人文情報学月報第166号
ISSN 2189-1621 / 2011年08月27日創刊
目次
- 《巻頭言》「AI 対話システムから、テクスト読解・解釈のための知識プラットフォームへ:統合データモデルとしての Humanitext Schema の設計」
:東京大学次世代人文学開発センター - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第82回
「エジプト・古代都市テーベのネクロポリスの総合デジタル・アーカイブ構築:テーベ・マッピング・プロジェクト(TMP)」
:筑波大学人文社会系 - 《連載》「英米文学と DH」第5回
「書籍データのリストの作成方法」
:中央大学国際情報学部 - 人文情報学イベント関連カレンダー
- 編集後記
《巻頭言》「AI 対話システムから、テクスト読解・解釈のための知識プラットフォームへ:統合データモデルとしての Humanitext Schema の設計」
2025年は日本のデジタル・ヒューマニティーズの発展における画期となるかもしれない。というのも、人間文化研究機構、慶應義塾大学、情報・システム研究機構が連携して取り組む DH コンソーシアム(DiHuCo)を皮切りに、東京大学史料編纂所や国立歴史民俗博物館が中心となる大型科研プロジェクトが開始されるからである。
こうした国内の動向を踏まえつつ、ここでは、筆者が関わっている Humanitext プロジェクトにおける最新のデータ構築・整備の試みについて紹介する。Humanitext は西洋古典を対象とするプロジェクトであり、上述の諸プロジェクトが扱う日本の資料とは文脈が異なるが、方法論や課題の共有という意味において多少なりとも役立つことを期待したい。
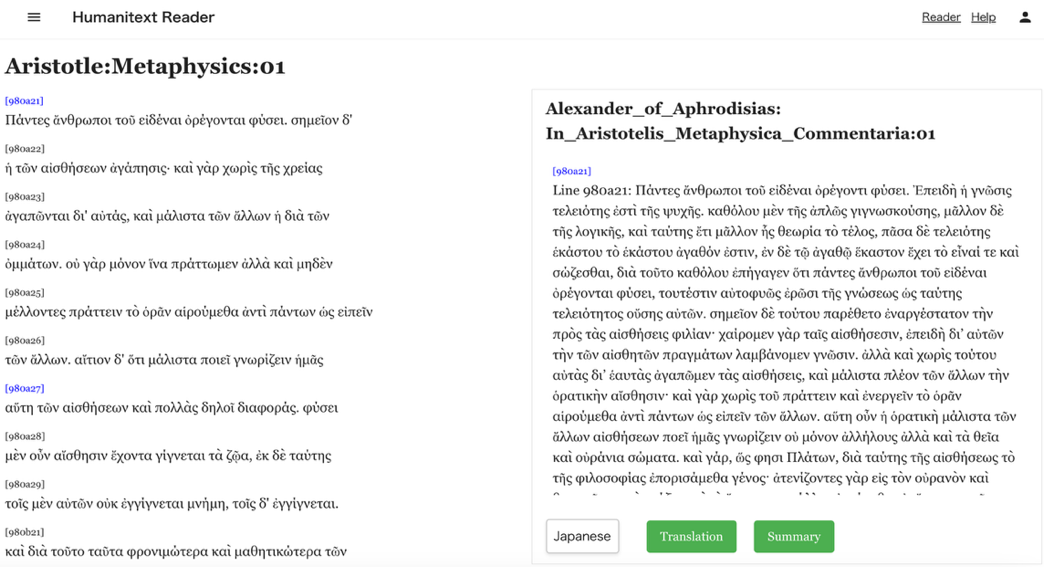
Humanitext は、AI の活用を通した新たな人文学研究のあり方を確立することを目的とするプロジェクトで、現在は、RAG(Retrieval Augmented Generation)に基づく学術的に信頼性の高い西洋古典対話システムである Humanitext Antiqua(HA)を開発・公開している。HA は、ユーザの質問に対して専ら一次文献に基づく回答を生成するシステムであるが、現在、プロジェクトではより高度なテクスト理解を可能にすることを目指し、二次研究文献や、古注と呼ばれる主に古代・中世の注釈者による注釈テクストとの接続に取り組んでいる。とくに古注については、古注と原典と並行参照できるシステムである Humanitext Reader(HR)を開発し、試験的にアリストテレス『形而上学 Metaphysics』の一部を公開(https://humanitext-reader.vercel.app/)している。
この HR を開発するにあたって我々は、原典における特定のテクスト箇所とそれに対応する古注、さらには HA の RAG で用いるベクトルデータを接続するための統合データモデルとして Humanitext Schema(HS)を設計し、これに基づいて RDF データを整備した。HS の基本構造は以下のようになっている。
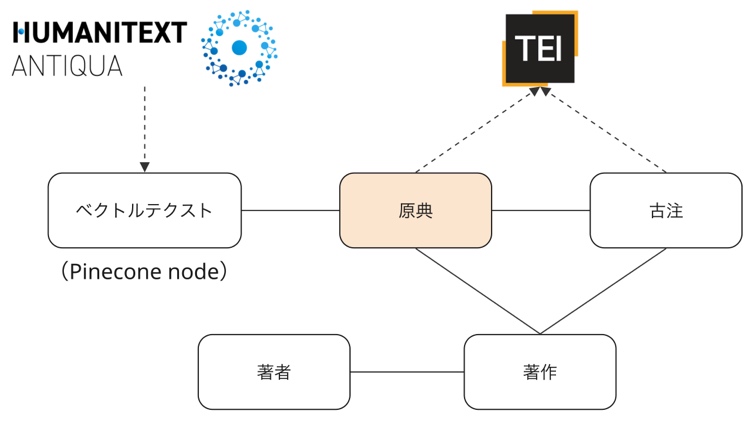
モデルの中心は、原典テクストにおける特定の箇所を表す「原典」であり、これは西洋古典分野におけるテクスト区分法に可能な限り沿ってリソース化される。原典・古注はそれぞれ、それが含まれる「著作」を参照し、この「著作」に対して、著者や時代、ジャンルといったメタデータが Dublin Core など既存のスキーマも再利用しながら記述される。これにより、HA や HR での検索や絞り込みが可能になる。また、Humanitext はプロジェクトの性質上、大量のテクストデータを扱う必要があるが、RDF リソースそのものに長大なテクストを持たせることは、データ量はもちろん、順序の表現がやや煩雑な RDF の規格に照らして適切ではない。そこで HS では、テクストそのものは TEI で(試験的に)構造化したうえで、対応箇所を DTS(Distributed Text Services)という API を用いて取得し、インターフェイスに表示するという方法を採った。
このように Humanitext では現在、従来の対話システムの枠を超えた西洋古典に関する総合的な知識ベースの構築に向けて、Linked Data を用いた基盤整備を進めている。現状では HA や HR で活用するための最低限のデータ整備にとどまっているが、引き続き、二次研究文献やコメンタリー、さらには写本画像等、テクスト読解に関わる多様なデータ資源の整備を進めるとともに、その AI 利用についても HA を軸として模索することで、デジタル空間における西洋古典テクストの多角的な読解と解釈に向けた試みを加速させていきたい。
執筆者プロフィール
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第82回
「エジプト・古代都市テーベのネクロポリスの総合デジタル・アーカイブ構築:テーベ・マッピング・プロジェクト(TMP)」
テーベ・マッピング・プロジェクト(Theban Mapping Project: TMP)[1]は、古代エジプトの都市テーベ(現ルクソール)における文化遺産を包括的に記録し保全するために1978年に開始された長期プロジェクトである。当時、エジプト学者ケント・R・ウィークス(Kent R. Weeks)の指揮のもと、テーベのネクロポリス(歴代の王族や貴族の墓地群)に存在するすべての墓や神殿を写真撮影し測量・地図化するという極めて野心的な目標が掲げられた。数千年にわたり盗掘や損壊が繰り返され、さらに近年では大気汚染や地下水位の上昇、都市開発や大量の観光客による影響で劣化が進むテーベの遺跡群を守るには、まず詳細な記録と地図を作成し、遺跡の現状を把握することが不可欠だと認識されたのである。
プロジェクト初期には、広大な遺跡全体を効率的に測量するための技術が模索された。TMP は当時最新の測量機器と写真測量手法を駆使し、必要に応じて熱気球を利用した空中撮影も導入した。この方法は遺跡の広域分布を把握するための低コストな測量手段として試みられたもので、後に遺跡調査や観光にも活用されるようになった。こうした工夫により、地上からだけでは難しい俯瞰的な地図作成が可能となり、遺跡の相対的位置関係や全体像を明らかにしていった。もっとも、テーベ全域の膨大な遺構を網羅的に記録する作業は当初想定された数年では完了せず、その後も長期にわたる地道な調査が続けられることになった。
1990年代半ばまでに、TMP は「王家の谷」(図1)と呼ばれる、新王国時代(紀元前1550年頃から紀元前1069年頃)のファラオ(古代エジプトの王)たちの墓が集中するルクソール西岸の谷を中心とした詳細な測量と記録を完了し、約20年を経てその成果をまとめた『王家の谷地図帳(Atlas of the Valley of the Kings)』が刊行された。この間、TMP における最大の成果の一つとして1995年の KV5の再発見が挙げられる。KV5は取るに足らない小墓として当初は見過ごされていたが、TMP の調査によりラムセス2世の50人以上の王子たちが葬られた巨大墓であることが判明し、その広大な構造が明らかになったのである[2]。TMP はその後も KV5の発掘と記録を継続するとともに、王家の谷を含むテーベ西岸全体の墓所・神殿のデータ収集に努め、多くの学術論文や報告書を通じて成果を発信してきた。プロジェクトはカイロ・アメリカン大学(AUC)での拠点活動を経て、現在では米国エジプト調査センター(American Research Center in Egypt, ARCE)[3]の協力のもとで運営が続けられており、蓄積された資料はオンライン上で広く共有されている 。
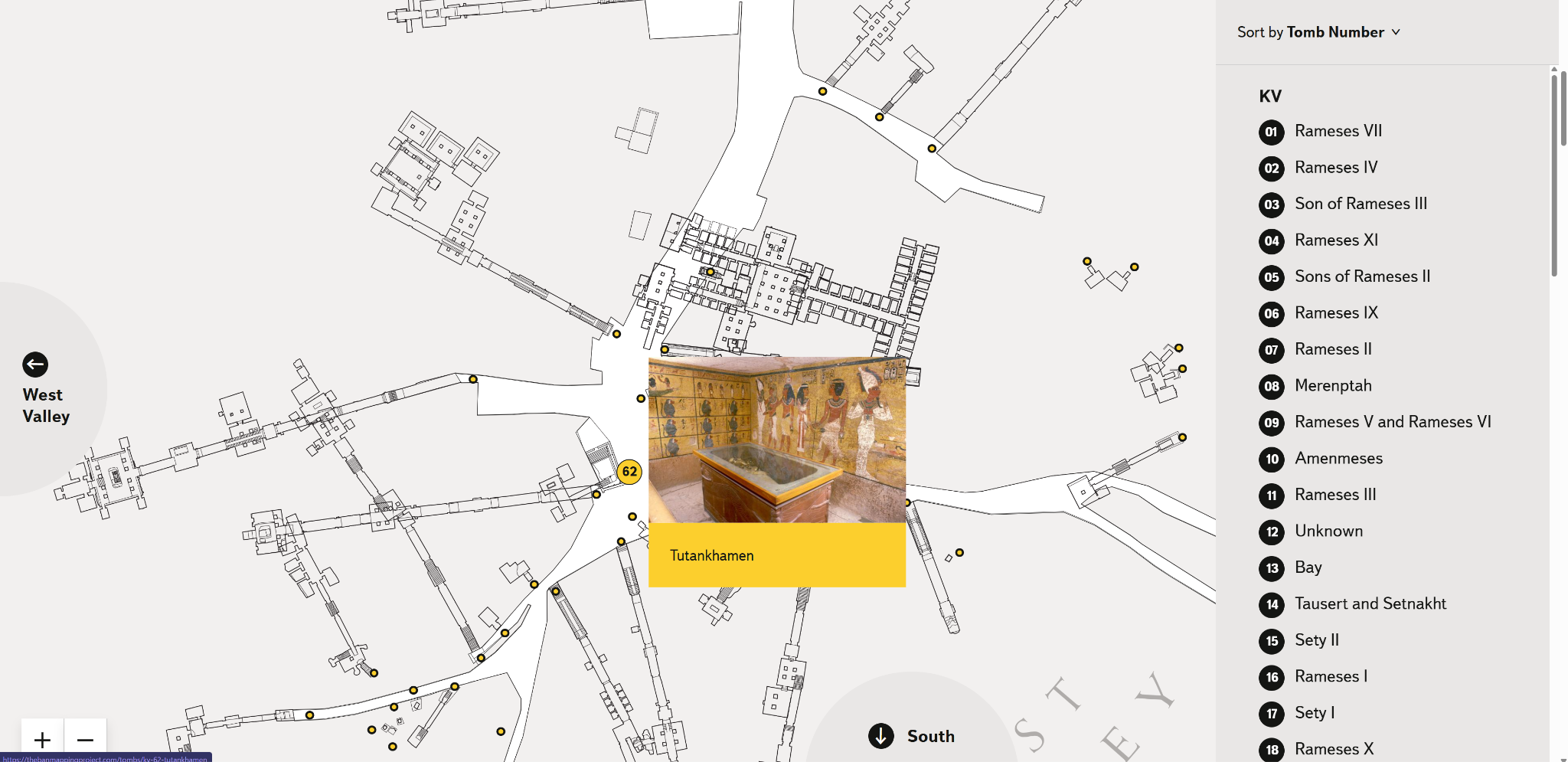
TMP はインターネットを通じて成果を公開することにも早くから取り組んだ。プロジェクトのウェブサイトには各遺跡の位置を示す地図や詳細な平面図、内部の写真ギャラリー、古代から現代に至る発掘史や研究史の解説、関連文献のデータベースなどが整備されている。誰でもアクセスできるこのサイトは、研究者にとって貴重なデータリポジトリであると同時に、教育者や学生、一般の愛好家にとっても学習リソースとなっている。TMP のサイトは長年にわたりエジプト考古学の基本資料として広く参照されてきたが、運営資金の不足などからウェブサイトが一時閉鎖に追い込まれた時期もあった。そうした困難を経て2020年前後には ARCE の支援のもとサイトがリニューアルされるなど、情報基盤の維持にも不断の努力が払われている。
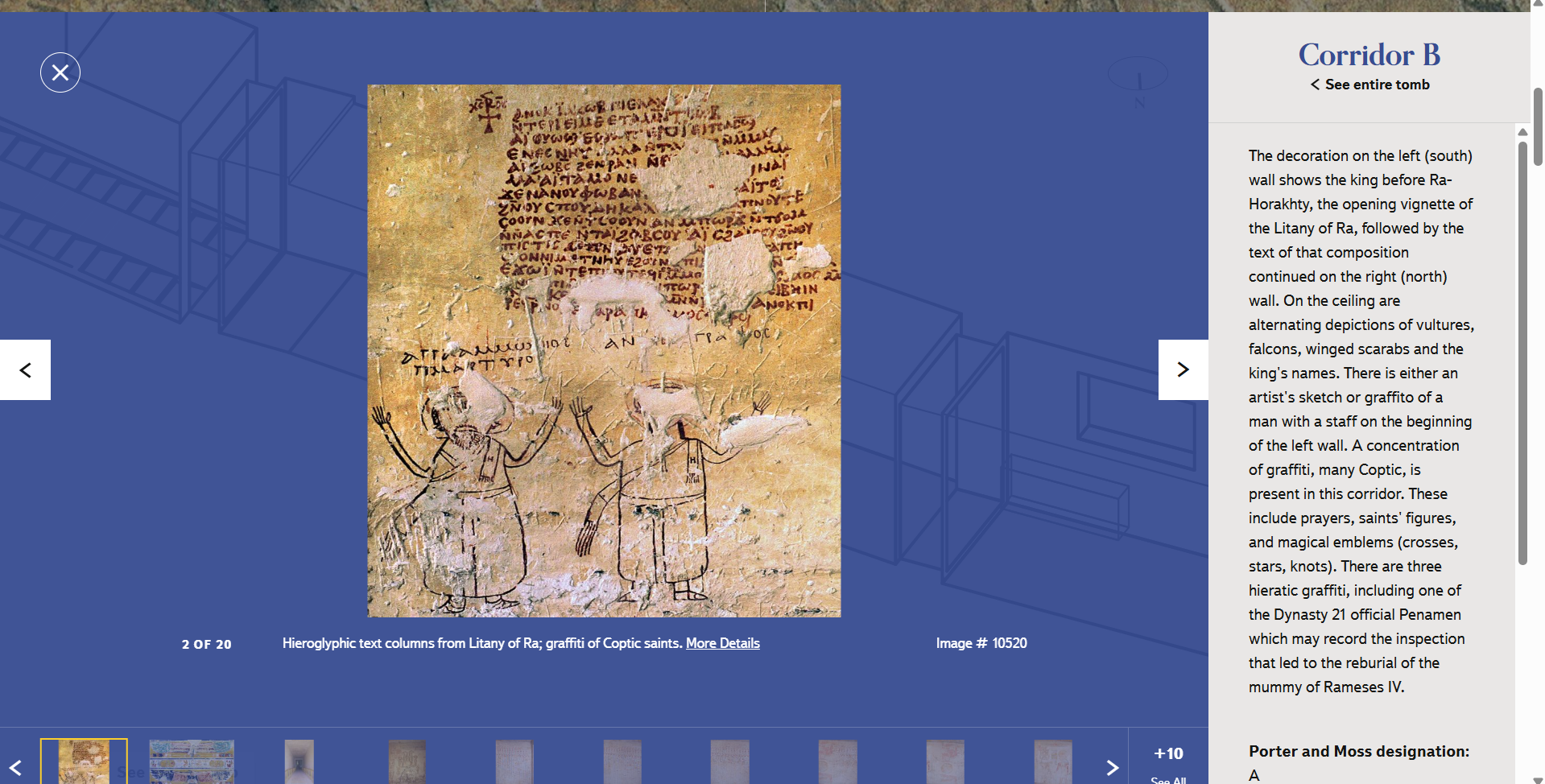
TMP の長い歴史の中で、その技術的手法も飛躍的な進化を遂げた。創始当初は紙の図面や写真による記録が中心であったが、やがてコンピュータ技術の発展に伴ってデジタルデータの活用が進んだ。測量データや遺構の図面はデジタル化され、GIS(地理情報システム)を用いて地図上に統合された。さらにレーザー測量など三次元計測技術を導入することで墓内部の構造まで正確に記録し、取得した点群データ等から墓所の詳細な3D モデルを作成することも可能となった。こうして構築された3次元の仮想空間は、単に視覚的な復元にとどまらず、膨大な情報を統合するプラットフォームとして機能している。たとえば各墓の3D モデル (図2)とともに、壁画や遺物の写真、高精細な平面図・断面図、発掘の経緯や古代・近代の歴史に関する説明(図3)、さらには関連する文献情報や年表、用語解説といった多様なデータが紐づけられている。これにより利用者は仮想空間内で遺跡の空間構造を直観的に把握しつつ、必要な情報に容易にアクセスできるのである。

TMP が残した成果は、考古学および文化遺産の分野において計り知れない価値を持つ。詳細かつ信頼性の高いテーベ遺跡群の地図およびデータベースが整備されたことで、遺跡の保存管理計画や観光客の動線計画などに科学的根拠を与えることが可能となった。従来、個別に発掘・記録され断片化しがちだった遺跡情報が統合されたことにより、研究者はテーベ全体を俯瞰した考察を行えるようになった。また、KV5の大発見により新王国時代の王族埋葬習慣に関する理解が飛躍的に深まったことも重要である。TMP は多数の出版物や報告書を通じて学術的貢献を果たす一方、一般向けのガイドブックや展示、現地コミュニティ向けの図書館開設など教育・普及活動面でも積極的に寄与している。
こうした成功の裏で、TMP はこれまでに様々な課題に直面してきた。広大な調査範囲は長期計画と継続的資金を要し、数十年間の技術変遷は既存データの互換性維持と更新に課題をもたらした。デジタル・アーカイブの長期保存には適切なインフラと予算が不可欠であり、遺跡自体の物理的保全措置も並行して必要とされた。TMP はこれらの困難を関係機関との協力と新技術導入によって克服し続けた。TMP の経験は、文化遺産研究とデジタル・ヒューマニティーズの未来を考える上で示唆に富む。第一に、大規模かつ包括的な遺跡データベースを構築し公開することは、遺跡保護と学術研究の双方に極めて有益であることが示された。今後、他の遺跡や地域にも TMP のような包括的アーカイビング・プロジェクトが拡大すれば、世界規模で文化遺産情報を共有し統合するプラットフォームが構築され、地域横断的な研究やグローバルな保存戦略が促進されるだろう。第二に、GIS(地理情報システム)の上に、人工衛星を使用したリモート・センシングや、フォトグラメトリを用いた3D モデリングなどの先端技術を活用すること、遺跡の現状を詳細に記録するだけでなく、過去の復元や変遷の分析、さらには将来の劣化予測や保全計画の策定にも役立つ可能性を持つ。例えば VR(仮想現実)技術と組み合わせれば、遠隔地から遺跡を仮想見学したり、発掘当時の状況を再現して研究者が検証したりといった応用も期待できる。AI を用いたデータ処理は、膨大な記録の中からパターンを見出し、新たな知見を引き出す助けとなる可能性がある。
最後に、このようなデジタル時代の文化遺産研究を持続させるには、長期的視野に立った戦略が求められる。技術やシステムの老朽化に備えたデータの移行計画、安定した資金源の確保、国際的な協力体制の構築が不可欠である。デジタル・ヒューマニティーズのプロジェクトは往々にして膨大なリソースを要するため、その成果を次世代に引き継ぎ発展させていく枠組みづくりが課題となる。
《連載》「英米文学と DH」第5回
「書籍データのリストの作成方法」
書籍データのリスト
前回の連載で、ハティトラスト・リサーチセンター(以下 HTRC)で扱われるデータはどのようなデータか、また書籍データをどのように入手するかについて示した[1]。HTRC では、各書籍データは Volume ID もしくは htid とよばれる固有の ID で管理され、ページごとに OCR で自動的に読み取られたテクストデータのファイルに分けられている。この書籍データは Volume ID などを指定することで HTRC Workset Toolkit を用いてダウンロードできることを述べた。今回は、こうした Volume ID からなる、分析に必要な書籍データのリストをどのように入手するかについて述べる。この書籍データのリストは HTRC ではデータセットと呼ばれているが、便宜上本稿では書籍データをダウンロードするための Volume ID の一覧が含まれたデータセットを書籍データのリストと呼ぶ。
書籍データのリストの種類
書籍データのリストを作成するには、三種類の方法がある。ハティトラストが所有する全ての書籍データのリストを利用する方法、あらかじめ選別された一部の書籍データのリストを利用する方法、自分で書籍を選別する方法である。
全ての書籍データのリストを利用する方法
全ての書籍データのリストとしては、HTRC の抽出された特徴データセット(HTRC Extracted Features Dataset)がある[2]。これはハティトラストの書籍データから作成された派生データセットの一つで[3]、各書籍データのページごとのトークン数などの情報を含む大規模なデータセットである。Volume ID(“htid”)を含むファイル記述セクション、書名、出版年、ジャンルなどの情報を含むメタデータセクション、ページごとのトークン数などの情報を含む特徴セクションなどに分かれている。ジャンルの情報を用いて分析対象の書籍データを抽出し、Volume ID を入手できるだろう。ハティトラスト・デジタルライブラリーにも全ての書籍データのリストがあるが[4]、こちらはジャンルなどの情報は含まれていない。
あらかじめ選別された一部の書籍データのリストを利用する方法
抽出された特徴データセットは膨大なサイズであるため、別の研究者が作成したあらかじめ選別された書籍データのリストを利用することができる。様々な研究者や利用者が書籍データのリストを作成しているが、目的を限定して研究目的で作成されたデータセットやワークセットを、書籍データのリストとして利用することができる。例えば、BookNLP という文学テクスト分析ツールを通した英語の小説のデータセット[5]やそこからジェンダーのバランスや再版数などに限定して抽出したサブセット[6]、英語の文学作品の地理情報を集めたデータセットなどがある[7]。英米文学研究者には、英語の文学作品のみからなる、年代別かつ小説・詩・演劇の区分ごとの書籍データのリストもある[8]。利用方法として、例えば19世紀の小説の Volume ID を抜き出して書籍データのリストを作成したければ、小説のメタデータファイル("fiction_metadata.csv")を読み込み、出版年が19世紀のデータを選び、Volume ID を示す htid 列を抜き出してファイルにするとよい。
自分で書籍を選別する方法
最後に、自分で必要な書籍を選別する方法である。これにはハティトラスト・デジタルライブラリーのマイコレクション機能を利用する[9][10]。マイコレクション機能とは、検索結果や必要な書籍のリンクを保存するブックマークのような機能である。ハティトラスト・デジタルライブラリーのウェブサイトで右上のログインを押し、ゲストとしてログインを選択する(下の”See options to log in as a guest”の文字)と、Google のアカウントなどでログインできる。ログインしたら、右上の丸いボタンからマイコレクション画面に移ることができる。この画面で新しいマイコレクションを作成できる。また書籍をマイコレクションに追加するには、書籍を検索した後(例としてキーワードを”Amelia Opie”、フィールドを著者として検索する)、検索結果の画面に出たチェックボックスを利用して追加する。チェックボックスが出ないことがあるが、その場合個々の書籍の画面からコレクションの文字を押すとマイコレクションに追加できる。
作成したマイコレクションは、マイコレクションのリンクを介してHTRCでインポートすることができる。図1のようにハティトラスト・デジタルライブラリーのマイコレクションの画面でマイコレクションの一つを選択すると、左上にシェアの文字が出る。このシェアを開くとマイコレクションのリンクが表示されるため、コピーする。
次に、HTRC のウェブサイトを開きログインする。HTRCでは、上部バーのデータから、ワークセットの作成(“Create a workset”)を選び、出てきた画面でハティトラストからのインポート(”Import from HathiTrust”)を選ぶ(図2)[11]。
最後に、HathiTrust Collection URL の項目に、コピーしたマイコレクションの URL を張り付け Fetch Collection の文字を押してマイコレクションのデータをダウンロードした後、必要事項を記載して作成ボタンを押すと書籍データのリストを含んだワークセットができる。作成したワークセットはワークセット確認画面(“View worksets”)で確認、ダウンロードができる(図3)[12]。
ワークセットのファイルは簡易な csv ファイルであり、Volume ID、タイトル、出版年、言語、著者などの項目からなる。Volume ID の列のみを抜き出すとよい。
リストを用いた書籍データのダウンロード
Volume ID のみを含んだファイルを HTRC のデータカプセルにアップロードし、HTRC Workset Toolkit のツールを用いてダウンロードができる(“htrc download [ファイル名]”などのコマンド)。
今回までで、データカプセルを用いて書籍データをダウンロードし分析の準備を整えるところまでを紹介した。次回は用意した書籍データを用いて分析する方法について紹介したい。
人文情報学イベント関連カレンダー
【2025年6月】
-
2025-5-31(Sat) ~ 2025-6-1(Sun)
情報知識学会第33回(2025年度)年次大会https://www.jsik.jp/?2025program
於・筑波大学筑波キャンパス中地区 -
2025-6-3(Tue)
DH 国際シンポジウム「デジタル画像とテキストの新展開:自動文字読み取りの最新動向とその利活用」https://sites.google.com/view/dhsympo2025b/?pli=1
於・慶應義塾大学三田キャンパス -
2025-6-3(Tue), 12 (Thu), 17 (Tue), 26 (Thu)
TEI 研究会於・オンライン -
2025-6-6(Fri)
DH 研究会「即時オープンアクセス義務化方針とクリエイティブ・コモンズ・ライセンス」https://dh.nihu.jp/news/post/20250508
於・オンライン -
2025-6-7(Sat)
文学研究とプラットフォームキックオフシンポジウムhttps://sites.google.com/view/literaryanalysisandplatform202/
於・中央大学市ヶ谷田町キャンパス -
2025-6-13(Fri)
DH 国際ワークショップ「仏典の AI 自動翻訳の最先端:専用 LLM の開発とそれを巡る人文学研究者のキャリア形成」https://sites.google.com/view/dhws2025b/
於・慶應義塾大学三田キャンパス -
2025-6-26(Thu)
青空 TEI 研究会於・オンライン
【2025年7月】
-
2025-7-1 (Tue), 10 (Thu), 15 (Tue), 24 (Thu), 29 (Tue)
TEI 研究会於・オンライン -
2025-7-14 (Mon) ~ 2025-7-18 (Fri)
DH2025: Accessibility & Citizenship於・Universidade NOVA de Lisboa -
2025-7-20 (Sun) ~ 2025-7-22 (Tue)
DHEAC: Annual International conference on digital humanities for East Asia Classics於・Beijing Library
【2025年8月】
-
2025-8-7 (Thu), 12 (Tue), 21 (Thu), 26 (Tue)
TEI 研究会於・オンライン -
2025-8-3 (Sun)
第139回人文科学とコンピュータ研究発表会https://www.ipsj.or.jp/kenkyukai/event/ch139.html
於・シャトレーゼホテル談露館
Digital Humanities Events カレンダー共同編集人
◆編集後記
5月はいよいよ2025年度のイベントが盛り上がってきました。各地で色々な学会や研究集会などが開催され、デジタル・ヒューマニティーズ(DH)でも17日の慶應大学三田キャンパスでの情報処理学会人文科学とコンピュータ研究会(CH研究会)や24~25日の東京大学本郷キャンパス5月祭でのデジタル人文学フェスなど、若手が活躍するイベントが開催される一方で、駒澤大学では24日に「仏教学におけるデジタルツール・工具書利用の現状と展望」というワークショップも、やはり若手中心で開催され盛り上がりました。筆者は参加できなくて大変残念でしたが、同じ24日東京国立博物館では「月例講演会「文化財デジタルデータの活用展開」」が開催されていました。また、人工知能学会でも「デジタル人文学と AI」というセッションが行なわれたり「日本古典文化と生成 AI」というチュートリアルが開催されるなど、盛況だったようです。他にもいくつかあったようです。
なかでも一つだけ振り返ってみますと、毎年5月の CH 研究会では「学生セッション」と名付けられた、1分程度のショート発表とそれに続くポスター発表会が開催され、その中から「優秀な研究発表を行った学生を表彰する機会を設けることにより、次世代を担う研究者の研究を奨励し、人文科学分野へのコンピュータの応用に関する研究の発展を促すことを目的」として「奨励賞」が選定されます。学際的な研究分野では議論や関心の方向性が多様すぎて蛸壺化してしまい研究上のコミュニケーションが薄くなってしまうことがありますが、近年の CH 研究会を見ていると、この学生セッションに中堅以上の多くの研究者が採点者として参加することにより、縁の薄い分野の研究に対しても積極的に関心を向ける機会が提供され、それを通じて異分野交流がより促進されているように思えます。10年以上続けてきた結果とも言えるかもしれませんが、なかなか興味深いものがあります。今回も学生セッションは10件の発表が集まり、そこここで活発な議論が展開され、大変盛況でした。今回筆者は開催校として協力しましたが、議論に参加してくださった方々のおかげで、ここから研究者として飛躍するきっかけをつかんでくれる人たちが出てくれるかもしれないという期待をさせてくれるような、良い研究会になったと思います。
6月もイベントは盛りだくさんですが、筆者が開催に関わるものとしては、6月3日のDH国際シンポジウム「デジタル画像とテキストの新展開:自動文字読み取りの最新動向とその利活用」と、6月13日の DH 国際ワークショップ「仏典の AI 自動翻訳の最先端:専用 LLM の開発とそれを巡る人文学研究者のキャリア形成」が開催されます。
6月3日(火)は、国立国会図書館古典籍 OCR を開発しておられる青池亨氏と、パリ PSL 研究大学で手書き文字認識ソフトウェア開発プロジェクトの共同リーダーの Peter Stokes 氏をお招きして、デジタル画像とテキストの新しい展開について検討する会です。会場は慶應大学三田キャンパスで、参加費無料・同時通訳付き・ハイブリッド開催で、こちらから申込みできます。
6月13日(金)は、仏典機械翻訳の LLM の開発をしているプロジェクト Dharmamitra の Sebastian Nehrdich 氏による、慶應大学三田キャンパスでのワークショップです。仏典機械翻訳のための便利なツールの使い方だけでなく、「人文系の人が LLM を開発するとどこまでいけるのか」といったことに加えて、仏教学から LLM の開発に入っていった Nehrdich 氏のキャリアについてのお話しもおうかがいできる貴重な機会となりそうです。会場は慶應大学三田キャンパスで、参加費無料・同時通訳付き・ハイブリッド開催で、こちらから申込みできます。
これ以外にも、興味深いイベントが目白押しで、6月6日にはオンラインでの「即時オープンアクセス義務化方針とクリエイティブ・コモンズ・ライセンス」(https://dh.nihu.jp/news/post/20250508) については、内閣府が強力に推進するこの方針(https://www8.cao.go.jp/cstp/oa_240216.pdf)が、人文学においてどう適用され得るのか、という観点から大変気になるイベントです。6月7日に中央大学にて開催される「文学研究とプラットフォームキックオフシンポジウム」(https://sites.google.com/view/literaryanalysisandplatform202/) は、本メルマガに連載を寄稿してくださっている橋本健広氏が開催に関わっておられ、いよいよ日本の英文学研究がデジタルに踏み込んでいくことになる大きなきっかけとなりそうなイベントで、本メルマガに長期連載をしてくださっている宮川創氏も登壇されるようです。また、文字コードを扱う ISO の国際会議が新潟で、言語コードや辞書、翻訳などを扱う ISO の国際会議が高松で開催されるのも今月のようです。まさにイベント目白押しですが、これがうまく人文学の現場にも還元されていくようになることを期待するところです。
- コメントを投稿するにはログインしてください