、日本の DH はまだかなり低調であるという話がなされてしまっていた。筆者としては、SIG-CH を含む日本でのそういった一連の DH の流れを英語の論文として発表してきたり、折に触れ世界各地で報告したりしてきており、また、その英語の論文のうちの特に長いものは中国語にも翻訳されて流通しているらしいことも聞いているものの、まだまだ努力と工夫が足りないということを痛感させられたことであった。国際的に活動が見えるようになっているかどうかということは、日本の研究者の活動の成果がどれくらい影響力を持てるかということとも関わってくる場合があり、今後も、みなさまとともに、精進を重ねていかねばと思ったところであった。
ということで、雑ぱくなご紹介となってしまったが、じんもんこん2021は、まさに盛況のうちに幕を閉じた。みなさまにおかれても、都合があうときがあれば、色々な情報やヒントを得る機会として、ぜひご参加いただければと思っている。
◆編集後記
2021年もいよいよ終わりを告げようとしていますが、みなさまにとってはどんな一年だったでしょうか?本メールマガジンはおかげさまで毎月刊行できましたが、個人的には研究のある部分がほとんど進展しなくなり、対面の重要性も痛感しているところです。
新年早々、イベントカレンダーにも掲載されていますが、日本学術会議の心理学・教育学委員会、言語・文学委員会、哲学委員会、社会学委員会、史学委員会、地域研究委員会、情報学委員会が合同で設置している、デジタル時代における新しい人文・社会科学に関する分科会による公開シンポジウム「「総合知創出に向けた人文・社会科学のデジタル研究基盤構築の現在」が1月22日に開催されます。本メールマガジンが追及してきたテーマともかなり重なるものですので、土曜の午後になってしまいますが、もしお時間がございましたらぜひご参加ください。
(永崎研宣)
- コメントを投稿するにはログインしてください